【4.9.1】Ig H链足以确定大多数B细胞克隆关系
- 超过80%的基于H链的克隆包含表达一致L链的细胞。
- L链连接的多样性没有进一步完善这些基于H链的克隆。
- 利用其他H链特征可以改善B细胞克隆推断。
摘要
B细胞克隆扩增对于适应性免疫至关重要。高通量BCR测序可以研究此过程,但需要进行计算推断才能确定克隆关系。该推论通常仅依赖于BCR H链,因为大多数当前protocol不保留H:L链对。配对的L链在多大程度上有助于推断。使用人类单细胞配对的BCR数据集,我们评估了基于H链的克隆聚类识别克隆的能力。在鉴定出的扩展克隆中,有不到20%的细胞表达了不一致的L链。与正确的克隆相比,这些聚簇的克隆的H链包含更多的远距离连接序列,并且共享的V段突变更少。这表明可以利用其他H链信息来完善克隆关系。相反,L链不足以完善基于H链的克隆簇。总体而言,仅BCR H链就足以自信地确定克隆关系。
一、前言
B细胞介导的免疫依赖于B细胞克隆扩增产生的Ig Ab。 BCR是Ab的膜结合形式,由以异二聚体形式配对的H和L链组成。每条链包含一个可变(V)区,并且来自H和L链的V区共同形成Ag结合位点。通过V(D)J重组形成V区。在人类中,这种改组过程将来自H链V(VH)区的多个IGHV,IGHD和IGHJ基因中的一个基因和分别来自κ和IGKV和IGKJ基因或IGLV和IGLJ基因的一个基因聚集在一起或λL链V(VL)区。酶介导的V(D)J连接处的编辑以及H和L链的配对注入了额外的多样性(1)。在适应性免疫应答过程中,B细胞通过体细胞超突变(SHM)增殖并进一步多样化,形成克隆,该克隆由源自相同V(D)J重组事件但其BCR在核苷酸水平上不同的细胞组成。<color=‘green’>结果,每个BCR在很大程度上都是唯一的,最近的估计表明在循环库中有1×10^16–10^18个成对的Abs(2)。
自适应免疫组库受体测序可通过批量的全长V(D)J测序对不同的BCR组库进行高通量分析(3)。随之而来的挑战是通过计算推断出B细胞的克隆关系(4)。此步骤非常重要,因为评估库属性(例如多样性)(5)取决于克隆的正确识别,以及用于追踪同种型转换(7)和Ag特异性(B)的B细胞克隆谱系(6)的重建也是如此。 绝对为了推断克隆,序列核苷酸水平的差异,尤其是CDR3区的高度多样性,可以作为“指纹”(9)。存在基于可能性(10)和基于距离(11-14)的方法。例如,可以将共享相同IGHV和IGHJ基因且其H链连接序列基于固定(11-13)或自适应(14)距离阈值足够相似的细胞聚类为克隆。为了进行验证,现有方法使用模拟和实验性H链序列(10、13、14),分别测量推断出的克隆无关和相关,真正无关和相关的序列分数(特异性和敏感性)。最近,Nouri和Kleinstein(14)根据模拟数据报告了两个指标均超过96%。
当前的大多数BCR库研究都利用批量测序(15),在此期间VH:VL配对丢失(16)。在没有VH:VL配对的情况下,用于识别克隆的计算方法集中在H链BCR数据上。在单独的H链连接多样性应足够高的假设下,即使没有L链,克隆无关的细胞聚集在一起的可能性也可以忽略不计,这是合理的(13)。这种推理尚未经过实验数据的严格检验。单细胞BCR测序技术的最新突破已使天然VH:VL配对得以恢复(17,18)。现在,我们有机会调查L链的包含影响在多大程度上影响准确检测B细胞克隆关系的能力。
使用单细胞VH:VL配对的BCR数据,我们通过测量推断的克隆成员表达具有相同V和J基因以及连接长度的一致L链的程度,评估了基于H链的计算方法用于鉴定克隆的性能。我们得出的结论是,大多数推断克隆的克隆成员均表现出L链一致性。对于大多数精确推断出的基于H链的克隆,L链信息并未导致更大粒度的进一步克隆聚类。考虑到H链V段中共有突变的模式时,至少从配对L链数据中获得的一些信息是显而易见的,而当前基于距离的克隆聚类方法并未考虑这点,从而为H的进一步改良提供了潜力基于链的克隆推理。
二、材料和方法
2.1 单细胞免疫分析数据集
由10x Genomics在2018年8月1日公开发布的四个人类数据集(补充图1A)在2018年11月3日被访问( https://support.10xgenomics.com/single-cell-vdj/datasets )。两个数据集分别通过直接Ig富集从健康捐献者的PBMC中分离的CD19 + B细胞和GM12878 B淋巴母细胞系来进行分类和生产。它们包含单个细胞的VH:VL配对读取。其他两个数据集是未分类的,分别来自健康捐献者的PBMC和新鲜手术切除的鳞状非小细胞肺癌(NSCLC)细胞的V(D)J + 5’基因表达谱。这些包含基因表达测量和通过VH:VL配对进行的Ig富集。所有数据集均通过Cell Ranger(v2.2.0)通过10x Genomics输出。我们分别对Ig和基因表达使用了“过滤 contigs”(filtered contigs)和“过滤基因条形码矩阵”(filtered gene-barcode matrices)。
来自(19)的第五个数据集(补充图1B)包含BCR contigs,覆盖从六个食物过敏性个体的FACS分选的CD19 + B细胞的单细胞RNA测序重建的全长V(D)J片段(19)。
2.2 BCR contigs的胚系V(D)J基因注释
使用IMGT / HighV-QUEST和IgBLAST(v1.10.0)进行胚系V(D)J基因注释。使用的种系参考是IMGT版本201839-3。 10x Genomics数据集还包含Cell Ranger的注释。 IMGT / HighV-QUEST注释被用作后期过滤的最终注释。
2.3 过滤BCR重叠群和细胞 Filtering of BCR contigs and cells
对于所有数据集,仅使用具有有效的V和J基因注释,一致的链注释(不包括具有IGHV和IGK / LJ的重叠群)和核苷酸长度为3的倍数的连接的生产性重排BCR重叠群。重叠群必须基于所有使用的程序的注释满足所有上述条件。此外,仅检查具有恰好一个H链重叠群与至少一个L链重叠群配对的细胞。从具有基因表达的两个未分类的10x基因组数据集中,我们只考虑了显示与B细胞一致的转录组特征的细胞。考虑到单细胞RNA测序的高缺失率,B细胞被定义为以下任一基因的非零对数归一化表达的任何细胞:pan-B细胞标记CD19,CD24和CD72(20),浆细胞标记CD38和MKI67(21),以及同型编码基因IGHA1,IGHA2,IGHD,IGHE,IGHG1,IGHG2,IGHG3,IGHG4和IGHM。
2.4 基于H链的B细胞克隆聚类
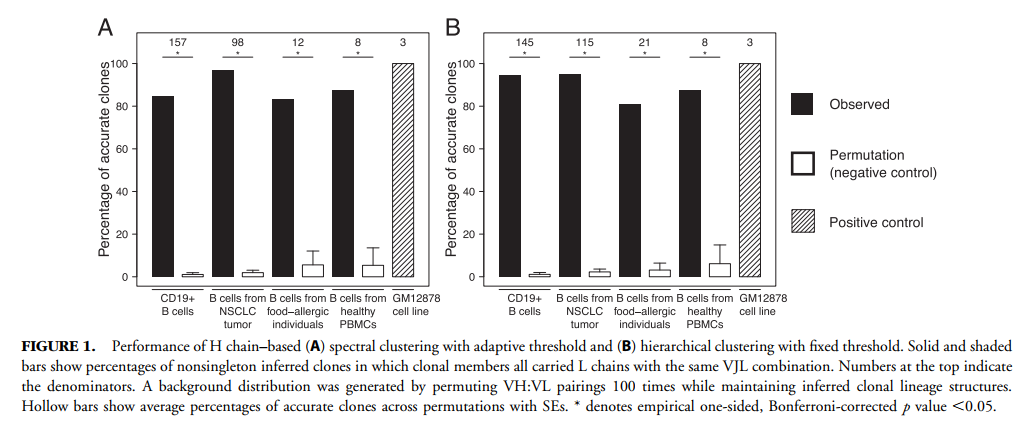
对于每个数据集,我们根据每个对象使用基于距离的方法来识别克隆。我们分别使用了频谱聚类(spectral clustering, SCOPer v0.1.999)(14)和分层聚类(13)(Change-O v0.4.3)(22)。两种方法都首先将细胞分成IGHV基因,IGHJ基因和H链结长度(H链VJ junction 长度[VJL]组合)相同的组,其中junction 定义为IMGT编号的密码子104(保守的半胱氨酸)至密码子118(保守的Phe / Trp)(23)。在每个组中,基于H链连接序列之间的距离,使用阈值将该组中的细胞聚集成克隆。对于频谱聚类,通过无监督的机器学习算法选择自适应阈值。对于分层聚类,在检查距最近邻居的图时选择了特定于受试者的固定阈值(补充图1C)(13)。
2.5 计算核苷酸突变的数量和频率
使用SHazaM(v0.1.10)的“ calcObservedMutations”函数,根据直至连接区的IGH / K / LV位置计算核苷酸突变的次数和频率(22)。 为了计算来自同一克隆的细胞之间成对共享的IGHV突变数,我们计算了两个细胞中观察到涉及相同核苷酸变化的突变的位置数。 铁汉 09:35:29
三、结果
我们仅使用每个细胞的H链序列对五个单细胞,VH:VL配对的人BCR数据集进行了克隆关系推断。 数据集包括来自10x Genomics的四个公开可用的数据集,以及一个由(19)(材料和方法)描述的数据集。 其中,B淋巴母细胞样的GM12878细胞系数据集可作为阳性对照,因为可以预期存在于细胞系培养物中的任何细胞都包含基因相同的克隆成员。 基于距离的光谱聚类方法(14)用于识别每个数据集的克隆。 数据集包含3到157个非单例克隆(即,至少包含两个单元格的克隆)(表I)。 由于(19)数据集中的六个食物过敏个体中每个个体的克隆数量都很少,因此我们将这些结果汇总起来,以供每个受试者进行分析后显示。

3.1 基于H链的克隆聚类可精确用于80%以上的克隆
为了评估基于H链的克隆聚类捕获B细胞克隆关系的潜在生物学真相的程度,我们检查了仅基于H链的聚类到同一克隆中的细胞是否表达了一致的L链。具体而言,在同一克隆内,真正克隆相关的细胞应携带由IGK / LV基因,IGK / LJ基因和相同长度的连接序列的相同组合组成的L链(以下称为VJL组合)。如果其所有克隆成员均携带具有相同VJL组合的L链,则推断出的克隆是正确的,否则被“错误聚类”。使用具有自适应阈值的光谱聚类,可以推断出83–97%的克隆是准确的(图1A)。使用固定距离阈值(13)的另一种基于距离的层次聚类方法产生了相似的结果(图1B),因此,我们在下文中着重介绍频谱聚类的结果。为了测试偶然发现观察到的准确性的可能性,我们随机排列了细胞的VH:VL对,同时保持了其基于H链的聚类结构。在100个排列中,偶然克隆的精确克隆中只有1-6%(标准差1-8%)是准确的(图1A)。总体而言,这些结果表明,基于H链的克隆聚类可以在L链一致性方面以合理的置信度(> 80%)确定克隆关系。

接下来,我们调查了与克隆聚类方法本身无关的因素降低了所观察到的置信度的可能性。我们考虑了由于测序准备过程中错误的条形码而导致出现克隆错误的克隆(补充图2A)的可能性,这有可能将无关细胞的H和L链连接在一起。我们认为,与正确配对的链相比,错误配对的H和L链的SHM频率将显示出降低的相关性。因此,我们针对表达错误簇的非多数L链VJL组合的细胞,计算了IGHV和IGK / LV突变频率之间的Pearson相关系数。我们发现错簇克隆(0.761)和精确克隆(0.769)的相关水平之间没有显着差异(p = 0.926,Fisher r-z转换和z检验),这表明错误的条形码不太可能引起关注。此外,我们考虑了对L链的种系V / J基因注释不正确的可能性,从而导致L链不一致的错误出现。因为较高的SHM频率与增加的V(D)J注释错误相关,所以我们比较了聚簇和精确克隆中的L链突变频率。我们发现在错误克隆中表达非多数L链VJL组合的细胞之间的平均IGK / LV突变频率并不明显高于在精确克隆中的细胞之间的平均IGK / LV突变频率(p = 0.957;补充图2B)。总体而言,这些基于SHM分析的结果表明,使用错误的条形码或错误的L链种系基因注释造成的L链不一致的假象并未消除观察到的使用基于H链的克隆聚类准确鉴定克隆的信心。
。。。。。
四、讨论
在这项研究中,我们调查了基于H链的克隆推理的准确性。使用单细胞VH:VL配对的BCR数据集,我们仅使用H链进行了B细胞克隆推断,有效地将数据集视为批量测序和未配对。如L链一致性所定义,超过80%的推断克隆是准确的。在大多数这些精确克隆中,使用L链序列进行的另一轮聚类未能产生更高的分辨率(在归一化汉明距离为0.1的阈值下,<10%)。包括一个要求克隆成员在H链序列之间共享突变的要求,才能纠正87%的错簇克隆,尽管这样做的代价是还要破坏13%的这些错簇克隆中的准确簇集部分。总体而言,尽管仍有来自H链的其他信息可用于改进,但我们发现仅基于H链的聚类能够以合理的置信度识别克隆关系。
来自四个错簇克隆(13%)的细胞带有紧密相关的H链,在V段中共享合理数量的突变,但它们表达的L链具有不同的VJL组合。这种克隆如何产生有几种可能性。在B细胞成熟期间,H链首先重排,而L链重排之前细胞增殖(1)。因此,我们检测到的克隆关系克隆错误可能代表了发育不同L链的相同H链VDJ重排B细胞的子细胞。或者,一组相同的,自身反应性的,未成熟的B细胞可能已经经历了受体编辑,在此期间,独立的重排产生了具有相同的H链重排的不同L链。在这些情况下,基于H链的克隆聚类准确反映了基础生物学。但是,我们认为这些情况不太可能发生,因为具有相同的H链但不同的L链的细胞除了被一起采样以进行测序外,在发育上会共享相同的时间和/或空间轨迹的机会很小。
检查来自推断克隆的细胞的L链一致性时,如果一个细胞与一个以上的L链序列相关联,我们将检查每个存在的序列是否与多数克隆VJL组合匹配。但是,我们没有考虑在这种细胞中进行部分采样的可能的复杂性。假设,如果两个具有双L链的克隆相关B细胞各自具有不同的L链序列,我们的分析将考虑包含这些细胞的H链克隆。但是,据报道这种B细胞很少见,尤其是在自身免疫之外,双κ和双λ细胞估计占正常鼠类的2-10%(24、25)和0.2%(26),与本研究在单细胞数据集中观察到的具有多条L链的细胞百分比一致(双倍:1.00–7.06%;三倍:0.00–0.31%;四倍:0.00–0.02%;数据集中来自(19 )只有一个L链)。
。。。
参考资料
- Follow The Journal of Immunology on Twitter Follow The Journal of Immunology on RSS Cutting Edge: Ig H Chains Are Sufficient to Determine Most B Cell Clonal Relationships. https://www.jimmunol.org/content/203/7/1687
