【1.2】高通量测序抗体库的前景和挑战
使用高通量DNA测序技术来确定血液或淋巴器官中B细胞编码的抗体库的工作正在以极快的速度推进,并且正在改变我们对体液免疫反应的理解。从免疫球蛋白基因(Ig-seq)的高通量DNA测序获得的信息可用于高灵敏度检测B细胞恶性肿瘤,发现对目标抗原具有特异性的抗体,指导疫苗开发和了解自身免疫性。实验规程和信息学分析工具开发的快速进展有助于减少测序假象,实现对克隆多样性的更精确定量,并提取最相关的生物学信息。也就是说,Ig-seq的更广泛应用,尤其是在临床环境中,将需要开发标准化的实验设计框架,该框架将允许共享和进行由不同实验室生成的测序数据的meta分析。
一、背景
有效的适应性免疫系统从根本上依赖于B淋巴细胞抗原受体(BCR,B细胞表面表达的抗体的膜结合形式)的多样性。通过大量免疫球蛋白基因区段的体细胞重组来组装BCR(图1),并且在任何给定个体中表达的BCR的组成都是通过暴露于外源抗原和内源宿主因子而不断形成的。现有的BCR多样化机制可产生数量可观的BCR(理论上,人类> 10^13);该数目超过了人体中B淋巴细胞的总数(约1-2×10^11)(参考文献3)。由于劳动力和成本方面的考虑,使用传统的Sanger测序方法分析如此多样化的BCR曲目是完全不切实际的。但是,Ig-seq(由斯坦福大学的Andrew Fire创造的一个术语)使我们能够以前所未有的深度确定抗体基因库。 Ig-seq获得的信息被证明对于了解健康和疾病中的抗体反应以及用于诊断目的非常有价值。此外,Ig-seq可与其他技术结合使用,包括表达和分离抗原特异性抗体,从单个细胞中测序多个RNA4以及血液或分泌物中抗体的蛋白质组学分析,以帮助阐明介导的抗体的特性。预防传染病或介导自身免疫反应。在本综述中,我们描述了与高通量抗体基因测序相关的实验方法和技术挑战,以及可以应用Ig-seq的方式,以增进我们对免疫学的理解并解决与传染病相关的未满足的临床需求,免疫失调和癌症。

(a)IgG结构示意图。在顶部链中,指示了从种系V,D,J和C片段编码的域。未模板的N-核苷酸以红色显示。这些顶链描绘了抗体的5’至3’遗传组成。在底链中,指示了构架(FR)和互补决定区(CDR)。这些底链描述了N端至C端蛋白序列。虚线表示二硫键。 (b)抗体多样化的关键步骤。一抗重链库主要是通过可变(V),多样性(D)和连接(J)基因片段的体细胞重组,以及通过随机非模板化添加N核苷酸而产生的。重链的抗原结合位点由高变互补决定区(CDR-H1,H2和H3)和构架3区(FR3)并置形成。在生产性IgH重排后,随后发生轻链(IgL)重组,H和L链的异二聚体配对形成了在新形成的未成熟B细胞表面表达的IgM同种型的完整抗体。 Eμ:IgM内含子增强剂; Sμ:串联重复对于类开关重组至关重要。括号中的数字是指人类种系VH DH和JH段的估计值。
二、抗体库的产生
抗体是由一系列发育排序的体细胞基因重排事件产生的,这些事件仅发生在发育中的B细胞中,并在生物的整个生命中持续发生。抗体由重链(μ,α,γ,δ,ɛ)和轻链(κ,λ)组成,它们通过二硫键连接。完整的抗体包含可变和恒定结构域(图1a)。抗原结合发生在可变域中,该可变域是由有限组串联排列的变量(V),多样性(D)和连接(J)种系基因片段重组产生的(图1b)。这个过程称为VDJ重组,通常会导致连接的基因片段之间的连接处核苷酸的添加和缺失(图1b)。更具体地说,DNA外切核酸酶可以修饰基因片段的末端,而DNA聚合酶和转移酶可以分别随机插入模板化回文(palindromic )或非模板化核苷酸。
在B细胞发育过程中,免疫球蛋白重(IgH)链基因重组通常发生在免疫球蛋白轻(IgL)链基因重组之前。如果IgH和IgL基因都被有效地重排,则完全组装的抗体异二聚体会在B细胞表面表达。在携带生产性重排抗体的B细胞中,等位基因排斥(在IgL情况下是基因座排斥)的过程可确保每个B细胞表达单一抗体。经过几个发育检查点(developmental checkpoints)后,新生成的成熟IgM + IgD + B细胞形成了幼稚B细胞(因此是幼稚抗体)库。幼稚抗体库中的大多数多样性都集中在IgH VDJ基因片段连接位点,也称为IgH互补决定区3(CDR-H3)(图1b)。由于产生CDR-H3的机制的组合性质和非模板性质,就抗体H链库的长度和序列而言,它是最多样化的成分,并且是抗体特异性的主要决定因素。但是,在某些情况下,抗原特异性仅或主要由L链决定。
- 当B细胞在提供必需的共刺激信号和T细胞帮助的环境中遇到抗原时,BCR刺激会诱导B细胞增殖。这个过程称为B细胞克隆扩增,主要发生在被称为生发中心的次级淋巴器官(例如,脾脏,淋巴结和Peyer斑片)的高度组织化区域中(图2)。
- 克隆扩增后是抗体可变域的体细胞超突变;这是由激活诱导的胞苷脱氨酶介导的。表达带有增加对抗原的亲和力的体细胞突变的BCR的B细胞要胜过其他B细胞获得抗原的竞争。结果,具有最高亲和力抗体的B细胞经历优先扩增和存活,该过程称为亲和力成熟。体细胞超突变还导致CDR-H1和CDR-H2高变区以及构架3(FR3)区的序列多样化,这被提议构成抗体H链的第四个高变区。激活诱导的胞苷脱氨酶也介导类开关重组,从而产生带有不同恒定区的抗体。
- 表达体细胞突变的高抗原亲和性BCR的B细胞可以分化为长寿命的记忆B细胞,能够介导对相同抗原的快速召回反应,也可以分化为终末分化的浆细胞。后者下调BCR的表达,在骨髓,肠道固有层(并在较小的程度上,在次级淋巴组织)中定居,并以每秒10,000-20,000个抗体分子的极高速率分泌保护性抗体。假定骨髓中长寿命的浆细胞产生抗体会持续很长时间,可能会贯穿整个生物体寿命。
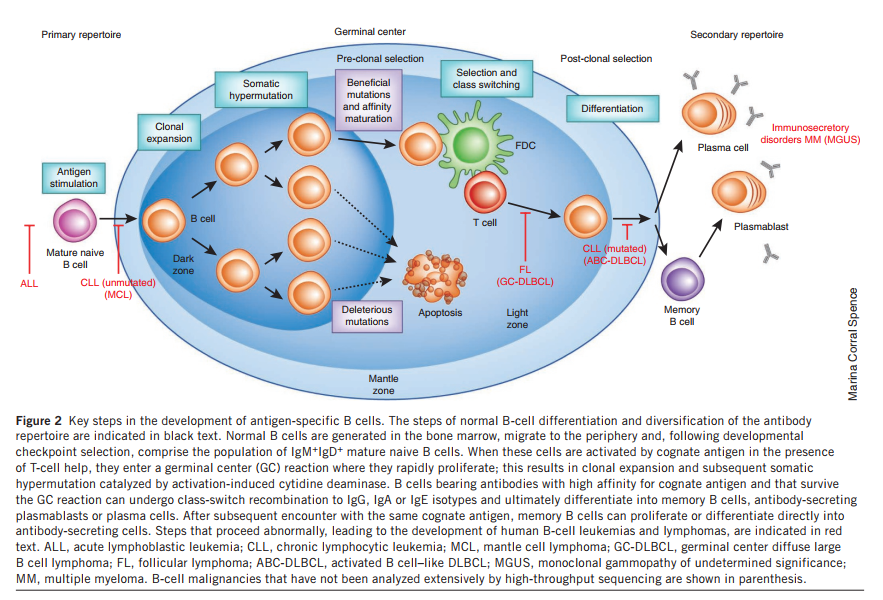
黑色文本指示正常的B细胞分化和抗体库多样化的步骤。正常的B细胞在骨髓中产生,迁移到周围,并在选择发育检查点后包含IgM + IgD +成熟的幼稚B细胞。当这些细胞在T细胞帮助下被同源抗原激活时,它们会进入生发中心(GC)反应,并在那里迅速增殖。这导致克隆扩增以及随后的激活诱导的胞苷脱氨酶催化的体细胞超突变。携带对同源抗原具有高亲和力且在GC反应中存活的抗体的B细胞可以经历类转换重组为IgG,IgA或IgE同种型,并最终分化为记忆B细胞,分泌抗体的浆母细胞或浆细胞。在随后遇到相同的同源抗原之后,记忆B细胞可以增殖或直接分化为分泌抗体的细胞。红色文本表示异常进行的步骤,这些步骤导致人类B细胞白血病和淋巴瘤的发生。 ALL,急性淋巴细胞白血病; CLL,慢性淋巴细胞性白血病; MCL,套细胞淋巴瘤; GC-DLBCL,生发中心弥漫性大B细胞淋巴瘤; FL,滤泡性淋巴瘤; ABC-DLBCL,活化的B细胞样DLBCL; MGUS,意义不明的单克隆丙种球蛋白病; MM,多发性骨髓瘤。括号中显示了尚未通过高通量测序进行广泛分析的B细胞恶性肿瘤。
抗库中的多样性(在外源性抗原暴露之前)源自免疫球蛋白基因区段中的等位基因多样性,体细胞重组过程中引入的组合多样性,重组过程不精确导致的连接多样性,IgH和IgL多肽链的配对以及受体编辑,其中现有的V基因段被替换为另一个(图1)。此外,VH置换是FR3中存在隐秘重组信号序列的结果,可能会影响多达5-12%的人类原代B细胞抗体库。抗原刺激后二级抗体库的多样化源自体细胞超突变和类别转换重组。
生物体年龄也影响抗体库[13,14]。在早期个体发育中,哺乳动物成年B细胞库以可预测的发育程序方式生成,而在高龄时,体液免疫反应性恶化。这种现象被称为免疫衰老,被认为部分归因于抗体库的逐步限制。例如,在老年人中,自身抗体的患病率增加,而在血清学水平上,一种或多种浆细胞的良性生长以高水平产生的一种或少量血清免疫球蛋白的量增加克隆。
三、抗体库的低通量分析
在1990年代,Sanger测序技术能够确定每个实验中多达数百个B细胞中的IgH和IgL VDJ重组体(以下简称V基因)。随后的研究开始在有限稀释后从单个B细胞克隆免疫球蛋白基因,并表达并在功能上表征克隆的抗体蛋白,从而能够研究抗体的特异性。事实证明,这一进展对于分离与疾病相关的抗体,尤其是分离中和病原体的抗体具有不可估量的价值。 B细胞永生化(immortalization )(以及永生化B克隆中V基因的后续测序)为表达少量抗体提供了另一种途径。
询问由少量B细胞编码的抗体的能力已产生了许多重要的免疫学见解。例如,Wardemann等人[24]首先使用单细胞克隆和抗体表达来证明人骨髓中一部分新生成的B细胞表达自身和多反应性抗体,并且它们的发育受两个独立的自我耐受性调节检查点。我们实验室和其他实验室的后续研究阐明了与自身免疫性疾病或免疫缺陷综合症相关的抗体的机制和特征。 B细胞克隆技术还能够分离能够中和众多临床重要病原体的抗体,这些病原体包括严重,急性,呼吸系统综合症冠状病毒(SARS-CoV),流感和HIV-1等。反过来,了解导致中和抗体的机制,有助于研究人员设计更有效的疫苗。但是,低通量B细胞克隆研究的一个关键局限性在于,它们仅提供了完整抗体库中微小片段的一瞥。
四、抗体库的高通量测序
与Sanger测序相比,Ig-seq可以提供更广泛的抗体库图(图3a)。 尽管从概念上讲很简单,但为了正确应用,Ig-seq需要仔细考虑实验设计,对DNA序列的来源和定量错误的详细理解,描绘每个单个B细胞中哪些VH基因与哪些VL基因配对的能力 ,并使用适当的数据挖掘和可视化工具对此类实验中产生的大量信息进行生物学意义上的了解。

 (a)根据指定的细胞表面标志物的表达进行分类的,来自B细胞亚群的大量B细胞群体中Ig基因高通量测序的步骤示意图。基因组DNA(gDNA)或mRNA均可用作模板,模板的选择会影响用于后续PCR扩增的引物的数量和位置。使用与重排的V区基因(VDJ重组体)互补的引物进行gDNA扩增; cDNA的扩增可使用与V基因区段的前导肽或FR1s互补的5'引物池和单个3'CH1(如果扩增轻链基因,则为Cκ,Cλ)引物进行,或者通过5'RACE进行。尽管通量很高,但是由于大量裂解细胞,并且在单独的反应中扩增了VH和VL基因,因此在批量分析中丢失了在同一细胞中配对的VH和VL链的信息。 (b)保留内源性VH:VL对信息的单细胞免疫球蛋白库测序方法示意图。左图:皮微升孔阵列中的B细胞裂解和mRNA捕获。中图:有限的B细胞稀释和使用条形码引物扩增后的单细胞PCR。右图:VH和VL cDNA的微流体条形码。 Ig,免疫球蛋白。
(a)根据指定的细胞表面标志物的表达进行分类的,来自B细胞亚群的大量B细胞群体中Ig基因高通量测序的步骤示意图。基因组DNA(gDNA)或mRNA均可用作模板,模板的选择会影响用于后续PCR扩增的引物的数量和位置。使用与重排的V区基因(VDJ重组体)互补的引物进行gDNA扩增; cDNA的扩增可使用与V基因区段的前导肽或FR1s互补的5'引物池和单个3'CH1(如果扩增轻链基因,则为Cκ,Cλ)引物进行,或者通过5'RACE进行。尽管通量很高,但是由于大量裂解细胞,并且在单独的反应中扩增了VH和VL基因,因此在批量分析中丢失了在同一细胞中配对的VH和VL链的信息。 (b)保留内源性VH:VL对信息的单细胞免疫球蛋白库测序方法示意图。左图:皮微升孔阵列中的B细胞裂解和mRNA捕获。中图:有限的B细胞稀释和使用条形码引物扩增后的单细胞PCR。右图:VH和VL cDNA的微流体条形码。 Ig,免疫球蛋白。
3.1 实验设计
首先要考虑的是B细胞的来源。大多数人类抗体测序研究都使用了外周血中的B细胞,因为血液是人类中少数可轻易获得的B细胞来源之一(扁桃体是另一种)。但是,据估计人体内1-2×10^11 B细胞中只有2%存在于外周血中,而淋巴结中几乎占28%,脾脏和粘膜表面中占23%,而17%在红色骨髓(髓红med)中。因此,外周B细胞中的抗体库提供了对抗原激发的体液应答的狭窄视图。
其次,重要的是要考虑使用基因组DNA(gDNA)还是mRNA进行免疫球蛋白测序分析(图3a)。是否应该使用gDNA或mRNA取决于提出的问题。测序gDNA有助于估计给定Ig序列的克隆性(换句话说,表达该抗体的B细胞的数量),因为通常读取的序列数量与gDNA模板分子的数量成正比(假设没有引物偏差,如下所述)。另一方面,使用mRNA作为模板可以估算库中各种免疫球蛋白序列的相对表达水平。但是,由于免疫球蛋白的转录在幼稚B细胞和浆细胞之间发生了巨大的变化(最多100倍)(图2),因此,使用来自外周血的未分选的大块B细胞作为mRNA的来源,很难推断出细胞克隆的频率。当使用未分选的外周血单核细胞作为mRNA的来源时,测序数据集中的体细胞超突变程度可被用于区分抗原经历过的B细胞与原始B细胞的V基因转录本。或者,在mRNA分离之前,可以使用细胞表面标记物对感兴趣的B细胞亚群进行分类4。来自不同研究的库之间的比较进一步复杂化,最近的研究[43,44,45,46]揭示了人类IGH基因座中出乎意料的高度多态性。了解遗传变异的程度对于分配VDJ段用途,估计体细胞超突变以及比较个体之间的抗体反应至关重要。
另一个实验设计考虑因素涉及人体中大量的B细胞(仅血液中就有2-4×10^9个B细胞)。需要考虑将抗体库覆盖到足以回答特定生物学问题所需的最小采样深度。显然,测序深度必须大于样品中B细胞的数量(这意味着通过荧光激活细胞分选法枚举B细胞是必不可少的)。此外,所需的测序深度还取决于使PCR和碱基检出错误最小化的方法(请参见下文)。
3.2 区分真实生物学变异中的错误
序列错误有两种来源:一种是由于样品制备(逆转录和PCR)引起的,另一种是DNA测序平台固有的。
相对克隆频率可以从gDNA估计,方法是从同一样品的多个等分试样中制备和测序文库(技术重复)。在这种方法中,每个等分试样都用于生成条形码文库,并对来自不同等分试样的所得文库进行测序。条形码可防止由于一个文库被其他等分试样的DNA污染而造成的伪影。因为只有在每个起始等分试样中都存在相应的克隆B细胞时,才能在多个文库中找到抗体基因,因此该方法可以揭示克隆的扩增[41,47]。但是,使用gDNA作为模板并非没有复杂之处。首先,从gDNA扩增VDJ片段需要使用与所有个体种系V基因片段退火的引物组(图3a)。 gDNA衍生的抗体基因文库的另一个缺点是它们包含有生产性和非生产性的VDJ重排(后者也存在于cDNA文库中,但由于无义RNA的降解而发生的频率要低得多)。最后,gDNA中较低的模板浓度需要更多的PCR循环;这会增加错误频率并进一步混淆量化。
使用mRNA作为起始材料可以进行逆转录扩增,并使用3’引物退火至IgH或IgL的恒定区,进行5’RACE(cDNA末端的5’快速扩增),从而避免了对复杂的V基因特异性的需求引物组(图3a)。如果以mRNA开头,可以使用商业高保真逆转录病毒逆转录酶或热稳定的II组内含子逆转录酶将逆转录酶引入的错误减至最小。
无论使用gDNA还是cDNA作为模板,由于某些DNA模板相对于其他DNA模板(即使在5’RACE中)的差异扩增,碱基错误掺入和模板转换,PCR都会引入扩增伪像。后者是由于两个或多个模板DNA编码的片段的连接而产生嵌合体。通过PCR进行的核苷酸错误掺入通常无法与测序过程中引入的大多数碱基检出错误区分开,但后者通常以较高的频率发生,因此引起了更大的关注。由模板切换产生的嵌合体产生的序列要么不能通过标准VDJ识别算法分配给种系V基因片段,要么被解释为具有人为的非常高的体细胞超突变率。嵌合体的存在使得辨别真正的VH基因置换事件特别具有挑战性。但是,根据定义,基因替换必须涉及与染色体上游VH基因片段的重组(因为下游VH基因片段在初次重组事件中将被删除),这一事实可用于帮助鉴定真正的VH替换事件。通过扩增然后对具有两个或多个不同引物组的同一样品进行测序,然后对各个数据集中相似性进行信息学比较,可以最小化PCR引入的定量偏差。另一种可能的解决方案是使用乳液PCR隔离单个DNA分子以进行扩增。
DNA测序错误的一些并发症最近已被综述53、54、55、56、57,因此在这里,我们仅关注与Ig-seq最相关的问题,以及旨在提高抗体库测序准确性的最新技术进步。测序错误与每个实验中使用的特定DNA测序技术有关,包括错误的碱基分配,插入/缺失(统称为插入/缺失)和不明确的碱基调用。基于焦磷酸测序的技术(Roche 454和IonTorrent)以插入缺失为主导,而染料标记的可逆终止剂技术(Illumina HiSeq和MiSeq)则以取代误差为主导55,58,59,60,61。通过焦磷酸测序方法产生的插入缺失出现在5×10^-3左右的频率,并且可以在计算上获得不同程度的成功。根据最近的分析,碱基取代的频率从0.3%到0.9%不等,具体取决于平台。总体而言,由于Illumina平台具有较低的碱基检出错误率和较低的成本,因此最适合Ig-seq应用。
应当指出,测序错误的重要性取决于抗体库测序实验的目的。例如,如果目标是生成CDR-H3长度分布统计信息或VJ片段使用统计信息,那么测序错误就不再是问题,因为可以使用聚类算法获得有意义的信息,聚类算法将高度同源的序列组合在一起,并最大程度地降低了排序错误。对于其他要求序列准确性的应用,最近开发的许多方法可以帮助减少测序错误。例如,使用环化的V基因DNA可获得高达十倍的更高的测序精度,该DNA使用PacBio平台进行了多次测序。但是,这种准确性带来了更高的成本和更低的吞吐量。各种DNA条形码技术,通过在PCR扩增之前将核苷酸条形码附加到每个DNA模板分子上,也可以提高测序准确性。条形码可对原始库中的DNA模板分子进行更准确的定量(通过计数条形码而不是序列读数),并进行纠错(通过生成具有相同条形码的共有读数)。在最近对Ig-seq进行条形码编码的应用中,Quake实验室在两次技术复制之间的V基因库(对于大于5个读数的序列)中实现了95%的同一性。另一种依靠条形码和对两条链进行测序的方法可以达到很高的准确度(错误率<10^-8),但是会牺牲吞吐量。
3.3 识别内源性VH:VL对
如上所述,直到最近,只有通过限制单个VH和VL基因的稀释和Sanger测序,才能在单细胞克隆后鉴定天然VH:VL对。该过程本质上是低通量,昂贵的(由于使用大量试剂),并且产生的抗体序列非常有限。使用重叠延伸PCR产生用于Sanger测序的单个VH:VL扩增子(与单独的VH和VL cDNA相对),单细胞克隆产量(从约500到2,000 B细胞)适度增加。在Quake实验室的一项研究中,Weinstein等人将约200个小鼠B细胞分选到微孔中,然后使用对目标基因具有特异性的引物(也包含测序接头)在微流控芯片上进行定量RT-PCR,从而实现了抗体重链和轻链基因中多个基因的表达和体细胞超突变的程度。
Wardemann和Georgiou实验室最近开发了对内源性VH:VL对进行测序的其他方法。 Busse等人[75]使用二维条形码引物矩阵将单细胞VH和VL基因扩增与高通量测序结合在一起。这将吞吐量提高到总共50,000个B细胞(图3b)。重要的是,该方法还能够将IgH和Igκ,λ序列轻松克隆到表达载体中,以进一步鉴定抗体。 DeKosky等人[76]开发了一种VH:VL配对技术,该技术依赖于将单个B细胞隔离在纳升以下的容量孔中,裂解细胞,将RNA捕获在poly-dT珠上,并通过乳液重叠延伸PCR(图3b)。据报道,在一项为期一天的实验中,来自7×10^4个激活的记忆B细胞的产量高达6–7×10^3个独特的VH:VL对,其配对准确度已超过96%。该方法适用于检测V基因与感兴趣的转录因子(例如BLIMP1)在抗体分泌细胞中的共表达(B.J. DeKosky,个人交流)。
我们实验室中正在开发的一种更高通量的方法(每个实验中> 2×10^6 B细胞)依赖于可控微滴直径乳液中的细胞包封(一个重要的考虑因素,因为逆转录酶在<5 nl体积的液滴中被抑制)(未发表的数据) )。或者,已使用微流体装置将单细胞与独特条形码条形码的珠粒一起封装在油包水乳液中。经过逆转录酶和PCR后,将来自单个细胞的每个RNA分子有效地加载到唯一的条形码珠上。 PCR产物在Illumina平台上测序,并通过它们共享的条形码正确配对了VH和VL序列(图3c)。鉴于技术进步的迅速步伐,可以预期,在不久的将来,所有抗体库分析都将报告天然配对的VH和VL基因。
3.4 抗体序列的生物信息学分析
有几种已建立的用于VDJ分配和CDR-H3识别的方法(例如IMGT / V-Quest,IgBLAST或iHMMune-align),并且继续开发更快,更精确的算法54、57、78、79。抗体库大小的估算可以通过稀疏分析,最大熵和泊松对数正态分布模型来完成。还存在许多将V基因聚类的方法,这些V基因可能起源于编码未突变抗体前体的单个B细胞的扩增和体细胞超突变。然而,随着测序深度和库多样性的增加,聚类变得特别成问题。同样,对VH进化的推断(即从最初存在于幼稚的主要库中的前体序列如何产生体细胞突变的V基因)也是一个重大挑战。最后,应该指出的是,从事这一领域的研究人员通常使用定制的生物信息学管道。由于缺乏标准化和共享的计算资源,因此很难对在不同实验室中生成的已发布数据进行meta分析。随着领域的成熟,这是一个必须解决的关键问题。迫切需要存放在中央数据库中的可互换数据格式,用于数据分析的经过验证的开源算法以及类似于微阵列实验的最少信息的Ig-seq实验描述标准。
四、抗体库测序的应用 Applications of antibody repertoire sequencing
Ig-seq正在发现广泛的基础和应用免疫学应用
4.1 抗体发现
通过核糖体,噬菌体,细菌或酵母菌展示筛选大型组合文库被广泛用于分离实际上能够结合任何配体的抗体。组合文库通常是通过从哺乳动物中分离的非常大(通常> 10^7个)VH和VL基因组的随机配对而产生的(天然或免疫文库,取决于动物是否被免疫);或者,可以使用合成文库,其中通过诱变CDR使单个或少量VH和VL基因多样化。筛选涉及与抗原结合的连续循环,该过程逐渐将文库的多样性限制为只有极少数具有所需亲和力和特异性的抗体克隆。我们和其他人已将高通量测序用作评估文库中编码的抗体的初始多样性的一种方法,并确定随着抗原结合物的逐渐富集这种多样性如何下降。在文库筛选期间,由于抗原结合克隆的富集超过了起始文库中无关抗体的背景,抗体多样性降低了。但是,某些具有高亲和力的抗体的表达通常会不利地影响编码它们的细胞的生长(注意:亲和力低的抗体同样可能对细胞生长产生不利影响,但显然,这种克隆对图书馆筛选)。结果,在抗体结合的筛选的早期轮次中富集了各个抗体基因,但是由于它们被表达较低质量抗体的生长较快的细胞所竞争,因此它们逐渐被耗尽,从而获得较低的抗体。因此,经过一轮或两轮针对抗原结合的选择后,文库的高通量测序已被用于拯救编码高亲和力抗体的克隆,而这些克隆原本无法被发现。
已经开发了三种利用抗体库测序分析直接从动物或人分离抗体而无需进行文库筛选的方法。首先,在Georgiou实验室的工作中,Reddy等人[94]观察到,在小鼠中,抗原二次免疫7天后,骨髓中CD138 +抗体分泌性B细胞(骨髓浆细胞)编码的抗体库变得高度极化, VH和VL基因最丰富,占所有V基因序列的2–30%。为了发现抗原特异性抗体,Reddy等人[94]根据它们在各个库中的相对等级频率将VH和VL基因配对,从而获得了对抗原具有纳摩尔摩尔亲和力的抗体。随后,Saggy等人显示,在免疫小鼠的脾V基因谱库中以较高频率存在的VH基因编码能够结合免疫抗原的抗体。但是,这些小鼠分析中使用的骨髓或脾脏样品类型很少能从人类获得。
Shapiro,Kwong及其同事率先采用的另一种方法是建立在以下观察基础上:重中和轻链在广泛中和的HIV-1特异性抗体中的共同进化反映在从中收集的VH和VL系统发育树的匹配拓扑中Ig-seq。将各个系统发育树的匹配分支内的VH和VL基因配对,即显示相似的突变积累模式,以产生新颖的广泛中和抗体。该方法对于鉴定具有高体细胞超突变水平(例如由持久性感染引起的抗体)的抗体特别有用,其中可以构建深系统树。
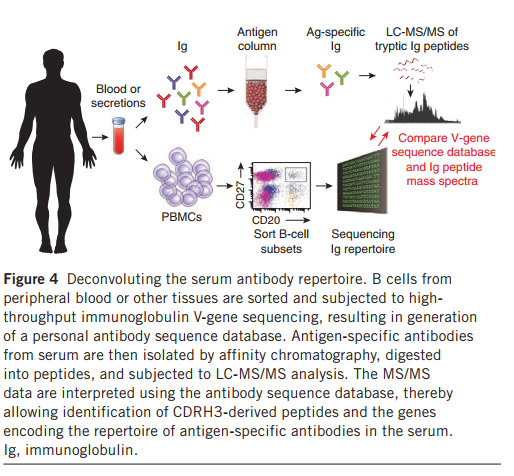
Ig-seq还能够从生物体液中进行蛋白质组学鉴定。尽管B细胞的主要效应子功能是抗体分泌到血液或粘膜和呼吸道上皮中,但这些体液中抗体库的组成仍然难以捉摸。我们和其他人意识到,散弹枪液相色谱-串联质谱(LC-MS / MS)蛋白质组学鉴定包含体液反应的抗体需要通过Ig-seq获得的匹配的个人抗体序列数据库来解释MS / MS光谱(图4)。以这种方式,Polakiewicz和同事[98,99]从免疫动物,接种乙型肝炎的人和巨细胞病毒感染的志愿者中[98,99]鉴定出高亲和力的抗原特异性抗体。在最近的研究中,我们确定了单克隆抗体库,该库包含疫苗接种后兔和人的血清多克隆反应(未发表的数据和参考文献66)。通过蛋白质组学挖掘血清抗体应答发现抗体的出现反过来为从康复期患者中分离生物学相关抗体开辟了道路。发现负责解决患者疾病状态的血清抗体可能与药物发现有很大的关系,因为已经确定这种抗体具有治疗价值。
4.2 了解免疫库的发展
斑马鱼中的Quake和同事们首先完成了使用Ig-seq绘制全局抗体库的工作,它们具有适应性免疫的基本特征,但与小鼠或人类相比,具有更少的VDJ组合。随后,Ig-seq已被用于分析多种其他物种的库,包括小鼠,鸡和牛。
但是,更重要的是,Ig-seq对塑造人类幼稚BCR曲目的机制提供了前所未有的见解。如上所述,VH组成部分的Ig-seq分析揭示了人免疫球蛋白基因座中的高度等位基因多样性。我们实验室和其他实验室对原始BCR谱系中种系VH,Vκ和Vλ片段的使用情况以及特定VD和DJ片段之间重组频率的分析显示出明显的偏斜,进而使成熟的,有抗原经历的B细胞形成了该谱系。在VDJ重组中,单个D段阅读框是绝对优选的,D段的倒置极为罕见,而CDR-H3区在氨基酸组成,平均疏水性,电荷分布和长度方面表现出普遍的分类约束。具有长或带电荷的CDR-H3的抗体具有极大的临床意义,因为尽管它们更有可能是自身反应性的,但它们通常能够与病原体上的封闭位点结合并介导病原体中和。在人类库中,长的CDR-H3通过DD连接(在原始库中的频率从0.125%到> 0.5%发生,但在经历过抗原的B细胞中减少)产生,并且通过大量核苷酸添加以及优先使用更长的核苷酸而产生种系中的D段和更长的J6段。疏水性的守恒是脊椎动物进化的一个共同主题,它导致选择中性的CDR-H3并对抗亲水性的极端(带电或疏水)抗体结合位点。总的来说,这些发现表明人类的CDR-H3环探索了巨大的序列空间,但在边界内
最近的研究表明,一抗库中VDJ重组频率具有确定性。纯合子双胞胎抗体库中VDJ区段的用法是无法区分的,这表明它是由遗传因素决定的。但是,必须注意的是,CDR-H3的多样化导致了高度私有的库,个人之间几乎没有重叠。此外,在植入了人类CD34 +造血干细胞的免疫功能低下的小鼠中开发的人类幼稚抗体库显示了V-J的使用模式,甚至更惊人的是,抗体的检查点耗竭表现出与人类相似的自身反应性特征。
从B细胞在不同解剖部位编码的抗体库的测序也获得了重要的见识。一项特别值得注意的研究分析了小鼠肠道IgA库。小鼠固有层肠黏膜B细胞库的另一项研究提出了一种有趣的可能性,与长期的教条相反,骨髓可能不是成年B细胞发育的唯一部位。这是因为肠道中的B细胞表达了Rag-1重组酶,表现出pre-B或未成熟的B表型,重要的是,编码了独特的VL组成成分。这些特征与固有层中B细胞的发育和原位选择一致。还检查了脑脊液中的IgG VH组成,发现与外周血相比,其体细胞超突变有所不同,这进一步表明B细胞成熟可能独立于中枢神经系统或外周发生。
几项研究试图通过外周血B细胞的Ig-seq估算人抗体谱的总多样性。由于抗体库规模大,采样深度可变,B细胞亚群之间的转录差异,测序错误以及最后但并非最不重要的事实是,外周血占所有B细胞的<2%,这一任务非常具有挑战性。绝大多数已发表的研究[105,120]和我们未发表的数据与以下观点相一致:
- 一方面,VH基因库是高度私有的(对个体而言是唯一的),尽管少数CDR-H3似乎在不同的个人之间共享(换句话说,它们是成见的或公开的)。
- 但是,由于VL基因库的多样性较低,因此在轻链中发现了相当一部分共享序列。
- 有趣的是,共享的IgL链基因也往往是表达最丰富的基因
4.3 传染性疾病
Ig-seq还提供了对病原体激发或疫苗接种引起的适应性免疫应答的见识。病原体攻击可以影响应答B的BCR组成以及幼稚的组成。许多病原体会产生超抗原,这种超抗原是与某些抗体V结构域结合的蛋白质,导致BCR交联和随后的B细胞缺失。可以预见,超抗原暴露会导致原始抗体库偏斜。然而,令人惊讶的是,在组成型表达超抗原的转基因小鼠的幼稚库中未观察到与超抗原结合的V基因的消耗。有趣的是,慢性丙型肝炎感染患者的原始B细胞抗体库也有报道。接种或感染后,抗体库的整体变化也很明显。值得注意的是,Boyd,Fire和同事在经历了急性登革热感染的患者中观察到了收敛的抗体特征(定型的CDR-H3序列)。该观察结果提出了旨在检测定型反应的Ig-seq可用作预测传染病严重程度的诊断工具的可能性。
Ig-seq的另一个令人兴奋的潜在应用是鉴定与从个体分离的保护性抗体编码的基因克隆相关的V基因。然后可以从未突变的共同祖先IgH种系序列开始,推断导致这些保护性抗体进化的抗体谱系。此方法与了解在快速发展的病毒病原体(例如流感和HIV-1)感染期间广泛中和抗体(bNAb)的进化特别相关。在同一宿主中不断发展的病毒种群和抗体应答的时间顺序测序,以及bNAb的分离,正在帮助描绘对病毒施加选择性压力的适应性免疫应答与病毒逃逸突变的出现之间的动态关系。追踪导致bNAb产生的进化途径对于免疫原和疫苗接种计划的设计也至关重要,该计划将通过首先激活天然,种系,表达抗体的B细胞,然后将B克隆选择转向亲和力成熟来引发免疫反应。导致产生bNAbs的途径。对VRC01类抗HIV-1 bNAb的多供体分析证实,从单个祖先B细胞诱发此类抗体确实在多个个体中发生。 Ig-seq也可用于评估佐剂(如toll样受体4(TLR4)或TLR7 / 8激动剂)引起的先天性免疫应答如何影响抗体应答的多样性以及可能的抗体功能。
Ig-seq也可用于回答一个长期存在的问题,即为什么某些年龄段的人(通常是老年人)对传染病的敏感性更高和/或接种疫苗的保护性较差。例如,通过分析流感疫苗接种前后各个年龄组志愿者的VH谱系的抗体谱系结构,同种型和突变负荷,我们的实验室检测到老年人接种疫苗前的IgM突变负荷较高,而疫苗接种后的库多样性较低。另一项研究还发现,老年人在接受流感或23价肺炎球菌疫苗接种前后,IgM和IgA CDR-H3多样化程度较小。
4.4 免疫功能异常
我们希望对自身免疫性或原发性免疫缺陷患者的抗体库进行深度测序将提供重要的机理见解,进而可以指导适当疗法的发展。然而,迄今为止,很少有免疫失调患者抗体库的分析报告。我们认为这种缺乏反映了Ig-seq的最新发展。也就是说,已经报道了一些研究。在多发性硬化症中,脑脊液VH基因库有偏见,并显示出B细胞活化的有力证据。确定脑脊液中活化的B细胞是否对KIR4.1有反应是很有趣的,KIR4.1是最近发现的多发性硬化症的主要抗原。在特发性IgG4相关性胆管炎(一种与血清中IgG4异常水平相关的自身免疫性疾病)中,Ig-seq显示受影响的组织和外周血中存在大量克隆性IgG4扩增。皮质类固醇治疗后,这些克隆扩增消失了,表明IgG4克隆性的确定是该疾病的显着特征,因此构成了鉴别诊断的有用工具。
4.5 癌症
B细胞白血病,淋巴瘤和多发性骨髓瘤是在B细胞发育的不同阶段出现的恶性肿瘤(图2)。这样,恶性B细胞上的BCR构成了恶性细胞群丰富的生物标记。外周血B细胞,骨髓样品,肿瘤,甚至血液中游离DNA中V基因组成的Ig-seq已用于疾病检测和确定恶性细胞中抗体进化和多样化与疾病的关联程度进展或复发。例如,外周血V基因的Ig-seq有助于在治疗B细胞慢性淋巴细胞性白血病(CLL)(成年人中最常见的白血病)之后检测癌细胞并减少残留疾病。使用Ig-seq整体确定V基因库并检测白血病克隆(其V基因序列是在治疗开始前通过对癌细胞样品的分析确定的)编码的抗体的存在,从而避免了开发一种针对每位患者的CLL克隆型进行个性化PCR测定,以确定是否发生了复发。 Ig-seq还用于检测患有B细胞急性淋巴细胞白血病(B-ALL)的小儿患者的最小残留病,并作为非霍奇金淋巴瘤的标志物。
Ig-seq还显示B-ALL患者表现出不同程度的克隆型多样性,这主要是由VH基因置换引起的,并且似乎与复发频率有关。在CLL中也观察到了少量的B细胞克隆异质性(程度取决于疾病是起源于未突变的还是体细胞超突变的B细胞)。相比之下,多发性骨髓瘤的恶性克隆型是一种由于骨髓中的终末分化浆细胞(图2)而缺乏抗体多样化活性机制的疾病,几乎没有异质性的证据。值得注意的是,在CLL和其他血液系统恶性肿瘤中,在许多患者中检测到相同的(定型的)CDR-H3。高通量测序在检测尚未显示临床疾病的受试者中可能以低频率出现的恶性定型克隆型的广泛应用可能被证明是一种有用的早期诊断工具。最后,Ig-seq也可用于了解血友病,这是导致血清中抗体异常高水平的条件。这些在老年人中更普遍,并且可以发展成多发性骨髓瘤
五、结论
体液免疫系统已经进化为编码惊人的多样性抗体,这些抗体共同组成抗体库,并提供强大的识别试剂(或预期受体)库,可以识别几乎任何具有生物学意义的有机大分子。 B淋巴细胞及其“预期”受体(anticipatory)(用来强调幼稚库结合生物学相关抗原的能力)的术语与最后一个常见的脊椎动物祖先(5亿年前)一样古老。脊椎动物适应性免疫系统的异常复杂性可以比喻为希腊神话中的泰坦兄弟Epimetheus(hindsight)和Prometheus(foresight)。抗体基因的种系保守性带有人类适应进化过程中所暴露的病原体的古老适应性烙印,因此,其范围是Epimethean。另一方面,由个体中经历过抗原的成熟B细胞编码的全集所代表的免疫学前瞻性使其能够适应未来的病原体挑战,并且是Promethean和预期的特征。高通量DNA测序技术的出现使抗体基因库的确定达到了前所未有的深度,甚至在六年前也是无法想象的。我们可以开始解读Epimethean和Promethean的体液免疫区室,以及两者之间的相互影响。正在以惊人的速度开发提高序列精度和数据分析的技术,这重塑了我们对B细胞免疫学许多重要方面的理解,并日益影响临床诊断,抗体药物发现和疫苗开发。但是,要实现Ig-seq的全部影响,将需要实施用于实验注释和数据分析的标准,以及创建便于沉积和共享这些重要数据的数据库。
参考资料
- Nature Biotechnology volume 32, pages158–168(2014).The promise and challenge of high-throughput sequencing of the antibody repertoire. https://www.nature.com/articles/nbt.2782
