【4.2.3】SURPASS

粗粒生物分子建模(Coarse-grained modeling)在分子生物学中具有非常重要的作用。在这项工作中,我们提出了一种新颖的蛋白质 SURPASS (每个预先平均的二级结构片段具有单个联合残基,Single United Residue per Pre-Averaged Secondary Structure fragment)模型,可以作为现有粗粒度模型的有趣替代品。该模型的设计是独特的,并得到蛋白质系统结构规律特征的统计分析的大力支持。蛋白质链结构的粗粒度假定每个残基的相互作用中心为一个,并且说明了四个相邻残基片段的预平均效应。基于知识的统计潜能编码这些片段的复杂交互模式。使用仿制交换蒙特卡洛采样方案和SURPASS力场的通用版本,我们对一组典型的单域球状蛋白进行了测试模拟。该方法对构象空间的重要部分进行采样,并以惊人的良好准确性复制包括天然样在内的蛋白质结构。简要讨论了SURPASS模型在大型生物大分子系统上的未来扩展。
注解:什么叫CG ?
生物科学中尚未解决的主要问题之一是研究生物系统的计算方法和实验方法之间的时间尺度和长度尺度差距。原子级的化学和机械过程构成了生命系统中所有现象的基础。对这种动态过程的实验性非侵入性观察将极大地有助于理解生活的工作方式;但是,通常实验技术在时间上无法获得比ms-&mus更好的分辨率。另一方面,存在理论和计算方法,特别是分子建模,该方法能够描述具有所有原子细节的生物系统。但是,到目前为止,这些方法实际上仅限于仿真时间和分别小于100 ns和10 nm的系统尺寸。扩展分子建模并将其与实验技术联系起来的一种可能方法是使用粗粒度:通过减少自由度(与全原子描述相比)来表示系统。由于自由度的降低和精细交互细节的消除,在全原子表示中,与相同系统相比,粗粒度(CG)系统的仿真所需资源更少,并且运行速度更快。结果,可以实现模拟的时间和长度范围内数量级的增加。
一、前言
分子建模在蛋白质结构,动力学和相互作用的研究中非常重要。经典分子动力学(MD)模拟在结构生物学,合理药物设计和其他生命科学领域中通常使用,尽管它们的适用范围很广受时间限制和生物大分子过程的复杂性限制。理论分子生物学的“多孔机制”(holey grail” )是预测蛋白质的三维天然结构及其基于氨基酸序列的组装机制。现在,使用MD专用超级计算机可以模拟整个小而快速折叠的蛋白质的折叠途径。较大蛋白质的组装,与其他生物大分子的结合,蛋白质聚集和许多其他生物学现象的时间尺度通常要长几个数量级。这就是粗粒度(CG)建模方法越来越重要的原因。一些最成功的CG模型针对结构预测,并与适当的生物信息学工具(如Rosetta或I-Tasser)结合使用,他们可能非常有效。其他模型更通用,不仅可以进行结构预测,还可以进行蛋白质动力学研究。这种中等分辨率的CG模型的典型示例是 UNRES 或 CABS 。在此类CG模型中,一个氨基酸残基通常被2、3或4个联合原子取代,代表形成真实结构的大量原子。与全原子模拟相比,这种级别的粗粒度提供了大约3个数量级的计算速度提升,仍然允许在模拟轨迹的选定点处对原子细节进行逼真的重建。这样可以实现建立相当有效的多尺度建模策略。
中分辨率CG模型大大扩展了分子建模的时间范围和系统规模;然而,正如在连续的CASP(蛋白质结构预测方法的关键评估)实验中观察到的那样,它们与大型结构的从头建模(无同源模板)进行了斗争。随着蛋白质结构的大小和拓扑复杂性的增加,蛋白质折叠模拟所需的时间尺度只是迅速增长。另一方面,当从模板衍生的甚至是非常不准确的初始模型开始时,但通常具有正确的拓扑结构时,CG方法通常会产生最终模型的良好分辨率。对蛋白质复合物及其与其他生物大分子的相互作用进行建模的要求更高。 因此,要扩展蛋白质结构和动力学的从头建模的范围,需要一种有效的工具来非常快速地模拟低分辨率结构。这是诸如SURPASS(此处提出的每个预先平均的二级结构片段的单个联合残基)作为多尺度分子建模方案的一部分可能非常有用。在这样的方案中,SURPASS模拟可以提供类似蛋白质的低分辨率起始结构的集合,并且例如可以用作中分辨率CG模型(例如CABS)的副本交换模拟的输入。最终可以对中分辨率结构进行全原子重构和MD细化/刻痕模拟。粗粒结构的有效重构和细化可以大大受益于蛋白质结构规则特性的丰富知识。最近探索了基于这两个分辨率级别的几种多尺度策略。
SURPASS是低分辨率模型。 具有类似分辨率的模型尽管计算上更昂贵,但已被证明在蛋白质结构和近乎自然动力学的研究中具有很高的生产力。SURPASS模型的低分辨率使其不适合作为结构预测的基本工具。 但是,该模型可以提供大量的低分辨率蛋白质样结构,可以用作更精确方法的起始集。 由于SURPASS的计算效率高,因此可以用于对蛋白质系统中的长期动力学和大规模结构转变进行建模,这些动力学和大规模结构转变远大于高分辨率的粗粒度建模工具所能处理的动力学转变和动力学转变。(5)
本文的其余部分安排如下。在“方法”部分中,我们介绍了蛋白质链的粗粒度SURPASS表示形式,然后讨论了基于知识的力场,最后讨论了模拟中使用的采样方案。力场的描述分为两个基本部分。第一个描述了可以应用于多种蛋白质系统的力场的通用部分。它由增强规则二级结构的电势,其他短程(沿序列)相互作用,氢键模型以及控制伪残基局部堆积的电势组成。可以在我们的主页上找到此最小力场的完整参数集:http://biocomp.chem.uw.edu.pl/tools/surpass 。力场描述的第二部分介绍了一个简单的补丁,用于模拟单域球状蛋白。结果与讨论部分描述了各种大小的一小套但代表性的球蛋白的蒙特卡罗模拟。结论中总结了SURPASS模型的主要结论和预期的未来应用。
二、方法
2.1蛋白质结构的表示
SURPASS是一种低分辨率的蛋白质结构深层粗粒度模型。代表蛋白质结构的假残基数量与蛋白质大小相对应,等于N – 3,其中N是氨基酸序列的长度。 SURPASS表示的概念在图1中进行了解释。模型背后的主要思想是基于多肽链局部几何结构的独特概括。即,通过对沿着链的四个连续的α碳的坐标取平均来定义假残基的位置。这些四个残基的片段被一个单一的相互作用中心所取代。由于单个残基的移码,模型化链中的每个α-碳(链端除外)都有助于定义四个连续的SURPASS伪残基。四残差平均的选择对于模型的几何形状至关重要。与其他不同长度的短片段相反,只有四个残基的平均数导致SURPASS片段几乎呈线性,代表了螺旋或β链(见图1)。该模型的特征导致非常简单有效的采样方案。根据SURPASS联合残基之间相互作用的假定定义,可以使用不同的采样策略,包括分子动力学方案,蒙特卡洛方法或各种组合采样方案。

SURPASS表示假设三种类型的伪原子(pseudoatoms),具体取决于建模链平均片段的二级结构分配(或预测):
- 伪原子H(对于螺旋片段)位于原子模型中代表螺旋(HHHH)或几乎螺旋(HHHC,CHHH,EHHH,HHHE)片段的四个连续α-碳的质心
- 代表EEEE,EEEC或CEEE片段的质心的拟原子S(β链片段)
- 代表所有其余二级结构组合(H,E和C)的四个连续α碳的中心质量的假原子C(类似线圈)。
与原始结构相比,SURPASS模型中二级结构的定义导致螺旋和β链均略微缩短(约2.0Å),并且略微压缩环片段。 SURPASS螺旋假原子的连续片段呈笔直,刚性且紧密堆积的棒状,部分重叠的珠代表统一的残基。 β链的联合残基代表更多分离的α-碳的中心。因此,两个连续的S型或C型伪残基之间的距离几乎是螺旋片段中距离的两倍。在这种表示形式中,简单的“球形”蛋白质可视化效果类似于众所周知的“色带图”(见图2)。 SURPASS模型对蛋白质结构的粗粒度表示暗示了设计力场的几个方向。我们选择基于知识的方法和描述联合残基之间相互作用的统计潜力的特定定义。溶剂以隐式方式处理,其影响(水与其他小分子或跨膜蛋白的膜环境)直接包含在描述潜在残基之间相互作用的统计势中。这种策略在其他高分辨率的粗粒蛋白质模型中被证明是非常有效的。

2.2 SURPASS力场的通用术语
设计和推导基于知识的粗粒度模型力场始终是模型性能的关键。在本文中,我们仅描述和测试直接与序列无关的通用术语,而 更为一般的互动模型将在单独的报告中介绍。 在此处显示的极小力场中,序列效果仅通过二级结构分配非直接编码。 首先,我们描述基本的通用术语,这些术语似乎适用于多种蛋白质系统(单域,多域,球状和膜蛋白等)。 在下一部分中,将介绍针对单域球状蛋白的相互作用模型的简单修改或补丁。 我们认为,此处描述的通用力场可在许多应用中使用,并且可由其他研究人员在类似SURPASS或相关的粗粒度模型中轻松实现。
要获得可靠且通用的统计潜力,需要使用从蛋白质数据库(PDB)中适当选择的蛋白质结构子集。 在这项工作中,我们使用了PISCES子集。(30)该数据库包含4600条多肽链,其长度为20至1193个氨基酸残基,它们是各种已知蛋白质结构的代表性和非冗余子集。 PISCES结构的分辨率不低于1.6Å,序列相似度不超过60%。 在支持信息的SI1节中提供了详细的规范。
二级结构模型
由于各种短程相互作用(short-range interactions),在多肽链中沿序列接近的原子之间的距离和角度受到严格限制。强烈简化且预先平均的SURPASS链中原子细节的不足可能会导致结构的局部几何结构不正确。 为了避免这种情况,有必要将原子模型的结构规则性转移到施加在联合原子上的相应限制上。
平面角度限制
SURPASS模型中三个连续的统一原子之间的平面角对应于沿序列的六个全原子残基之间的空间关系。 由于结构碎片的平均,螺旋和β链中第ith,第(i + 1)和第(i + 2)个联合原子之间的角度接近180°,这意味着两种类型的规则结构都是 表示为几乎共线的直杆(见图3)。 二级结构元素沿模型链需要特定的距离限制(请参阅“短程相互作用”部分中的潜在R13)。

短距离互动 Short-Range Interactions
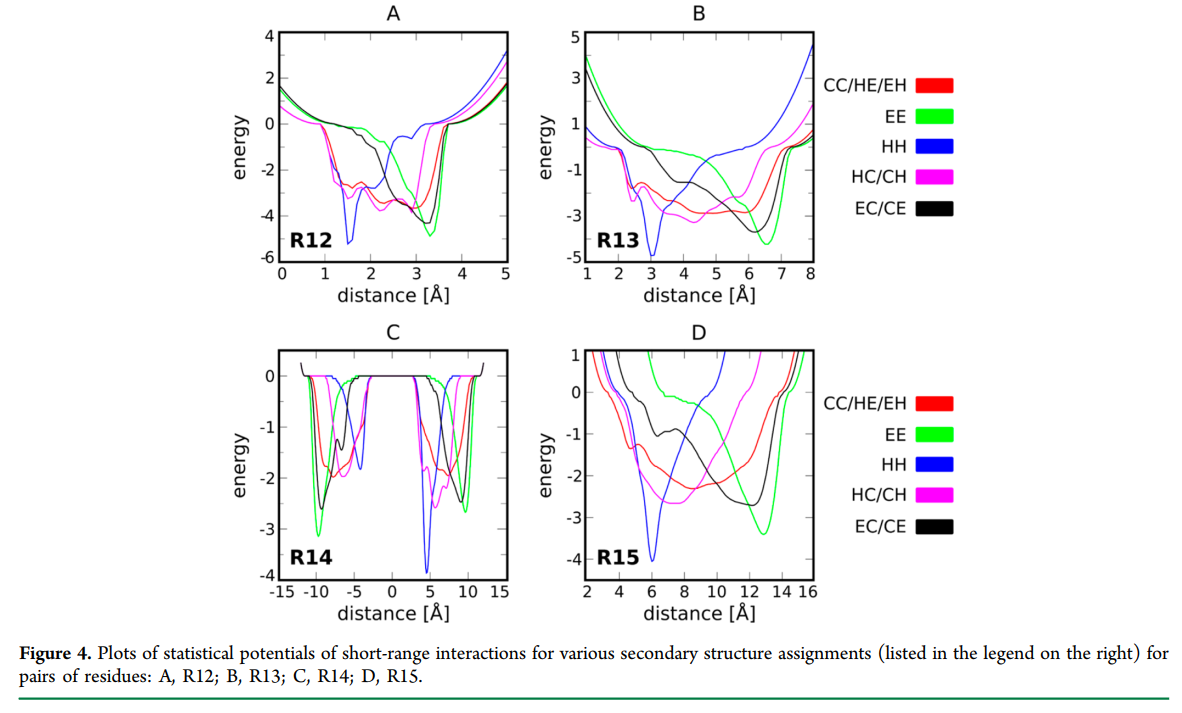
假定二级结构片段的局部几何形状在很大程度上被编码在SURPASS伪原子的距离分布中。这适用于沿链位于n = 1、2、3、4个位置的伪残基。所有通用术语R12,R13,R14和R15都有六种变体形式(HH,EE,CC,HE,HC,EC),具体取决于关键位置上成对残基的二级结构分配(请参见SI2节表1)支持信息)。二级结构分配可以从结构数据库中获取,也可以使用适当的生物信息学工具进行预测。第i个和第(i + 1)个磁珠之间的距离(R12)的分布表明,沿着螺旋的残基的平均密度(1.6Å)比环中的平均密度(2.2Å)高,并且是β链的两倍以上(3.3Å)。电位R13和R14不仅控制联合残基之间的距离,而且控制相应的联合残基之间的平面角和二面角。使用一维核密度估计器(KDE)(33)作为定义经验分布密度的方法,已经在力场中将所有短程相互作用实现为平均场(PMF)(32)的势能。能量函数不仅取决于在观察到的距离d处的KDE值,而且还取决于第一和第二相互作用假残基的二级结构类型的可能性(参见图4)(在本报告中描述的模拟中,值为0或1)被使用)。为避免模型链的非物理拉伸,添加了能量损失,该能量损失随距离的平方增加。数学方程式和能量图显示在表1的第5项中,而各个参数的说明可以在支持信息的SI3部分的表1中找到(请参阅参数编号5.1–5.6)。
参考资料
- http://www.ks.uiuc.edu/Research/CG/
- SURPASS Low-Resolution Coarse-Grained Protein Modeling。 https://pubs.acs.org/doi/10.1021/acs.jctc.7b00642#
