【4.4.5.1】预测HLA II类限制性T细胞表位的广泛方案的开发和验证(7-allele method)
HLA II类限制性T细胞表位的计算预测在包括疫苗发现在内的许多免疫学研究中具有重要意义。近年来,对HLA II类结合的预测已显着改善,但尚未严格定义全局预测最主要表位的策略。利用与30个不同过敏原(allergens)和细菌抗原上的10个残基重叠的15-mer肽组相关的人类免疫原性数据,以及来自免疫表位数据库和分析资源(IEDB)的HLA II类结合预测工具,我们优化了预测策略人群公认的最高表位。最有效的策略是根据一组七个DRB1和DRB3/4/5等位基因的预测中位结合百分比选择肽。这些结果通过对15种新的过敏原和细菌抗原的盲目预测进行了验证。我们发现需要最高的21%预测肽(基于与七个DRB1和DRB3/4/5等位基因的预测结合)才能捕获50%的免疫反应。这对应于IEDB共识百分等级20.0,可以用作通用预测阈值。使用实际的binding数据(与预测的binding数据相对)并没有明显改变全局预测的功效,这表明不完善的预测能力不是由于算法性能差,而是基于HLAbinding的HLA II类表位预测模式的固有局限性在遗传多样性的人群中
一、前言
HLA II类限制性T细胞表位的预测和鉴定对几种不同的应用具有重要意义。 这些仅举几例,包括阐明导致过敏原特异性T细胞诱导的抗原决定基,研究针对具有大基因组的复杂病原体(例如结核分枝杆菌(MTB))的免疫应答,鉴定和去除蛋白药物中不需要的抗原决定簇的努力。
II类分子是由人类中的四个不同基因座DRA/ DRB1,DRA/DRB3/4/5,DPA/DPB和DQA/DQB编码的α/β异二聚体。除了DRA以外,所有其他链都是高度多态的(Robinson等,2003)。普通人群中HLA II类分子的广泛多态性确实代表了表位识别方法的巨大障碍。但是,已经认识到,通过关注最常表达的分子,可以将一般人群中表达的大多数分子协调为可管理的数量(McKinney等人,2013)。同时,在由不同等位基因变体结合的肽中甚至在不同基因座之间都存在广泛的相似性(Greenbaum等,2011)。最后,也许是最重要的是,已经证明能够结合多个HLA II类分子的肽(即混杂肽)通常占很大一部分,即使不是大多数,也都属于抗原特异性T细胞应答(Oseroff等,2010) ; Paul等,2013a)。
MHC结合能力的生物信息学预测已被证明是各种表位鉴定方法的关键组成部分。尽管历史上不如HLA I类令人印象深刻,但由于采用了更加新颖和复杂的计算方法,过去几年来预测HLA II类结合肽的各种方法的性能已得到了显着改善,在一些研究中进行了回顾和评估(Paul等,2013a; Nielsen等,2010; Wang等,2010)。然而,迄今为止,定义使用这些算法以有效预测混杂II类限制性T细胞表位,或在近亲队列(outbred cohort)中经常识别的显性表位的最佳策略是困难的。
在过去的几年中,我们已经获得了人的T细胞识别数据,这些数据涵盖了几组完全跨越整个免疫学抗原的重叠肽。这些抗原包括四种屋尘螨过敏原(称为HDM数据集)(Hinz,D。,准备中),与花粉过敏(TG)相关的十种过敏原(Oseroff等,2010),四种被健康人识别的MTB抗原。来自圣地亚哥地区(TB-SD)的潜在MTB感染(LTBI)的供体(Arlehamn et al。,2012),以及来自开普敦(南非)地区的LTBI健康供体识别的11种不同的MTB抗原(TB- CT)(Mc Kinney,D。,正在准备中)。在20-40个不同种族的HLA类型个体中,使用相似的方法测试了每组肽。总体而言,在涉及95个以上供体的研究中,总共测试了1151个肽段。
在本研究中,我们已利用这些数据集来评估实现HLA结合预测的不同策略,以选择具有引发HLA II类限制性T细胞免疫反应能力的表位。 为了验证本文定义的方法,随后使用跨越六种不同蟑螂(cockroach)过敏原的重叠肽组(Oseroff等人,2012; Dillon,)和 咳嗽(百日咳杆菌)(疫苗中包含的五种抗原进行了独立盲法分析Dillon,M,准备中)。
二、材料和方法
2.1 免疫原性研究
如先前所述(Oseroff等,2010; Arlehamn等,2012; Oseroff等,2012),对跨越各种病原体和细菌抗原的15或16-mer重叠肽组进行免疫反应性筛选。 供体外周血单核细胞(PBMC)中抗原特异性细胞因子的产生是通过双或单ELISPOT分析进行测量的。 在用各自的过敏原提取物进行体外刺激后,测量对蒂莫西草,蟑螂和屋尘螨肽的响应,并在用相应的疫苗抗原刺激后,对百日咳博德特氏菌肽进行响应。 离体分析对分枝杆菌抗原的反应。 肽特异性反应表示为斑点形成细胞(SFC)/ 10^6 PBMC。 通过SSO / SSP HLA分型(一种Lambda试剂,Canoga Park,CA,美国)或深度测序方法(McKinney等,已提交)在每个II类基因座将供体HLA分型至四位数的分辨率。
2.2 MHC纯化和结合测定
通过实验确定了TG和TB-SD数据集中的肽与26个最常见等位基因的结合亲和力。基于竞争性测定,基于对高亲和力放射性标记的肽与纯化的MHC分子的结合的抑制,对HLA II类分子的肽结合能力进行了定量测量。通过亲和色谱法纯化II类MHC分子,并进行结合测定,其性能基本上已在其他地方进行了详细介绍(Sidney等,2013)。简而言之,将EBV转化的纯合细胞系用作MHC分子的来源。在蛋白酶抑制剂混合物的存在下,将高亲和力放射性标记的肽(0.1–1 nM)与纯化的MHC在室温或37°C共同孵育。孵育两天后,通过在Ab包被的Lumitrac 600板(Greiner Bio-one,Frickenhausen,德国)上捕获MHC /肽复合物,并使用TopCount(Packard Instrument Co.,Meriden, CT)微闪烁计数器。计算了50%抑制放射性标记肽结合的肽浓度。在[标签] b [MHC]和IC50≥[MHC]的使用条件下,测得的IC50值是真实Kd值的合理近似值。在三种不同的独立实验中,以六种不同的浓度(覆盖100,000倍)对每种竞争肽进行了测试。作为阳性对照,在每个实验中还测试了放射性标记探针的未标记形式。
2.3 结合亲和力的预测
- 使用IEDB( www.iedb.org )上提供的MHC II结合预测工具预测了对HLA II类等位基因的肽结合亲和力(Vita等人,2015; Zhang等人,2008; Kim等人,2012) 。
- 利用了IEDB工具查询的所有算法的等位基因特异性共有百分数等级(Wang等,2010)。
- 通过将所选肽的预测结合亲和力与从SWISS-PROT数据库中随机选择的一大组相似大小的肽的预测亲和力进行比较,可生成百分等级(Kim等人,2012)。 百分位数等级提供了一个统一的量表,可以在不同的预测变量之间进行比较。 较低的百分数等级值指示较高的亲和力。 在共识方法的情况下,所涉及的三种方法的百分比等级的中位数被视为IEDB共识百分比等级。
2.4 校正表位冗余 Correction for epitope redundancy
对两个连续肽的反应通常归因于相同的最小表位。 为了避免两次计数相同的表位,将两个相互之间幅度在2.5倍之内的连续反应合并到单个抗原区域中,并使用了较高的SFC值。 如果两个肽中的任何一个都被预测,则认为该区域已成功预测,并且预测的“信用”(credit)仅给出了一次。
三、结果和讨论
3.1 HLA II类表位的最佳预测策略评估
数据集(表1)对先前描述的26种HLA II类等位基因的预测结合亲和力,这些HLA II类等位基因在世界范围内的普通人群中最常见(Greenbaum等,2011)(表2),已通过以下方法确定 。 为了评估采用这些预测来确定最主要的表位反应的各种方法的有效性,每个数据集中的肽百分比(分数)需要捕获总反应的50%(数据中总SFC值的50%, 表示为SFCs/10^6 PBMC)用作性能指标。

作为第一种方法,我们考虑了每种肽的“混杂结合能力”(promiscuous binding capacity),其中混杂是通过结合的等位基因的数目来定义的(即,结合更多等位基因的肽是更加混杂的结合物)。 为此,如果肽的IEDB预测共识百分位数等级≤20,则认为该肽是特定等位基因的结合物。 这种方法最初是由我们根据单个数据集设计的(TG,Oseroff等,2010)。 使用这种方法,如图1a和b所示,平均需要30.91%(范围25.35%-40.08%)的肽才能捕获数据集中总响应的50%。


作为第二种方法,我们考虑了每种肽的“中位共识百分位等级”(median consensus percentile rank),定义为针对26个选定等位基因的预测的IEDB共识百分位等级的中位数。 这种方法是最有效的,最高的26.26%(范围16.90%–38.38%)的肽捕获了总响应的50%(图1a,c)。
3.2 中位数百分等级方法与最佳百分位和等位基因特异性结合阈值的比较
除了混杂的结合能力(混杂)和中位数共识百分位数等级外,还评估了其他策略。 考虑到特定肽的优势可能反映了对给定等位基因非常高的结合亲和力,而不是滥交(promiscuity),我们测试的一种方法基于“最佳百分等级”(best percentile rank)。 在这种方法中,根据最佳百分数等级(在26个最常见的等位基因中最低的百分数等级值)对肽进行分类,并确定捕获50%的总SFC所需的肽百分比。 此方法平均需要27.05%的顶部肽捕获50%的响应。
在另一种方法中,我们遵循了基于等位基因特异性结合亲和力阈值的策略,该策略提高了I类预测的功效(Paul等,2013b)。为了进行此分析,从IEDB中检索了所有先前确定的具有确定的HLA II类限制的15-mer表位。根据SMM_align方法(IC50)(Nielsen et al。,2007)预测的结合亲和力,对26个等位基因中的每一个等位基因特异性阈值进行了估计,同时考虑了从中检索到的表位集合中预测的结合物数量。 IEDB(基于IC50 1000 nM的一般阈值)和SMM_align IC50值划定了同一表位组的前75%肽段。然后根据等位基因特异性阈值重新计算每种肽的总混杂度,并确定捕获50%反应所需的肽比例。此方法需要33.58%的肽才能捕获50%的响应。
发现这两种方法都比中位数共识百分位数秩方法效率低,分别需要平均27.05%和33.58%的肽段(相对于26.26%),才能根据26个最常见的等位基因捕获50%的应答(数据未显示) )。
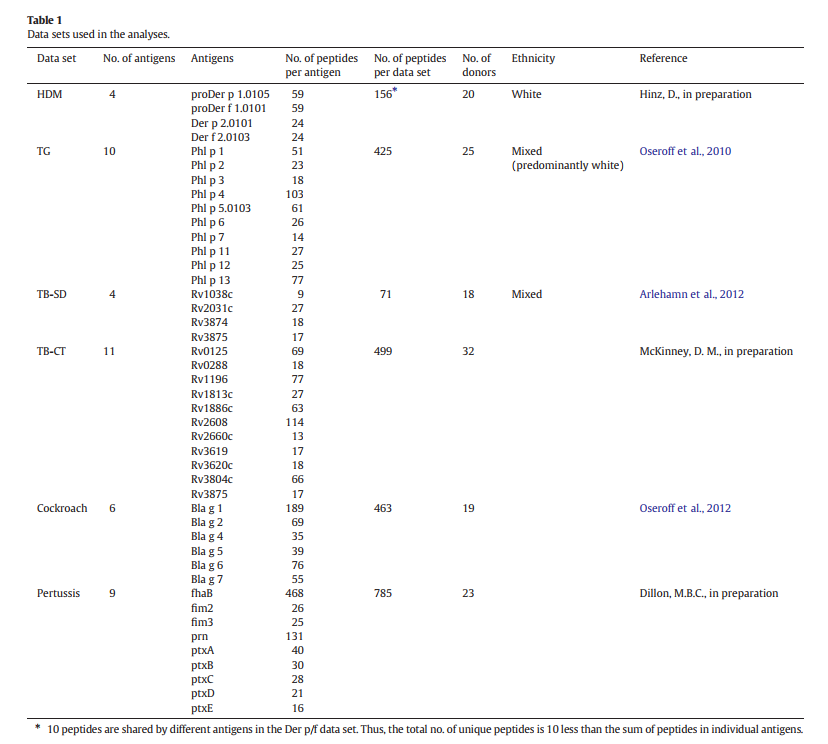
3.3 排除DP位点可提高预测功效 Exclusion of DP locus improves predictive efficacy
由于不同的HLA II类基因座似乎对人类反应的贡献不同(Oseroff等,2010),我们假设检查作为II类基因座功能的表现可能会改善预测。 图2显示了针对DRB1,DRB3 / 4/5,DQ和DP等位基因的不同组合,捕获50%SFC所需的平均肽百分数。图2省略了DP等位基因,可获得最佳结果(23.82%)。 。 掺入DP分子的方法性能较低可能是由于以下事实:
- 这些分子可利用的结合数据较少,导致预测算法较差;
- 或者DP分子较少是限制主要T细胞反应的元件。
3.4 使用一组七个DRB1和DRB3 / 4/5等位基因获得的最佳结果
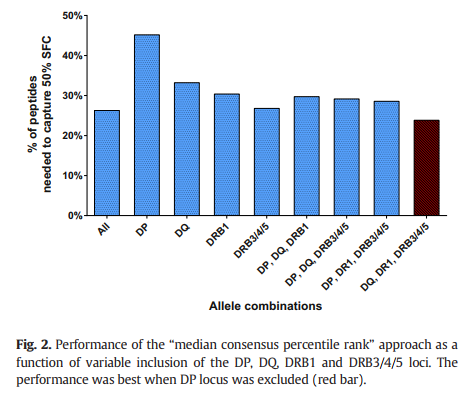
接下来,我们研究了改变预测面板中包含的特定等位基因的影响。 包含的频率阈值针对每个基因位(DQ,DRB1和DRB3 / 4/5)独立变化。 当使用频率≥12%(DRB1 * 03:01,DRB1 * 07:01,DRB1 * 15:01)的三个DRB1等位基因并用时,四个DRB3 / 4/5等位基因(DRB3 * 01:01,DRB3 * 02:02,DRB4 * 01:01,DRB5 * 01:01)(数据未显示),观察到最佳结果(捕获50%SFC所需肽的21.41%) 。 这种经验上的优化可能反映了以下事实:DR等位基因是限制人类HLA II类应答的最主要基因座。 值得注意的是,这七个等位基因变体涵盖了主要的HLA II类超型(Greenbaum等,2011)。
3.5 基于特定供者队列中频繁出现的等位基因的预测
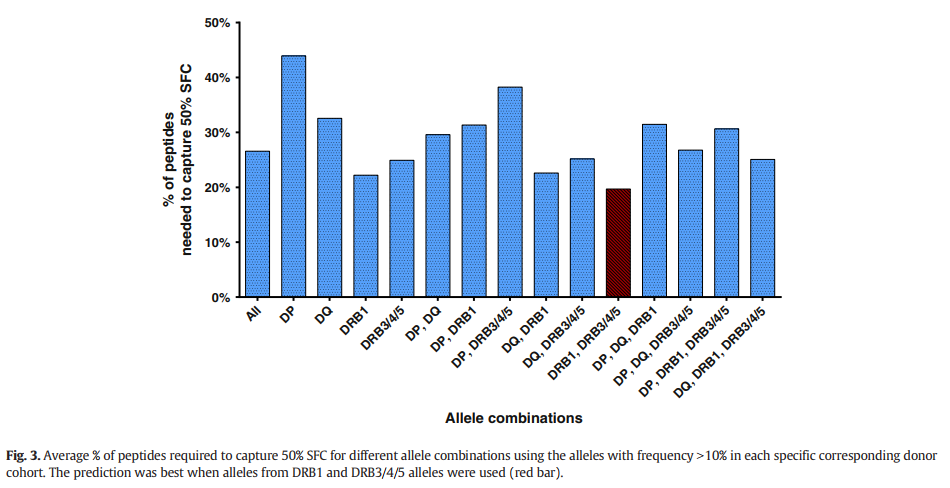
Predictions based on alleles frequent in specific donor cohorts
HLA频率在不同种族的人群中有所不同。 因此,我们利用为测试多肽的人群定制的等位基因,检查了“中位数共识百分等级”预测的性能。 具体而言,我们纳入了给定供体中频率≥10%的所有等位基因。 如上所述,仅使用DRB1和DRB3 / 4/5等位基因可获得最佳结果(19.69%)(图3)。 同时,使用队列特定等位基因组所见的改善很小,这表明根据特定人群定制预测具有有限的价值。
3.6 定义通用预测阈值
当考虑单个肽时,无法获得捕获50%响应所需的总肽百分率(按此处逐个蛋白计算)。 为了得出标准的预测阈值,我们使用了上面突出显示的七个DRB1和DRB3 / 4/5等位基因的预测,计算了IEDB共识百分位数的中位数,该预测与产生50%响应的选定肽段相关。 发现该值为20.0(来自七个选定等位基因的中位共识百分位数等级)。
3.7 使用新数据集进行盲预测的结果验证
上面的分析表明,有效选择抗原决定簇候选物的最佳方法是基于确定选定的七个DR等位基因(3个频率≥12%的DRB1等位基因与4个DRB3 / 4/5结合)的中位共有百分位 等位基因。 为了验证这些结果,我们检查了具有免疫学意义的另外两组蛋白质的重叠肽:1)蟑螂过敏原和2)无细胞百日咳疫苗抗原。
当针对两个盲组实施上述尝试的方法范围时,通过“中位数共识百分等级”方法再次获得了最佳性能。 当使用由(70.0 DR)等位基因组定义的通用中位数IEDB共识百分数阈值(20.0)时,发现中值IEDB共识百分数等级≤20.0的肽捕获的SFC的平均百分比为48.55%,证实了 此预测阈值。
3.8 与实验测量的结合数据比较
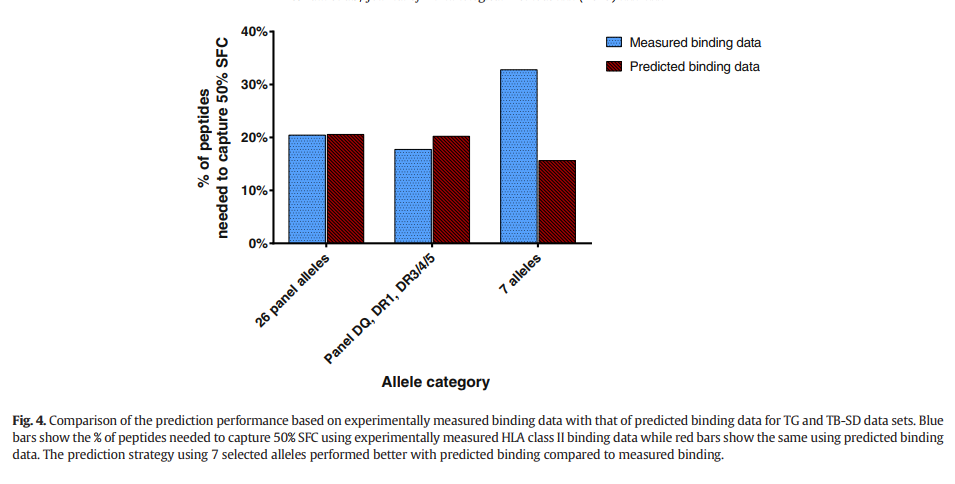
分析表明,平均而言,要捕获50%的免疫反应,大约需要得分最高至约20%的得分肽。为了检查这种数量较高的肽是否是由于HLA II类结合预测算法的较低功效所致,我们将基于预测结合亲和力的性能与实验测得的结合亲和力进行了比较。对于该分析,在两个队列(TG和TB-SD)的背景下评估了对七个选定的DR等位基因的预测和测量的结合亲和力。
已经发现,与测得的结合亲和力相比,基于预测的结合亲和力的肽选择策略实际上需要较少的肽来捕获50%的免疫应答(15.63%比32.86%的肽)(图4)。当使用来自其他两个等位基因类别的结合数据(最常见的等位基因和不包括DP基因座的等位基因)时,未观察到显着差异。这表明,预测HLA II类免疫原性的总体效率较低是II类等位基因固有的问题,而不是HLA II类结合预测算法的性能不足。
四、结论
我们审查了HLA II类结合预测的使用,以鉴定具有高免疫活性的表位集。结果证实了以前的观察结果,即混杂的粘合剂占总响应的很大一部分。但是,与HLA I类预测相比,结果令人震惊,因为整体性能明显较差。这与其他最近的研究相一致(Chaves等,2012)。我们考虑了这些结果可能归因于II类结合预测算法总体性能较低的可能性。然而,当使用实际的结合数据而不是预测的结合数据时,没有发现明显的改善。这些结果表明,不完善的预测能力是由于在遗传多样的人群中基于HLA结合的HLA II类表位预测方案的固有局限性所致。
同时,我们的结果为预测的实际实施提供了指导,并确定了预测方案最有效考虑的HLA分子的特定子集。一组由10个残基重叠的15-mer肽组中大约20%的肽合成允许用8个肽覆盖200个残基的蛋白质(否则被38个重叠的肽所覆盖),这仍然可以节省大量成本,并且可以基于预测的表位肽库的实验设计筛选大型基因组。
批注
- 这个50% SFC作为评价预测效果的没有太明白,后续再来研究吧。
参考资料
- Paul et. al: Development and validation of a broad scheme for prediction of HLA class II restricted T cell epitopes, Journal of Immunological Methods, 2015, 422, 28-34 铁汉 10:09:35 http://tools.immuneepitope.org/CD4episcore/
