【4.6.4】改进了抗体VL-VH方向的预测
摘要
抗体是具有高商业价值和治疗兴趣的重要免疫分子,因为它们能够结合多种抗原。 抗体结构的计算预测可以快速揭示有关这些抗原结合相互作用性质的有价值信息,但前提是模型具有足够的质量。为了在互补决定区(CDR)结构预测期间实现高模型质量,必须考虑VL-VH方向。
- 我们开发了一种新颖的四个维度VL-VH方向坐标系(怎么新?为啥是4维度指标?)。
- 我们使用新的方法扩展了RosettaAntibody中的CDR移植方案(grafting protocol),该方法通过使用10个VL-VH定向模板而不是单个模板来使VL-VH定向多样化。我们在已知抗体晶体结构的两个数据集上测试了多模板移植方案。在模板移植阶段(template-grafting protocol),新流程将准确的VL-VH方向预测的比例从仅26%(12/46)提高到72%(33/46)的目标。
- 在完整的RosettaAntibody方案(包括CDR H3重新建模(remodeling)和VL-VH重新定向(re-orientation)之后,新方案产生了比43/46目标中标准方案准确的VL-VH方向更多的候选结构(93%)。提高预测VL-VH方向的能力将加强对互补位其他部分的预测,包括CDR H3的构象,这是抗体同源性建模的一大挑战。
一、前言
抗体是具有高商业价值和治疗意义的重要免疫分子,因为它们能够结合多种抗原,从小分子和短肽到全长蛋白质。 抗体的结合多样性是来源于高变FV结构域,每个结构域由两个免疫球蛋白结构域组成:VL和VH。 抗原结合位点(paratope)位于VL-VH界面附近的六个环上,称为互补决定区或CDR。( Paratope与cdr应该不是一个概念吧??)
FV的许多结构研究都集中在CDR的构象上,特别是CDR H3(Al-Lazikani等,1997; North等,2011; Wang等,2013; Weitzner等,2015; Xu)。 因为CDR附着于VL和VH结构域的框架(framework,这里注意了,Fv中CDR以外的部分我们叫做framework哦。),VL和VH结构域的相对取向的任何变化都将导致改变CDR的相对取向,并因此改变互补位的形状。 在CDR或互补结构预测期间未能解释VL-VH取向显着阻碍了输出模型的质量,并且最近的评估发现VL-VH定向是抗体结构预测的限制因素(Weitzner等人,2014)。
Abhinandan和Martin(2010)是第一个编制测量VL-VH方向的度量标准的人。 他们将填充角(packing angle)定义为VL域和VH域的主轴之间的扭转角。 在他们分析的500多个FV晶体结构中,填充角度差异多达30°。
Chailyan等人(2011)通过聚类以不同方式定义VL-VH方向。 由此产生的描述在范围上受到限制:仅发现了两个不同的定向簇(orientational clusters)和一个不同的单体(singleton); 然而,发现许多关键残基与取向簇相关,表明VL-VH取向可以从序列中预测。
第二抗体建模评估(the second antibody modeling assessment, AMA-II)测量了几种计算抗体结构预测方法在盲预测挑战中捕获天然VL-VH方向的能力。使用两个度量来评估在AMA-II中产生的抗体取向:(i)如Sela-Culang等人(2012)所述的RMSD变体的类似物,和(ii)如Almagro等人(2014)所述的倾斜角度。虽然这些测量编码比Abhinandan-Martin打包角度(packing angle)更多的方向信息,但两者都是成对差异度量而不是绝对值。
Dunbar等人发表了一种几何完整的VL-VH方向绝对测量方法,即ABangle。 (2013年)。 ABangle由一个扭转角,四个平面角和一个距离组成,代表VL-VH复合体的六个自由度。在研究中应用ABangle测量来预测VL-VH方向。
在对AMA-II抗体数据集的测试中,作者预测对应于0.50Å的平均RMSD的ABangle指标,表现优于普通竞争者(0.63Å),超过11个目标中的9个的平均值(Bujotzek等,2015)(搞不懂,回头看看这个文献。。。)。
RosettaAntibody是用于抗体结构盲预测(blind prediction)的应用(Sivasubramanian等,2009; Weitzner等,2014)。 RosettaAntibody分两个阶段进行操作:
- 模板选择(template selection)和移植(grafting),其中已知的抗体结构片段被组合以产生粗粒度模型(coarse-grained model)
- 结构细化(structure refinement ),其使用具有最小化的蒙特卡洛扰动(Monte Carlo perturbations )来重构CDR H3环, 细化(refine)所有CDR环,并重新组合(redock)VL和VH域
直到最近,RosettaAntibody在预测天然VL-VH方向( orientations )方面的功效仅通过测量所有FV残基的RMSD值而被隐含地研究。 在第二次抗体建模评估(AMA-II)期间,RosettaAntibody的方向预测被明确评估,比较Rosetta模型的填充角度与其相应晶体结构的填充角度(Weitzner等,2014)。RosettaAntibody在大多数方面与竞争流程相比,产生了两个亚ÅstromH3模型,并在四个目标中实现了最佳H3模型。然而,VL-VH定向是一个弱点,因为RosettaAntibody仅为11个目标中的5个创建了具有亚Åstrom交叉域(crosss-domain )RMSD的结构。 具有不常见的填充角度的目标的VL-VH方向预测特别差:从数据库平均值中删除了包装角度(packing angle)大于1 SD的所有三个目标都被错误地预测。
在本文中,我们开发了一种新的四度VL-VH方向坐标系,我们称之为轻重方位坐标(Light–Heavy Orientational Coordinates,LHOC)。 此外,我们使用一种新方法扩展了RosettaAntibody流程,通过嫁接多个模板来使VL-VH方向多样化。 我们在已知抗体晶体结构的两个数据集上测试了新的RosettaAntibody方案:46个成员的高分辨率抗体组和11个成员的AMA-II数据集。 我们比较了新RosettaAntibody与先前版本的性能,以及用于预测VL-VH方向的ABangle方法
二、材料和方法
2.1 方位坐标框架计算 Orientational coordinates framework calculation
用于描述VL-VH取向(α,δID,θL和θH)的四个坐标是从VL-VH界面处的四个非原子点的共同框架定义的(图1)。
- 点2位于VL框架中保守的β链对的中心; 它被定义为使用Chothia编号的残基L35-L38和L85-L88的Cα坐标的质心(Al-Lazikani等,1997)。
- 点3是点2的VH对应物,定义为残基H36-H39和H89-H92的Cα坐标的质心,Chothia编号。
- 点1沿着用于计算点2的坐标集的第一主分量线,比点2更靠近CDR
- 点4是与点1的VH对应点
所有坐标都是使用上述框架的Rosetta实现计算的。 α的定义与Abhinandan和Martin(2010)的定义相同; 具体而言,它定义为点1,2,3和4之间的二面角.δID定义为点2和3之间的距离.θL定义为点1,2和3之间的平面角.θH定义 作为点2,3和4之间的平面角度
(看到这,总算豁然开朗,比Abhinandan描述的要清楚多了。。。)
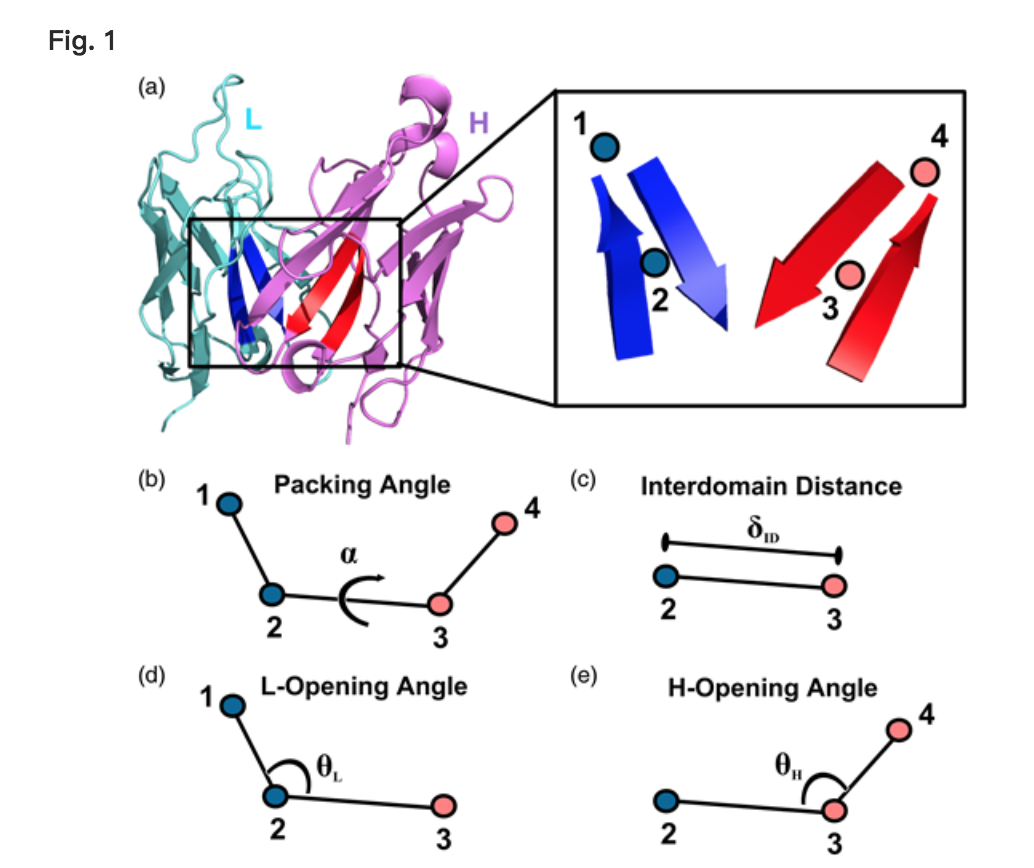
Orientational coordinate (LHOC) definition. (a) FV structure showing light chain (cyan), heavy chain (pink) and the key beta strands for defining the LHOC framework (Chothia numbering: L35-L38 and L85-L88 in blue and H36-H39 and H89-H92 in red, see ‘Materials and Methods’ for details). The inset shows the placement of the four points, which form the basis of the LHOC framework. (b) Packing angle, α, is the dihedral angle between points 1, 2, 3 and 4. (c) Interdomain distance, δID, is the distance between Points 2 and 3. (d) L-opening angle, θL, is the plane angle between Points 1, 2 and 3. (e) H-opening angle, θH, is the plane angle between Points 2, 3 and 4.
2.2 方位坐标距离测量
方位坐标距离(OCD)计算如下:
$$ OCD = \sum_{i={α,δID,θL,θh}} (\frac{x_{i,A}-x_{i,B}}{δ_{i,dB}}) $$
其中 $x_{i,A} $和$x_{i,B} $ 分别代表结构A和结构B的LHOC度量i的值,$σ_{i,dB } $ 代表LHOC指标i最适合数据库分布的高斯分布的标准偏差(先要指定一个有意义的数据库,求出 i的分布,然后求出σ)。 i的四个值是α,δID,θL和θH。 OCD是无量纲的
2.3 RosettaAntibody命令行
新的MT流程,是Rosetta软件包的一部分,可在www.rosettacommons.org 免费获得学术和非营利性使用。 用于生成本文数据的代码可从2015年5月21日发布的发行版修订版57开始提供。 MT流程可以在ROSIE公共Web服务器( rosie.graylab.jhu.edu ,Lyskov等,2013)上获得,作为抗体同源建模流程的一个选项。 要创建嫁接结构,请使用以下命令行。 执行盲预测时,homolog_exclusion参数应为99,而在已知集上评估算法性能时应为80
antibody.py --both-chains < FASTA file> --relax
--homolog_exclusion=<99||80>
--multi-template-grafting --number-of-templates 10
--light_heavy-multi-graft
--filter-by-orientational-distance = 1
--orientational-distance-cutoff 0.5
要创建候选结构,请为每个移植结构使用以下命令行。 abH3.flags是一个文本文件,包含标准RosettaAntibody运行的选项标志集。 cter_constraint文件是一个包含两个原子约束的双行文本文件; 它由前一个命令行自动生成。 移植结构是前一个命令行生成的10个模型之一。 -nstruct参数对于第一个移植结构应为1000,对于其他九个模型应为200
antibody_H3.linuxgccrelease @abH3.flags
-s < grafted structure, 1 of 10> -nstruct <200||
1000>
-constraints:cst_file < cter_constraint fil
2.4 抗体数据库集的制备
RosettaAntibody数据库由使用Sivasubramanian等人(2009年)描述的方法从蛋白质数据库中剔除的1040个抗体FV晶体结构组成。 一个异常抗体(1MCO)的域间距离为19.6Å,与第二大域间距离相比,距离最小的第二大域距离更远。 这种抗体是高度不规则的,FAb-FC铰链区被删除(Guddat等,1993),解释了不自然的大域间距离; 因此,从RosettaAntibody数据库的分析中除去了该抗体。
抗体基准集的制备
从PyIgClassify数据库(Adolf-Bryfogle等,2015)编译高分辨率抗体组。 对结构施加了一系列限制:
- 结构中每个原子的最大分辨率为2.5埃,
- 最大R值为0.2
- 最大B因子为80.0Å2,
- 不对称单元仅包含一个FV副本
- CDR H3环长度为9至20个残基
- 人或小鼠物种标签
- 没有非经典或修饰的氨基酸残基。
- 另外,过滤该组以除去任何重链CDR环中具有相同序列的抗体。
在得到的49个结构中,由于序列错位或编号中存在的挑战(例如1X9Q缺失高度保守的重链残基C92和W103),3个(1×9Q,2W60,3IFL)被消除。 第二抗体建模评估(AMA-II)抗体集由Almagro等人(2014)中描述的11种抗体组成。
三、结果
3.1 一个新的VL-VH坐标系
为了描述抗体VL-VH方向的几何结构,我们开发了一个新的坐标系(图1)作为Abhinandan和Martin(2010)描述的包装角的延伸。三个载体(vector)组成Abhinandan-Martin框架:两个主轴向量,分别描述VL和VH绘制,第三个载体,VL-VH界面尾部连接。 Abhinandan-Martin填充角(α)定义为VL和VH向量之间的视角,如从VH到VL的连接线向下看时所见(图1b)。打包角度(packing angle)量度捕获VL-VH相对位置的集合,其中VL和VH域彼此扭转,扩大或收缩互补位。
然而,图2显示具有相同α的抗体不一定会叠加,并且在实践中,它们通常不会叠加。这种结构模糊性是α度量的固有限制。因此,我们寻求更完整的VL-VH方向描述。
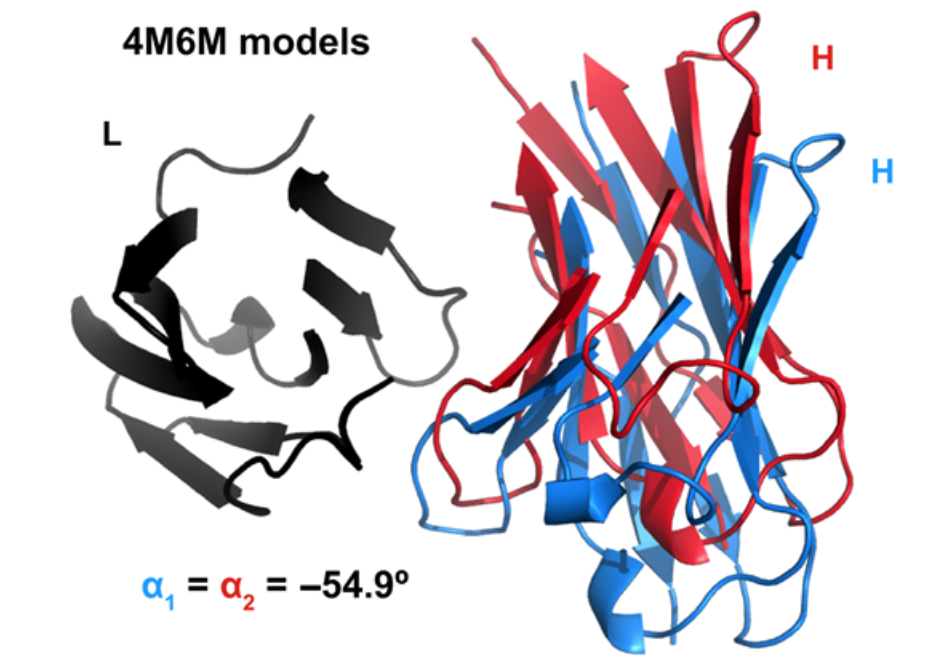
Two RosettaAntibody FV models of AMA-II target 5 (PDB ID 4M6M) with equivalent values of the packing angle. Structures have light chains (black) superimposed. Heavy chains are shown in red and blue. CDR residues (Chothia definition) are omitted for clarity.
为了捕获更多的VL-VH取向自由度,我们重新利用Abhinandan-Martin填充角度矢量框架来定义其他度量:域间距离(δID)和两个平面角度,L-开口角度(θL)和H-开角(θH)。 δID定义为连接载体的长度(图1c)。 θL和θH分别定义为连接载体与VL和VH载体之间的平面角度(图1d和e)。我们一起将四个坐标(α,δID,θL和θH)称为LHOC。
对于LHOC是非冗余坐标系并且比Abhinandan-Martin打包角更具描述性,每个坐标必须捕获VL-VH取向多样性的一些分量,其与其他坐标捕获的分量充分独立。为了评估LHOC坐标框架的有效性,我们计算了一组1040抗体FV晶体结构中每种抗体的LHOC指标,代表蛋白质数据库中所有抗体的高分辨率和中等分辨率(≤3.5 Å)。
图3显示了数据库中所有抗体的四个LHOC指标中每一个的分布。所有三个角度分布都近似为高斯分布。与先前使用填充角度来单独定义VL-VH方向一致(Abhinandan和Martin,2010; Almagro等,2014),α分布是VL-VH方向多样性的最大组成部分,具有近似范围35°[平均值(μ)= -52.3°,标准偏差(σ)= 3.9°,最小值= -70.9°,最大值= -36.7°]。两个LHOC平面角分布各自显示的范围大约是α分布的一半。 θL分布的范围约为15°(μ= 97.2°,σ= 1.9°,min = 89.3°,max = 104.4°),而θH分布的范围约为20°(μ= 99.4°,σ) = 2.6°,min = 87.9°,max = 108.1°)。 δID分布也近似为高斯分布,但尾部长。虽然大部分分布,1040个1040结构,位于13.5和15.5之间,但其余10个结构中有9个的δID介于15.5和16.5之间。
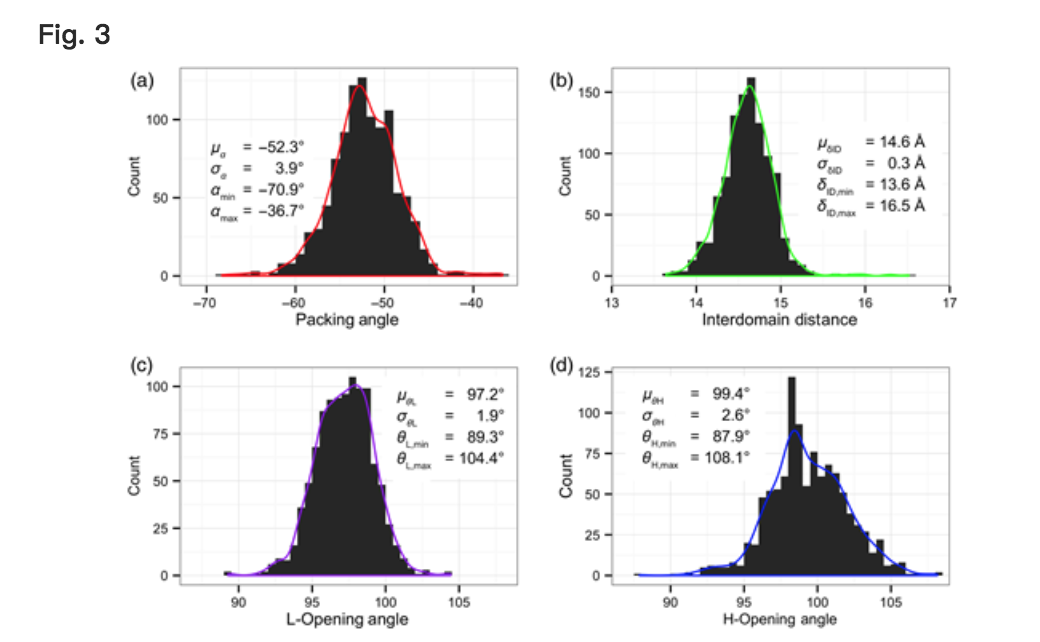
Histograms of each of the four LHOC metrics across the 1,040 structures in the Rosetta antibody database. Histogram bin widths are 1° for packing angle, α, (a), 0.1 Å for interdomain distance, δID, (b), and 0.5° for plane angles, θL and θH, (c and d). Kernel density estimates of each distribution are shown as curves over the histograms.
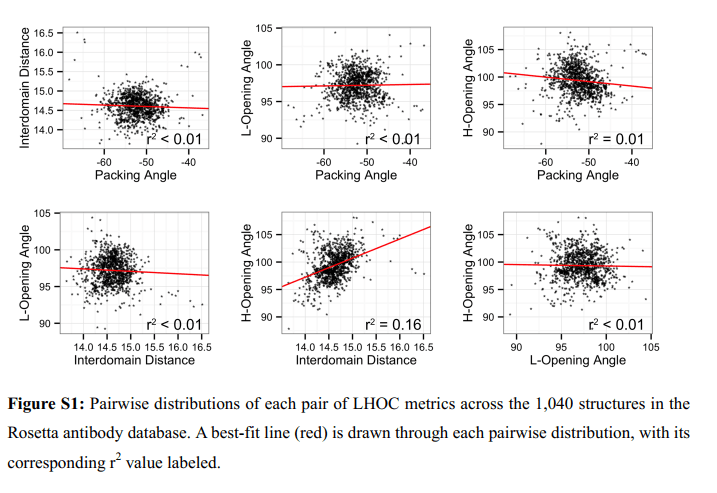
为了测试四种LHOC指标的独立性,我们绘制了数据库抗体指标的所有成对分布,如补充数据,图S1所示。六对度量中的五对没有显示相关性(r2≤0.01),具有近似2D-高斯分布。其余的对,θH和δID表现出较小的相关程度(r2 = 0.16); δID大于平均值的抗体往往也具有大于平均值的θH。这种相关性可能出现,因为θH定义的铰链不同于物理铰链,VL-VH取向实际上在抗体之间变化。如果物理铰链位于θH铰链的上游,则天然“开放”抗体将具有更大的θH和更大的δID。在这种情况下,人们也会期望抗体也具有更大的θL,因为它实际上是θH的镜像;然而,在δID和θL之间没有相关性,这表明数学和物理铰链处于类似的位置。这意味着θH和δID之间的相关性不是由于LHOC框架的错位,也不是LHOC中包含的冗余坐标选择
LHOC框架的四坐标性质允许它描述VL-VH取向的更多方面而不是单独的α,但它需要组合度量来简化与一维的差异。 因此,我们通过对四个LHOC基本指标中每一个的平方z分数偏差求和来定义OCD(详见“材料和方法”)。图4a显示OCD为1.0或更低的一对抗体紧密叠加,图4b显示OCD为2.0或更高的一对抗体明显不同。
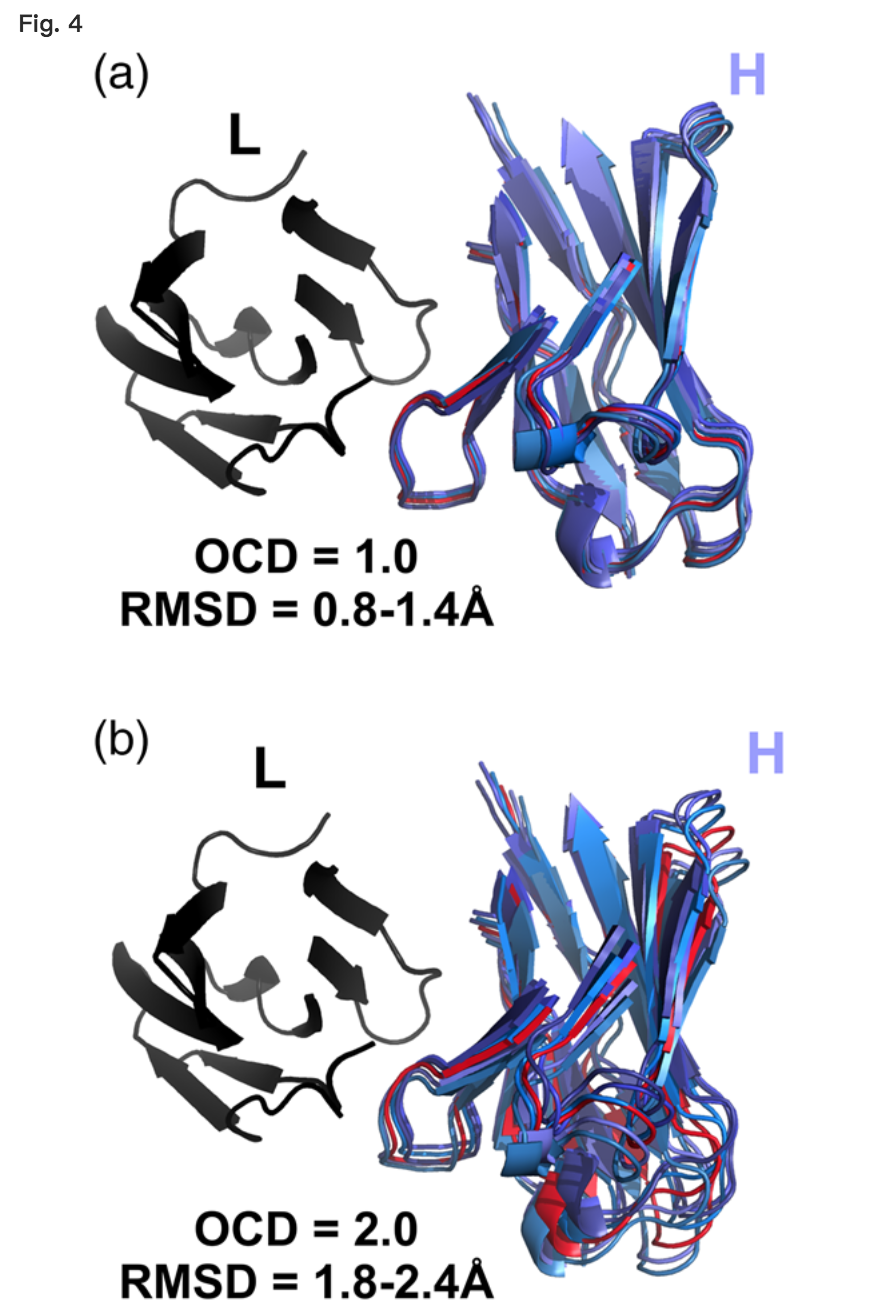
Comparison of five RosettaAntibody FV models (blues) with 1.0 OCD (a) and 2.0 OCD (b) to a reference antibody FV structure (red). Structures have light chains (black) superimposed. CDR residues (Chothia definition) are omitted for clarity.
因为不同LHOC指标的变化对抗体结构域产生不同的杠杆臂效应,并且因为对OCD的贡献可以由一个或两个LHOC指标的大变化支配,具有相同OCD的两个抗体对不一定具有它们之间的RMSD相同。例如,由于填充角度不同而具有3.0 OCD的两种抗体将具有比具有3.0 OCD的两种抗体大得多的RMSD,这仅归因于域间距离的差异。尽管如此,OCD和RMSD松散相关:如补充数据所示,图S2中,两个具有高OCD的结构也倾向于具有高RMSD。 2.0的OCD大致相当于1的RMSD,尽管由于域内变化,大多数2.0OCD结构对将具有更大的RMSD

3.2 VL–VH orientation prediction in Rosetta
Rosetta中的VL-VH方向预测随着OCD度量,我们接下来试图测试RosettaAntibody在预测正确的VL-VH方向上的功效。对具有不正确的VL-VH方向预测的AMA-II目标之一的RosettaAntibody候选结构的初步检查显示,在结构细化阶段期间通过对接移动对大范围的VL-VH取向进行采样 - 实际上如此宽,几乎整个数据库分布都跨越所有坐标。然而,得分最低的候选结构,以及因此选择作为最终模型的候选结构,具有与细化轨迹的起点非常相似的取向,即接枝结构。
为了研究起点如何偏向输出方向,我们从具有交替VL-VH方向的移植结构发射了细化轨迹。图5显示了这些运行生成的候选结构的方向分布。在每个轨迹中,存在可见井,其中低得分候选结构倾向于具有与其各个移植结构匹配的取向而不是收敛到原始取向。这些数据表明,RosettaAntibody的细化阶段对其改变VL-VH方向的程度有一定的有效限制。虽然可以对更远的结构进行取样,但这些结构与天然抗体不相似,正如它们的高分所证明的那样。当接枝结构具有天然VL-VH取向时,这种行为是有益的,但在一般情况下,它表明搜索不充分
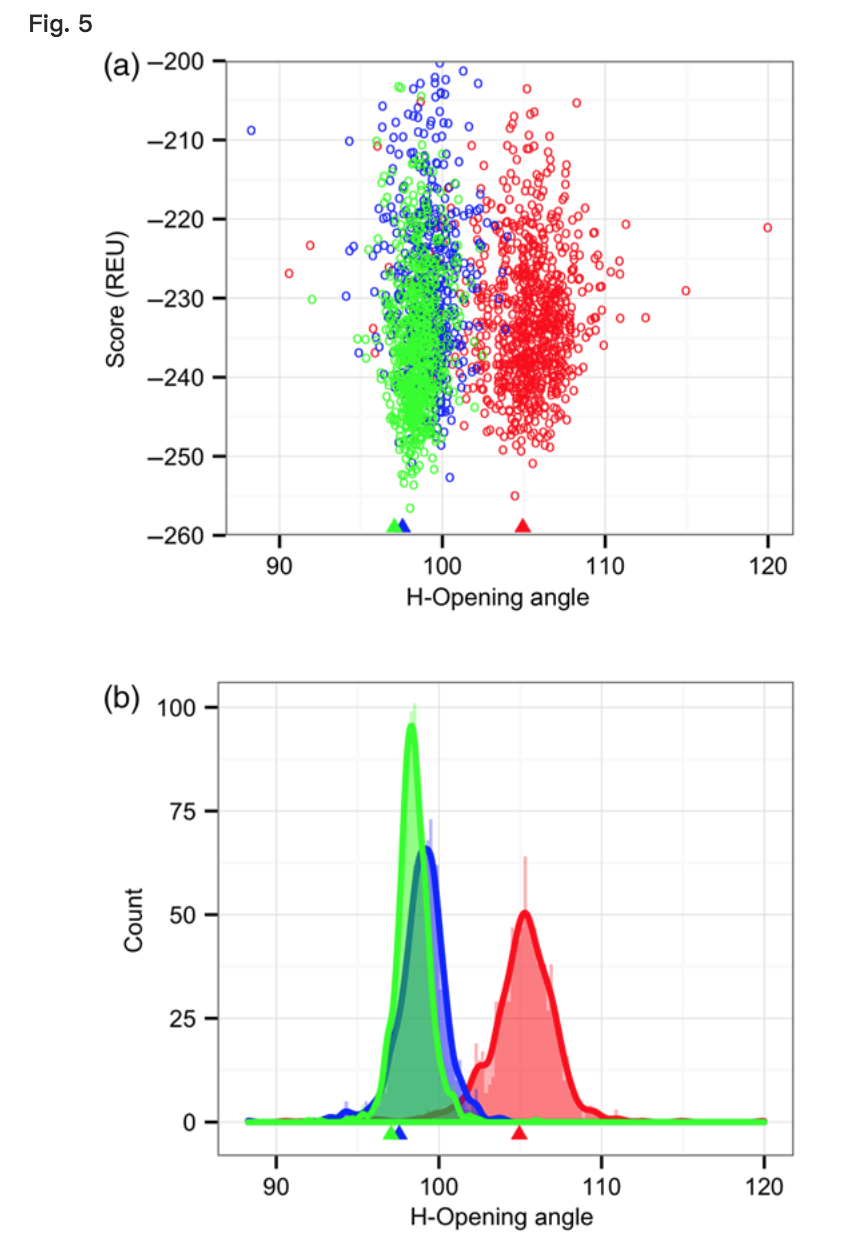
H-opening angle, θH, distributions among candidate structures generated by RosettaAntibody from three different starting grafted structures with different VL–VH orientations. (a) Plots of θH versus score, showing scoring funnels for each of the three runs in a different color, with the grafted structure θH marked by a matching-color triangle below the x-axis. (b) Histograms and kernel density estimates for each of the three runs in a different color, with the θH of each grafted starting structure marked as in (a).
为了尝试在原始VL-VH方向附近产生低得分候选结构,我们创建了一个新的RosettaAntibody嫁接方案,该方案运行多个轨迹而不是单个轨迹。该协议的流程图描述称为多模板(MT)嫁接,如图6所示,在先前的RosettaAntibody协议的背景下,此后描述为单模板(ST)嫁接。在RosettaAntibody的第一阶段,MT不是仅创建单一移植结构,而是通过10个最佳匹配(通过BLAST比对)VL-VH定向模板创建10个移植结构。此外,为了使移植结构多样化,我们在所有方向模板对之间强制执行最小OCD截止值0.5,拒绝具有较低OCD的候选模板到10中的任何一个,并用下一个最佳BLAST匹配替换它们。选择10号和0.5 OCD截止值以捕获我们的校准组中的所有靶标中的近乎天然的VL-VH方向,即11种AMA-II抗体,同时最小化冗余模板的数量。每个移植结构在多个独立的RosettaAntibody细化运行中进行细化,以创建候选结构池:来自共享的ST / MT移植结构的1000个,以及来自剩余的9个MT移植结构的200个。

Flow chart for the RosettaAntibody protocol. The grafting phase is shown in blue and pink, above the solid gray line, while the refinement phase is shown in green and gold, below the solid gray line. Steps from the standard ST grafting protocol are colored in blue and green. New steps added to create the MT grafting protocol are colored in pink and gold and enclosed in the dashed gray box; the blue/green ST steps are also part of the MT protocol.
为了评估MT移植的取样效率,我们比较了来自蛋白质数据库(PDB)的46个高分辨率,人工策划的抗体晶体结构的基准组的ST和MT RosettaAntibody的性能(Berman等,2000)。 图7显示了所有目标的ST和MT预测之间的OCD值的成对比较。 在RosettaAntibody的移植阶段,ST VL-VH方向预测仅在26%(12/46)的靶标中在天然的2.0 OCD内。 MT的预测几乎增加了两倍,在目标中72%(33/46)的原生态2.0 OCD范围内的MT预测中最佳匹配。 此外,在剩余的13个目标中,10个显示出改进的OCD与天然的最佳MT预测相比ST预测。

Comparison of VL–VH orientation prediction performance between MT RosettaAntibody and ST RosettaAntibody after the grafting stage for the 46 members of the benchmark set. The OCD between the native structure and the ST post-grafting stage structure is plotted against the lowest OCD between the native and any of the 10 MT post-grafting stage structures. Targets where the best MT structure is the same as the ST structure appear on the x = y line also plotted. Targets where the best MT structure has a closer OCD to native than the ST structure are above the x = y line. MT success cases (OCD ≤ 2.0) are found to the left of the vertical OCD = 2.0 line, while MT failures (OCD > 2.0) are found to the right. Likewise, ST success cases are found below the horizontal OCD = 2.0 line, while failures are found above. The green points indicate the 21 targets that improved from a failure case to a success case when using the MT protocol, while blue points indicate the 12 targets that remained successes, and the red points indicate 10 of the 13 targets that remained failures (the other three have OCD values exceeding the bounds of the plot).
在RosettaAntibody精修阶段(包括H3重塑和VL-VH重定向)之后,MT协议在46个目标中的43个(93%)中产生比ST协议在2.0 OCD内更多的候选结构(图8a)。其余三个目标都具有较差的预测嫁接结构库,其中10个MT预测(包括ST预测)中没有一个比天然的15.0 OCD更接近(补充数据,表SIII)。虽然MT协议在2.0 OCD下产生了更多的情况,但是在计算时间的比例成本(整个MT协议的~1440CPU小时)下,每个目标需要更多的总候选结构,2800对1000。为了评估ST和MT协议的候选结构等效性能,我们仅比较了1000个得分最低的MT候选结构与1000个ST候选结构;这将在下文中描述为偏置MT(bMT)协议。此外,为了更公平地评估ST和MT协议的时间等效性能,我们还将MT协议的输出削减为每个目标1000个随机选择的候选结构,尽可能保持输入结构的5:1比率;这将在下文中描述为减少的MT(rMT)协议。
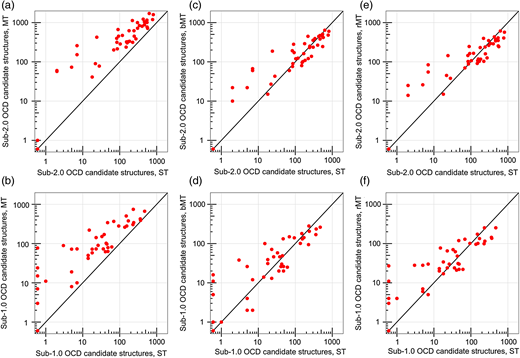
Performance of the full ST, MT, bMT and rMT RosettaAntibody protocols on the 46 benchmark antibodies, showing the number of candidate structures with an OCD value below 2.0 (a, c and e) or below 1.0 (b, d and f) for the ST protocol versus the MT (a and b), the bMT (c and d) and the rMT (e and f) protocols. The ST, the bMT and the rMT protocols each include 1000 candidate structures in total, while the MT protocol includes 2800 candidate structures.
bMT协议为22个目标产生了更多的亚2.0 OCD候选结构,由于稀释效应,20个目标产生比ST协议更少的亚2.0 OCD候选结构(图8c)。同样,rMT协议为20个目标产生了更多的亚2.0 OCD候选结构,并且为22个目标产生了更少的亚2.0 OCD候选结构(图8e)。其余四个目标没有由ST,bMT或rMT协议(补充表SIII)创建的亚2.0 OCD候选结构。当仅计数低于1.0的OCD结构时,那些与天然抗体具有基本相同的VL-VH方向的结构,rMT方案表现更好,其中25个目标在ST计数上有所改善,并且仅有16个从稀释中恶化(图8f)。 bMT方案几乎没有改善,改善了21个目标中的ST计数,达不到18个目标中的ST计数,并且匹配其余3个目标中的ST计数(图8d)。在rMT和bMT协议中几乎所有具有较少低OCD候选结构的目标仍具有至少100个亚2.0 OCD和10个亚1.0 OCD候选结构,然而,表明稀释效应在很大程度上是良性的。
我们将RosettaAntibody的接枝阶段(旧ST协议和新MT协议)与最近发布的VL-VH取向预测器ABangle(Bujotzek等,2015)进行了比较。 公布了AMA-II抗体组的逐坐标坐标ABangle预测结果,允许直接比较两种方法。 ABangle坐标中的四个,HL,dc,LC1和HC1分别直接类似于α,δID,θL和θH。 所有都是使用以相同FV残基为中心的类似参考系来计算的,并且相应的坐标对填充相似大小和形状的天然分布,尽管具有不同的绝对值。 由于这四个ABangle坐标与四个LHOC度量的相似性,可以使用对应于LHOC的四个ABangle坐标中公布的模型到原始偏差来计算OCD值。
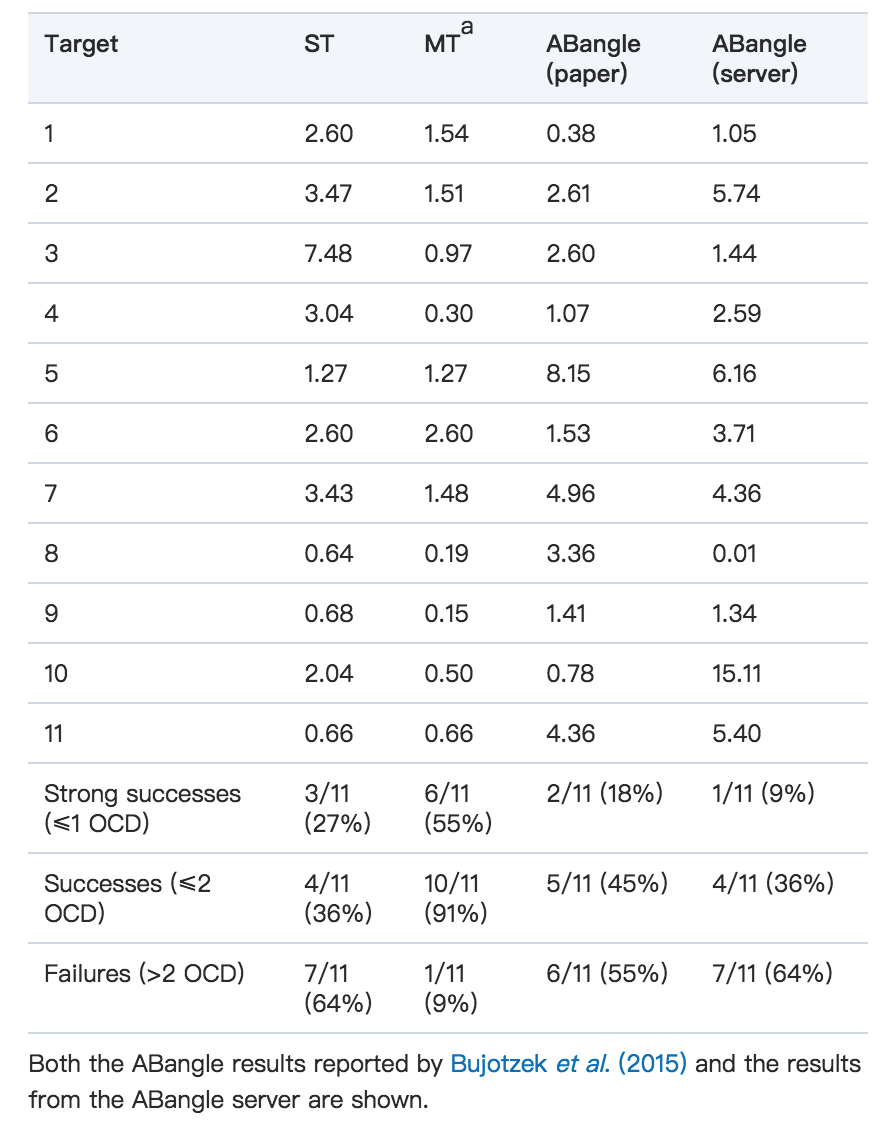
在11个AMA-II抗体靶标中,ABangle实现了5个亚2.0的OCD预测。最初的RosettaAntbody协议(ST)执行类似,如图9a所示,预测11个目标中的4个的亚2.0 OCD结构,并且预测11个目标中的5个目标的OCD优于ABangle的结构。有趣的是,ABangle和ST RosettaAntibody在他们的正确预测中几乎没有重叠,只有一个目标从这两种方法实现了低于2.0的OCD预测。然而,当使用来自MT嫁接预测的10个模型中具有最佳OCD的模板时,RosettaAntibody基本上优于ABangle,如图9b所示。 RosettaAntibody预测了2.0 OCD中的11个目标中的10个,其中包括6个目标,其中ABangle做出了不正确的预测。由RosettaAntibody ST,RosettaAntibody MT(仅最佳预测)和ABangle预测的每种AMA-II抗体靶标的OCD值均由Bujotzek等人报道。 (2015)和ABangle服务器预测的结果如表1所示。每个方案都包括强成功(OCD≤1.0),总成功(OCD≤2.0)和失败(OCD> 2.0)的计数。
Table I. Performance of ST and MT RosettaAntibody and ABangle in capturing VL–VH orientation for the 11 members of the AMA-II antibody set

ST(a)和MT(b)的结果对于AMA-II组的11个成员的移植阶段后的Rosetta抗体与ABangle的预测相比(Bujotzek等,2015)。 在(b)中,仅绘制具有最低OCD的模板; 其他九个MT模板被省略。 线上方的点表示RosettaAntibody模型比ABangle模型更精确的目标,反之亦然。
四、讨论
预测抗体中的VL-VH方向并不是微不足道的,尽管直到最近才对其进行处理,没有人对其进行量化,更不用说明确预测它,直到2010年(Abhinandan和Martin,2010)。确定VL-VH方向的序列信号比非H3 CDR环的保守序列强度低或至少不太清楚。通过VL-VH方向的广泛但细粒度的变化使预测变得更加困难:VL和VH结构域不会整齐地落入离散的规范构象中,并且成功预测的质量不如CDR的那些明显环。因此,明确量化方向是通过定义成功案例来“设定门柱”的重要一步:预测结构和原生结构具有匹配的方向定义。仅具有四维复杂性的新框架LHOC创建了功能上明确的方向定义,其中具有相似LHOC度量的两个结构将总是叠加在其域内结构差异的容差内。
向RosettaAntibody中添加MT移植可提高VL-VH预测。虽然快速rMT协议仅在ST协议上略微增加,牺牲了速度的准确性,但全长MT协议在前一标准上几乎获得了普遍的增益,在我们的基准集中93%的目标中采样取向精确的候选结构。通过包括额外的候选VL-VH供体定向模型,MT RosettaAntibody还使AMA-II基准集内相对于ABangle预测方法的正确预测目标的数量加倍。尽管ABangle的单一预测平均比ST预测更准确,但来自MT RosettaAntibody的10个预测覆盖了更大的构象空间,从而产生更高的保真度预测。 MT RosettaAntibody不一定仅限于使用RosettaAntibody预测;它很容易扩展。诸如ABangle之类的外部预测可以取代10个模板中的一个或者作为第11个模板添加,这可能会进一步提高预测能力。新的MT RosettaAntibody方法的局限性在于它需要更多的计算时间:每次预测需要超过1000个CPU小时
VL-VH取向仅是互补位取向的一部分,但它与其他部分紧密耦合。 提高我们预测VL-VH方向的能力将提高我们预测CDR H3构象的能力,这是抗体同源性建模的一大挑战。 正确的VL-VH方向将H3茎残基置于正确的位置,并且它定义了H3环可以在L链和H链之间折叠的可用空间。 相反,更好的H3预测方法也应该通过限制可以与CDR H3紧密堆积的VL-VH几何结构而有利于方向预测。 最终,在抗体建模中,整体不仅仅是各部分的总和。
参考资料
- 《 Improved prediction of antibody VL–VH orientation 》.2016. 发表于《Protein Engineering, Design & Selection》,2分左右的文章
- https://academic.oup.com/peds/article/29/10/409/2462315
