【2.2】序列比对算法介绍
一、序列比对基本概念
因为通过比对,我们可以通过相似的序列获得相似的结构,从而预测其功能,我们可以确定其进化位置,找到共同的祖先。但这是如何实现的呢?
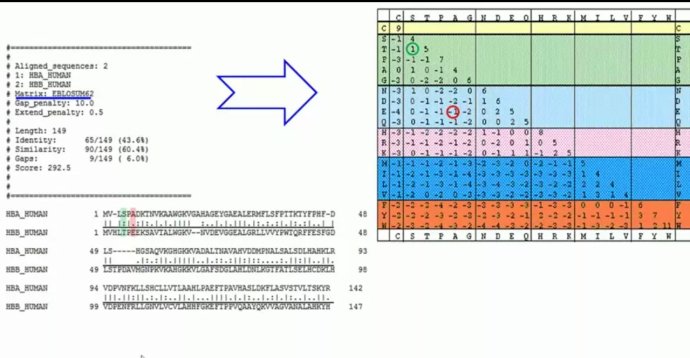
上图是选择的两段序列比对的结果(比对的软件我就不说了,实在是太多了,我这里用推荐一下高歌课堂上用的网页,算是一个推广把 www.ebi.ac.uk/Tools/psa/)。注意一下:
1.|表示完全匹配,:表示比较匹配,.表示不太匹配
2.scoring marix的两个特点 content-insentive(上下文无关) ;symmetric(对称的)
3.空位罚分 indel=insertion 或deletion
penalty=d+(n-1)e d为第一个空位罚分,e为延伸空位罚分
比对的方法的方法有很多:
点阵法(Dot matrix)
动态规划(全局比句,局部比对)
隐马尔可夫
启发式比对 –k-tuple(blast fasta)
我们是想通过枚举法来结局问题,两段序列一个个的比对,但是比对的数据是很吓人的,如下图所示

现在的比对的方法源于动态规划的思想
一对残基比对的结果只有3种情况,A比上B,A比上空格,B比上空格,这对残基比对的最优结果,我们加上前面的最优比对结果,最后我们整个的比对结果就是最佳的,这就是动态规划,一步一步找最优的结果

为了更好的理解这个动态规划的过程,我们可以把比对的结果放在一个含有X,Y的矩阵下面

二、 先来说一下needleman-Wunsch的全局比对的思路
所谓的全局比对,就是从第一个到最后一个,一个个的比,一条序列都比个遍,然后得出最后最优的解 举个例子吧:

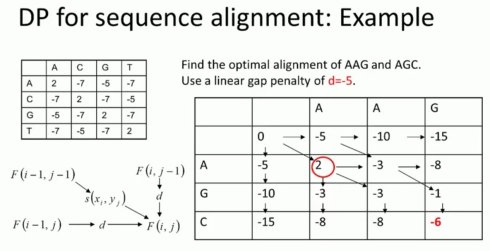
上面例子中空位罚分的d,e值我们都设为的是-5。我浅谈一下我对上面矩阵的理解:
- 因为是对称的,所以看斜对角线;
- 因为F(i,j)来自F(i-1,j-1),F(i,j-1),F(i-1,j),而写入矩阵的数是这三种来源的数的最大值,所以得出上面的那个表,同时得到的数用箭头表明它来自于上一级的那一个数;
- 根据最后得出来的最优解,我们回溯就能找到源头,然后就写出了比对的结果。
三、smith-Waterman局部比对的方法
我们后来发现啊,序列中含有保守区段和内含子的出现,这样全局比对的结果就不能真实准确的反应出连贯序列功能基因上的相似性,因为他算出来的结果并不能反应出序列中某些特殊片段的相似性,而有时候往往这些特殊片段的相似性则反应了两端序列功能的相似。
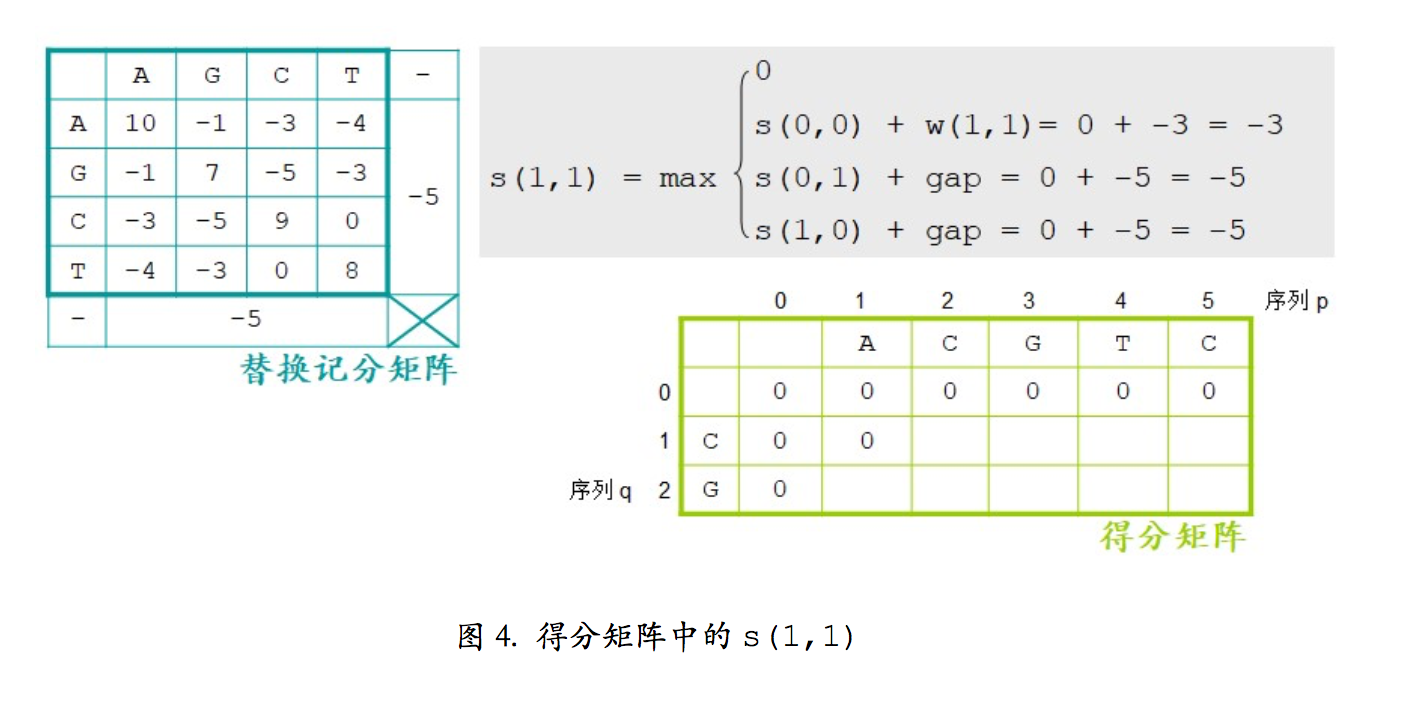

发现没,局部比对的方法其实就只是在全局比对的算法上面加了一个O,就这么一点点改变,那有什么影响呢,让我们接着上面的那个例子来看:

小伙伴们,有什么发现木有?这个的本质就是在F(i,j)的来源多了一个0,最后的结果就不像之前那样最后所有的残基都能比对上,这个比对的结果就只有一个小片段,之前的迭加路径被终止了,最后的结果有局部最优比对,和局部次优比对
四、我们上面到的例子总d,e值都是一样的,如果不一样呢
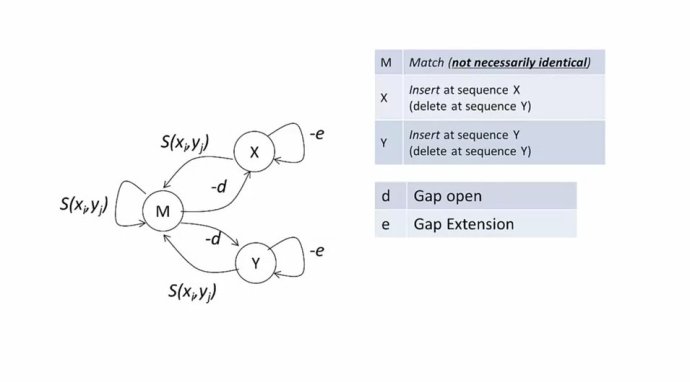
3中状态,序列比对描述为计算机中不同状态的转移?

参考资料:
北大高歌的生物信息学课件
山东大学 生物信息学课题组荣誉出品 http://www.crc.sdu.edu.cn/bioinfo 巩晶老师课件
