【4.1】基于AI预测组合药物副作用
这是一篇文献翻译,因为觉得这个工作很有意思,又是第一次接触,干脆就翻译了一下这篇文献
- 文献: Modeling polypharmacy side effects with graph convolutional networks
- 软件地址: https://github.com/marinkaz/decagon
摘要
使用多种药物的组合来治疗复杂疾病越来越常见。然而,多种药物对患者产生不良副作用的风险比单一用药要高得多。但药物相互作用的知识通常是有限的,并且通常在相对较小的临床试验中有可能没有观察到。因此,发现多种药物副作用仍然是一项重要挑战,对患者死亡率和发病率具有重要意义。
斯坦福大学今年8月份发表的一个基于AI技术种模拟多种药物副作用的方法,该方法取名Decagon。该方法构建了蛋白质-蛋白质相互作用,药物-蛋白质靶标相互作用和多种药物副作用的多模式图。该方法开发了一种新的图卷积神经网络,用于多模态网络中的多关系链路的预测。Decagon准确预测多种药物的副作用,比其他预测软件表现高达69%。如果模型中能增加药物的剂量水平,模型的预测水平应该能有所提升。
我们发现它自动学习表示患者多种药物共存的副作用的表示。此外,Decagon模型特别好,具有强大的分子基础的多种药物副作用,而主要是非分子副作用,由于跨边缘类型的模型参数的有效共享,它实现了良好的性能。 Decagon通过正式的药理学研究开辟了利用大型药物基因组学和患者人群数据来标记和优先考虑多种药物副作用以进行随访分析的机会。
一、前言
大多数人类疾病是由对任何单一药物的活性具有抗性的复杂生物过程引起的(Jia等,2009; Han等,2017)。一种有前途的抗击疾病的策略是多种药物,一种组合疗法,涉及同时使用多种药物,也称为药物组合(Bansal等,2014)。药物组合由多种药物组成,每种药物通常用作患者群体中的单一有效药物。由于药物组合中的药物可以调节不同蛋白质的活性,因此药物组合可以通过克服潜在生物过程中的冗余来提高治疗效果(Sun等人,2015)。例如,最近已显示Venetoclax和Idasanutlin的药物组合在治疗急性髓性白血病中具有优异的抗白血病功效(Pan等,2017)。在这里,两种药物以相互作用的方式起作用:Venetoclax抑制抗细胞凋亡的Bcl-2家族蛋白,而Idasanutlin激活p53途径,因此,这两种药物的组合通过同时靶向互补机制提高了存活率(Pan et al。,2017)
虽然多种药物的使用可能是治疗许多疾病的良好实践(Liebler和Guengerich,2005; Tatonetti等,2012),但多重药物对患者的主要后果是副作用的风险要高得多。 由于药物相互作用。 多药副作用很难手动识别,因为它们很少见,实际上不可能测试所有可能的药物对,并且通常在相对较小的临床试验中没有观察到副作用(Bansal等,2014; Tatonetti等,2012)。 此外,多种药物被认为是影响近15%美国人口的医疗保健系统中日益严重的问题(Kantor等,2015),并且美国每年花费超过1770亿美元用于治疗多种药物副作用(Ernst和 Grizzle,2001)。
可以进行体外实验和临床试验以确定药物 - 药物相互作用(Li等,2016; Ryall和Tan,2015),但药物 - 药物相互作用候选物的系统组合筛查仍然具有挑战性且昂贵(Bansal等, 2014)。因此,研究人员试图从科学文献和电子病历中收集药物 - 药物相互作用(Percha等,2012; Vilar等,2017),并通过网络建模,分子目标特征分析发现它们(Chen等。,2016a; Huang et al。,2014b; Lewis et al。,2015; Sun et al。,2015; Takeda et al。,2017),基于统计关联的模型和半监督学习(Chen et al。,2016b) ; Huang et al。,2014a; Shi et al。,2017; Zhao et al。,2011)(参见第7节的相关工作)。虽然这些方法可用于推导用于描述细胞水平的药物相互作用的广泛规则,但它们不能直接指导药物组合治疗的策略。特别地,这些方法通过表示相互作用的总体概率/强度的分数来表征药物 - 药物相互作用,但是不能预测副作用的确切类型。更确切地说,对于药物i和j,这些方法预测它们的组合是否产生任何夸大的响应Sij超过无相互作用下预期的加性反应,无论确切的类型或副作用的数量。也就是说,他们的目标是回答一个问题:Sij ≠{},其中Sij是特定于药物对i,j的所有多种药物副作用的集合,但不是单独使用任何一种药物。然而,回答一对药物i,j是否与r,r2型的给定副作用相互作用更为重要和有用。尽管确定精确的多种药物副作用对于改善患者护理至关重要,但仍然是一项尚未通过预测模型研究的具有挑战性的任务。
1.1 目前的研究
在这里,我们开发了Decagon,一种预测药物副作用的方法。 我们通过构建蛋白质 - 蛋白质相互作用,药物 - 蛋白质相互作用和药物 - 药物相互作用(即副作用;图1)的大型双层多模态图来模拟该问题。 每种药物 - 药物相互作用都用不同的边缘类型标记,这表示副作用的类型。 然后,我们开发了一种新的多关系边缘挖掘模型,该模型使用多模态图来预测药物 - 药物相互作用及其类型。 我们的模型是卷积图神经网络,在多关系设置中运行。
为了激励我们的模型,我们首先进行探索性分析,得出两个重要的观察结果(第3节)。 首先,我们发现共同处方药物(即药物组合)倾向于比随机药物对具有更多共同的靶蛋白,这表明药物 - 靶蛋白信息包含用于药物组合建模的有价值的信息。 其次,我们发现重要的是要考虑蛋白质 - 蛋白质相互作用的图谱,以便能够模拟具有共同副作用的药物的特征。 这些观察结果促使Decagon的发展,以预测哪些药物对将相互作用,以及相互作用/副作用的确切类型是什么(第4节)
Decagon开发了一种新的图形自动编码器方法(Hamilton et al。,2017a),它允许我们在多模态图上开发用于链路预测的端到端可训练模型。相比之下,以前基于图的生物学中的链接预测任务方法(例如Chen等人2016b; Huang等人2014b; Zong等人2017)采用两阶段管道,通常由图形特征提取模型和链接预测模型,两者都是单独训练的。此外,Decagon的关键区别特征是多关系链接预测能力,允许我们捕获不同边缘(副作用)类型的相互依赖性,并识别图中任何两个药物节点之间存在哪些可能的边缘类型。这与用于简单链接预测的方法(Trouillon等人,2016)形成鲜明对比,其预测仅存在节点对之间的边缘,并且对于建模大量不同的边缘/侧面效应类型也是关键的。
我们将Decagon的表现与多关系张量因子分解的最新方法(Nickel等,2011; Papalexakis等,2017),图表上的表示学习方法(Perozzi et al。,2014; Zong)进行了对比。 et al。,2017)和已建立的用于链接预测的机器学习方法,我们适用于多种药物副作用预测任务。 Decagon的表现优于其他方法高达69%,预测性能平均增加20%,具有强大分子基础的副作用类型获得更大的收益(第6节)。 对于一些新的预测,我们在生物医学文献中找到了支持性证据,表明Decagon在识别极有可能是真阳性的预测方面表现得特别好。 总之,这项研究首次显示了模拟药物组合副作用的能力,并开辟了组合药物开发的新机会。
二、数据集
我们在两种多模式图形/两种节点类型的网络中制定了多种药物副作用识别问题的多关系链接预测问题:药物和蛋白质。我们构建如下的双层多模态网络(图1)。 蛋白质 - 蛋白质相互作用网络描述蛋白质之间。 药物 - 药物相互作用网络包含964种不同类型的边缘(每种副作用类型一种)并描述哪些药物对导致哪些副作用。 最后,药物 - 蛋白质链接描述了给定药物靶向的蛋白质。 我们继续描述用于构建网络的数据集。 所有数据集的预处理版本可通过本研究的网站获得:http://snap.stanford.edu/decagon
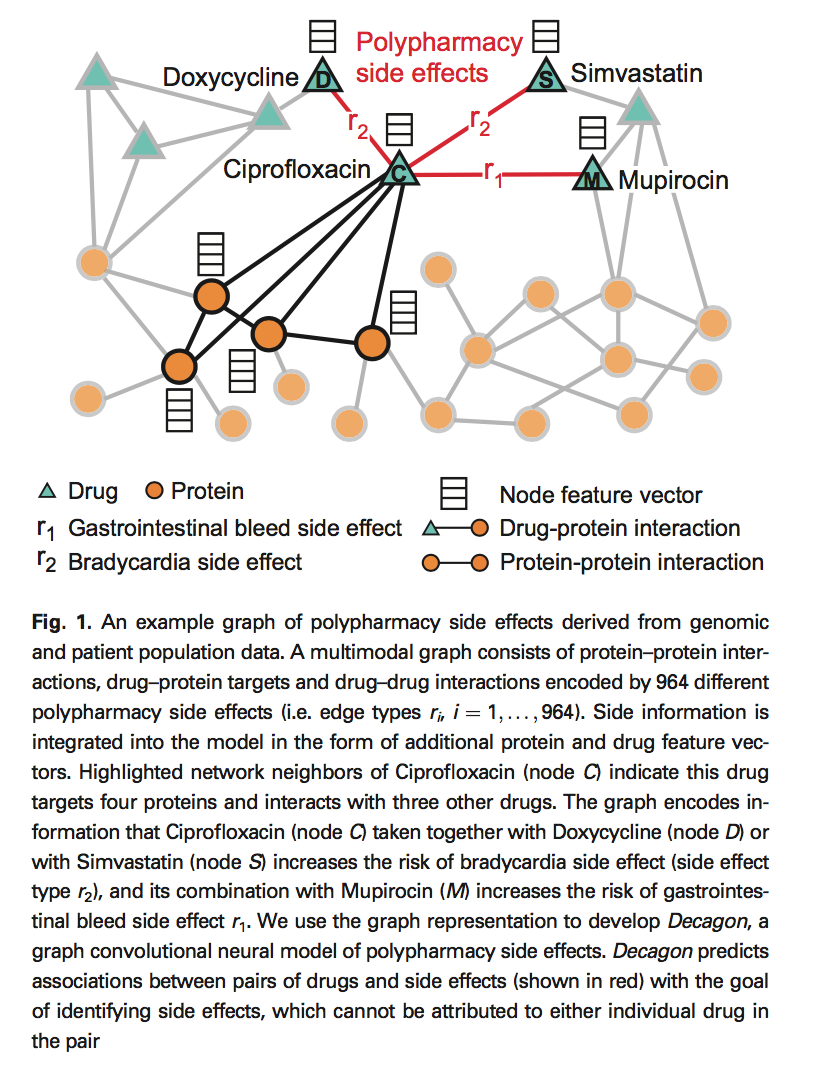
2.1 蛋白质 - 蛋白质和药物 - 蛋白质相互作用
我们使用由Menche等人(2015)和Chatr-Aryamontri等人(2015)编制的人类蛋白质 - 蛋白质相互作用(PPI)网络,与来自Szklarczyk等人(2017)和Rolland等人(2014)的其他PPI信息相结合。 该网络包含在人体中实验记录的物理相互作用,例如代谢酶偶联相互作用和信号传导相互作用。 该网络未加权且无向导,具有19 085种蛋白质和719 402物理相互作用。
我们从SOTCH(化学物质的相互作用搜索工具)数据库中获得了蛋白质和药物之间的关系,该数据库整合了各种化学和蛋白质网络(Szklarczyk等,2016)。 对于这项研究,我们只考虑了小化学品(即药物)和经过实验验证的目标蛋白质之间的相互作用。 在8934种蛋白质和519 022种化学物质之间存在超过8 083 600个相互作用。
2.2 药物相互作用和副作用数据
我们还从数据库中提取了详细说明个别药物和药物组合的副作用。 SIDER(副作用资源)数据库包含286 399种药物副作用关联超过1556种药物和5868种副作用(Kuhn等,2016),通过从药物标签文本中挖掘不良事件获得。我们将其与OFFSIDES数据库整合在一起,该数据库详细说明了1332种药物和10 097种副作用之间的标签外关系(Tatonetti等,2012)。OFFSIDES数据库是使用不良事件报告系统生成的,该系统收集医生,患者和制药公司的报告。我们消除了副作用同义词,并使用一个副作用词汇表来构建所有数据集。预处理很重要,因为如果一些副作用完全相关,预测问题就会容易得多。合并这些数据集后,每种药物的中位数为159副作用,最常见的副作用是恶心,呕吐,头痛,腹泻和皮炎
我们从TWOSIDES中提取了多种药物的副作用信息,其中详细介绍了63 473种药物组合中的1318种副作用类型,考虑到两种药物在单独组合中的作用,这些信息大于预期(Tatonetti等,2012)。 与OFFSIDES一样,TWOSIDES是由不良事件报告系统生成的。 常见的副作用,如低血压和恶心,发生在超过三分之一的药物组合中,而其他如健忘症和肌肉痉挛仅发生在少数药物组合中。 总体而言,它包含4 651 131种药物组合副作用关联。 在这项研究中,我们专注于预测964种常见类型的多种药物副作用,每种副作用发生在至少500种药物组合中。
在连接不同数据库使用的实体词汇后的最终网络具有645个药物和19 085个蛋白质节点,其通过715 612蛋白质 - 蛋白质,4 651 131个药物 - 药物和18 596个药物 - 蛋白质边缘连接。
三、 Data-driven motivation for Decagon approach (Decagon方法的数据驱动)
在这里,我们对双层多模态图(图1)的结构进行了三次观察,这对于Decagon模型的设计具有重要意义。
1.我们观察到药物组合中出现某些副作用的频率范围很广。我们发现 > 53%的多种药物副作用已知在<3%的记录药物组合中发生(例如脑动脉栓塞,肺脓肿,肉瘤,胶原紊乱)。相反,更频繁的副作用(例如呕吐,体重增加,恶心和贫血),更频繁地发生一个数量级。由于每种副作用与药物对的数量差异很大,因此只有有限数量的药物对可用于独立训练模型以预测不同的副作用类型。因此,多种药物副作用预测成为一项具有挑战性的任务,特别是在预测罕见的副作用时,因此开发端到端方法非常重要,这样模型能够共享信息并从所有副作用中学习。
2.我们观察到多药副作用在共同处方的药物对(即药物组合)中不会彼此独立地出现,这表明对多种副作用的联合建模可以有助于预测任务。为了量化副作用之间的共现,我们计算给定副作用与其他副作用共同发生的药物组合的数量,然后使用随机共现的零模型进行置换测试。如表1中的高血压和恶心所示,我们发现大多数最常见的副作用在药物组合中作为副作用与恶心/高血压共同发生的频率显着过多或不足(α=0.05水平)。这一观察指出存在可能导致副作用的共同病理生理学的机制,类似于在疾病合并症中观察到的(Lee等人,2008)。例如,我们发现高血压与焦虑显着共同发生,但伴随发烧的频率低于随机机会(表1)。这些关系适用于副作用数据集。我们得出结论,预测模型应该利用副作用之间的依赖性,并能够重用关于一种副作用的分子基础的信息,以更好地理解另一种副作用的分子基础。

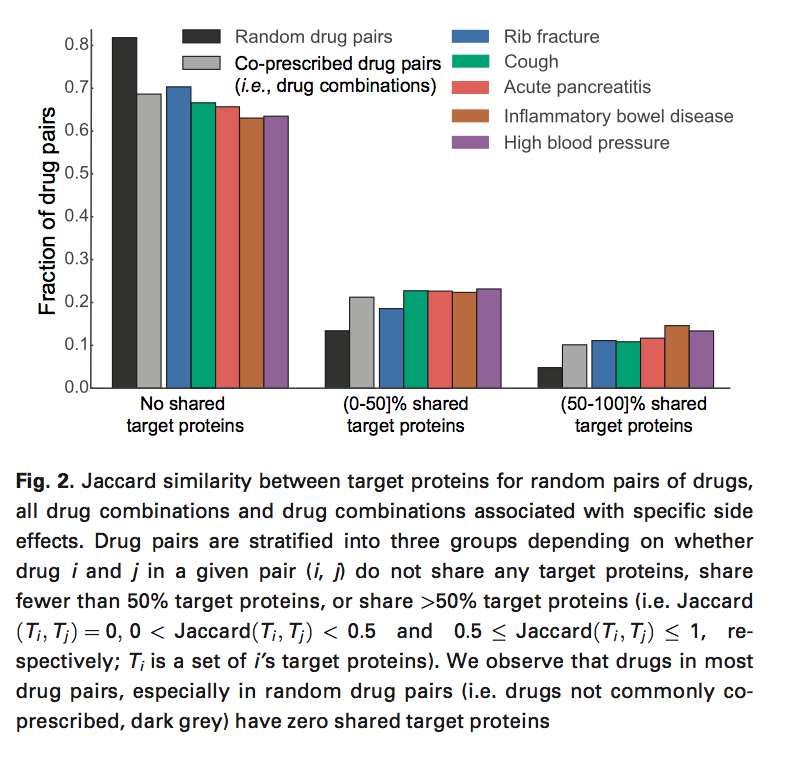
3.我们探讨了药物对靶向蛋白质与副作用发生之间的关系。设Ti代表一组与药物i相关的靶蛋白,然后我们计算给定药物对(i,j)的靶蛋白之间的Jaccard相似性。我们做几点观察:1)超过68%的药物组合共有零目标蛋白,这表明使用蛋白质 - 蛋白质相互作用信息“连接”不同药物靶向的不同蛋白质非常重要。2)随机药物对靶蛋白的重叠小于共同处方药(图2,浅灰色),P值= 5e-120,2样本Kolmogorov-Smirnov(KS)检验。我们发现这种趋势在不同的副作用中得到了不均衡的观察。例如,与共有靶蛋白的药物组合中的高血压比肋骨骨折更强烈地出现。根据双样本KS检验,超过150种副作用出现在组合中,与其他真正的药物组合显着不同(在Bonferroni校正后的α=0.05),表明这些副作用的强分子基础。基于这一发现,我们得出结论,模型考虑蛋白质如何相互作用并能够模拟较长的(间接)相互作用链是很重要的。
四、Graph convolutional Decagon approach 图卷积分Decagon方法
我们将多相药物副作用建模作为一个多关系链接预测问题,在多模态图上编码药物,蛋白质和副作用关系。更准确地说,这些关系用具有N个节点(例如蛋白质,药物)图表G=(V,R)表示,vi∈V,标记的边缘(关系)(vi,r,vj)中r是边类型(关系类型),其代表的信息包括:(i)两种蛋白质之间的物理结合,(ii)药物与蛋白质之间的目标关系或(iii)两种药物之间的特定类型的副作用。如第2节所述,我们考虑药物之间的964种不同关系类型(即副作用)
此外,我们允许以附加节点功能的形式包含辅助信息。 不同节点(药物,蛋白质)可以具有不同数量的节点特征,由实值特征向量X1,X2,… Xn分配给图中的每个节点
多种药物副作用预测任务。多种药物副作用预测任务考虑了识别药物对和副作用之间的关联的问题。重要的是,这些关联仅限于那些不能单独使用这两种药物的关联。使用图G,任务是预测药物节点之间的标记边缘。给定药物对(vi,vj),我们的目的是确定边缘eij=(vi,r,vj)中r属于R的可能性是多,意味着同时使用药物vi和vj [即 药物组合(vi,vj)]的使用与人类患者群体中r型的多种药物副作用有关。
为此,我们开发了一种直接操作的非线性,多层卷积图神经网络模型Decagon 图G. Decagon有两个主要组成部分:
- 编码器:在G上运行的图形卷积网络,为G中的节点生成嵌入(图3A;第4.1节)
- 解码器:使用这些嵌入来模拟多种药物副作用的张量分解模型(图3B;第4.2节)
我们继续描述Decagon,我们用于模拟多种药物副作用的方法.
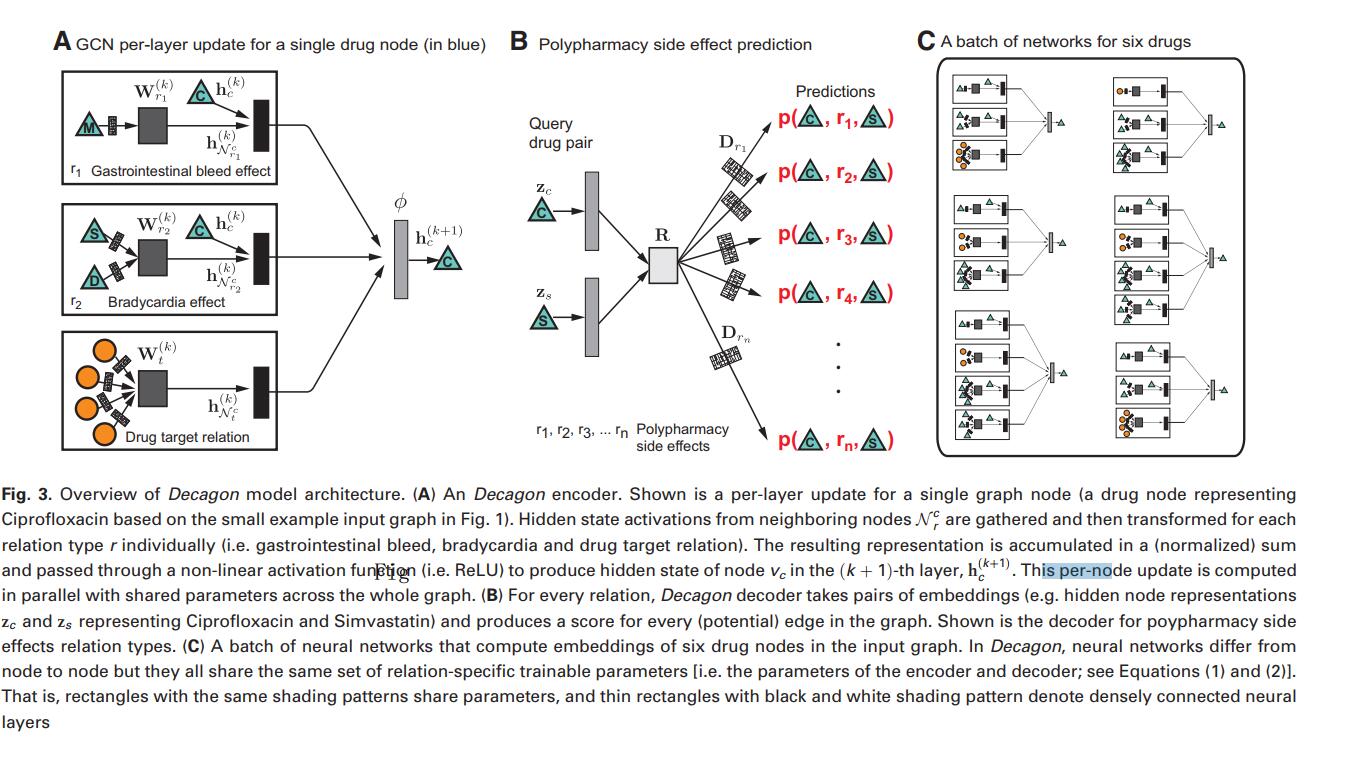
下图其实就是encode和decode的过程。因为药物、副作用、蛋白是一个图形结构的数据,需要将这种图的关系转成特征向量来用于构建模型。A图中,我们可以看到药物C是如何获得其特征向量的;B图中,药物C与药物S通过其特征向量来构建副作用的关系模型
4.1 Graph convolutional encoder
我们首先描述图形编码器模型,其将图G和附加节点特征向量xi作为输入,并且为图中的每个节点(药物,蛋白质)产生节点d维嵌入zi ∈ R。
我们提出了一种编码器模型,它可以有效地利用图中各区域的信息共享,并为每种关系类型分配单独的处理通道。这个想法是Decagon学习如何在图表中转换和传播由节点特征向量捕获的信息。每个节点的网络邻域定义了不同的神经网络信息传播体系结构,但这些体系结构随后共享定义信息如何共享和传播的函数/参数。我们学习卷积运算符,它在图的不同部分和不同的关系类型之间传播和转换信息。该模型的灵感来自最近一类直接在图上运算的卷积神经网络。对于给定节点,Decagon对其邻居的特征向量执行变换/聚合操作。这样Decagon只考虑节点的一阶邻域,并在图中的所有位置应用相同的变换。然后,这些操作的连续应用有效地将信息卷积在K阶邻域上(即,节点的嵌入取决于最多K步距离的所有节点),其中K是神经网络模型神经元中卷积层的连续操作的数量。
在每一层中,Decagon在图的边缘传播潜在的节点特征信息,同时考虑边缘的类型(关系)(Schlichtkrull等,2017)。 该神经网络模型的单层采用以下形式:
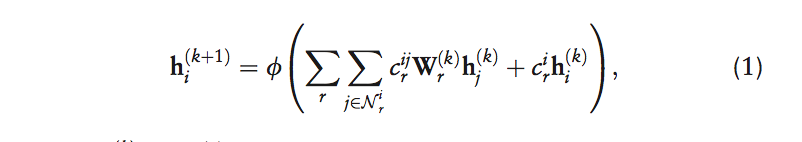
其中 hi(k) ∈ Rd(k) 是神经网络第k层中节点vi的隐藏状态,其中d(k)是该层表示的维数,r是关系类型,矩阵Wr(k)是 关系型特定参数矩阵。这里,Φ表示非线性元素激活函数(即整流线性单位),它转换要在神经模型层中使用的表示,cr(ij)和cri是归一化常数,我们选择对称…….,其中N i r表示关系r下的节点vi的邻居集合。 重要的是要注意,等式(1)中的和仅在给定节点i的邻域N i r上,因此每个节点的计算体系结构(即神经网络)是不同的。图3A示出了来自图1的节点C的每层卷积更新等式(1)的示例。并且,图3C然后说明不同节点具有不同的神经网络结构(因为每个节点的网络邻域不同)。
通过用适当的激活函数链接多个(即K)这些层(图3A),可以构建更深的模型。为了得到节点vi的最终嵌入zi ∈ Rd,我们计算它的表示为:zi = hi(k)。然后整个编码器采用以下形式。我们如等式(1)中所定义地堆叠K层 前一层的输出成为下一层的输入。如果没有特征,则第一层的输入是节点特征向量,hi(0)=xi,或图中每个节点的唯一单热矢量。
4.2 Tensor factorization decoder
到目前为止,我们引入了Decagon的编码器。编码器将每个节点vi∈V映射到嵌入,实值向量表示zi∈ Rd,其中d是节点表示的维度。我们继续描述Decagon的解码器组件。
解码器的目标是通过依赖于学习的节点嵌入并通过不同地处理每个标签(边缘类型)来重建G中的标记边缘。特别是,解码器通过一个函数g给(vi,r,vj)一个得分,其目标是分配一个得分g(vi,r,vj)表示药物vi和vj通过关系/副作用类型r相互作用的可能性(图3B)。使用Decagon编码器返回的节点i和j的嵌入(第4.1节)zi和zj,解码器预测候选边缘(vi,r,vj)通过分解操作:
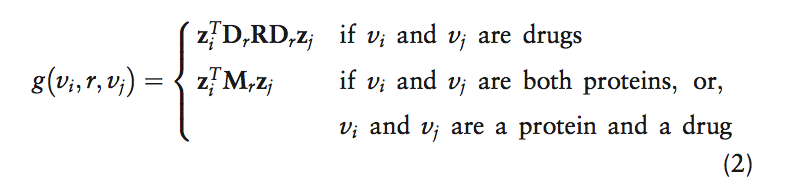
然后应用sigmoid函数r来计算边缘概率
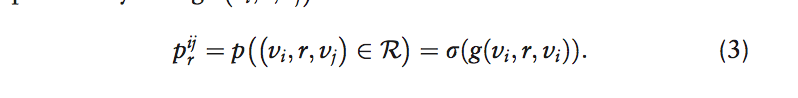
接下来,我们通过区分以下两种情况来解释Decagon的解码器:
1.当vi和vj是药物节点时,等式(2)中的解码器g假设药物 - 药物相互作用的全局模型(即R),其在多种药物副作用中的变化和重要性由副作用特异性对角因子描述(即Dr)。在这里,R是形状dd的可训练参数矩阵,其模拟所有可能的多种药物副作用的全球药物 - 药物相互作用。另外,在Decagon中,代表不同多种药物副作用的每个关系r与对角线dd矩阵相关联,将zi中每个维度的重要性建模为副作用r。在另一种观点中,该解码器可以被认为是三向张量的张量分解[更具体地,rank-d DEDICOM张量分解(Nickel等人,2011; Trouillon等人,2016)],其中 两种模式由药物相同形成,第三种模式具有药物组合的多种药物副作用。然而,Decagon的一个显着特点是对编码器的依赖。经典张量分解使用在训练中直接优化的节点表示,而我们以端到端的方式计算它们,其中节点嵌入与张量因子分解一起被优化。 2. 当vi和vj不是两个药物节点时,等式(2)中的解码器g采用双线性形式来解码来自节点嵌入的边缘。更确切地说,在那种情况下,解码函数g与形状d*d的可训练参数矩阵Mr相关联,其模拟zi和zj中的每两个维度之间的相互作用。然后使用双线性形式(等式2),然后应用S形函数(等式3)来计算预测的边缘概率。
由于以下两个原因,基于等式(2)中的节点类型使用不同的边缘解码器是至关重要的:首先,Decagon解码器可被视为不同关系类型之间的有效参数共享的一种形式。特别地,涉及药物对的关系类型使用相同的全球药物 - 药物相互作用模型(即基质R),其包含在所有药物相关关系类型中保持正确的模式。我们期望这种解码参数化可以减轻罕见副作用的过度拟合,因为参数在罕见(例如,鼓膜炎或鼻息肉)和频繁(例如低血压或贫血)副作用之间共享。第二,我们想要一个高分g(vi,r,vj)表示药物组合(vi,vj)与副作用r之间的关联,其不能仅归因于vi或vj。为了捕捉多种药物组合学(Jia et al。,2009),重要的是Decagon允许通过R在i’s和j’s的嵌入中任意两个维度之间的非零相互作用。
总之,Decagon模型的可训练参数是:(i)关系类型特定的神经网络权重矩阵Wr,(ii) 关系类型特定参数矩阵Mr,(iii)全局副作用参数矩阵R和(iv)副作用特定对角参数矩阵Dr。因此,Decagon编码器和解码器形成了用于多模态图中多关系链路预测的端到端可训练模型(图3)。接下来,我们将描述如何训练Decagon方法。 特别地,我们解释了如何使用端到端学习技术训练神经网络权重和交互参数矩阵。
4.3 Decagon model training
在模型训练期间,我们使用交叉熵损失优化模型参数:
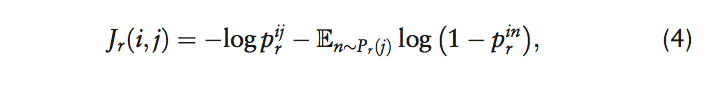
鼓励模型为观察到的边缘(vi,r,vj)比随机非边缘分配更高的概率。与之前的研究一样(Mikolov等,2013; Trouillon等,2016),我们通过负抽样估计模型。对于图中每种药物-药物的边缘(vi,r,vj)(阳性例子),我们通过随机选择节点vn,采样随机边缘(vi,r,vn)(即负例)。其根据采样分布Pr(Mikolov等人,2013)随机选择,通过替换边缘(vi,r,vj)中的节点vj为vn。考虑到所有边缘,Decagon最终的损失函数是:

最近的结果表明,通过端到端学习可以显着改善图形结构数据的建模(Defferrard等,2016; Gilmer等,2017),因此我们采用端到端的优化方法和通过Decagon的编码器和解码器共同优化所有可训练参数并传播损耗函数梯度。为了优化模型,我们使用Adam优化器(Kingma和Ba,2014)训练它最多100个时期(训练迭代),学习率为0.001,窗口大小为2,提前停止,即如果验证损失不会连续两个时期减少。我们使用Glorot和Bengio(2010)中描述的初始化初始化权重,并相应地规范化节点特征向量。为了使模型很好地推广到未观察到的边缘,我们将常规丢失(Srivastava等,2014)应用于隐藏层单元(等式1)。在实践中,我们使用有效的稀疏矩阵乘法,其中G的边缘数量具有线性复杂度,以实现Decagon模型。
我们通过对等式(5)中的损失函数的贡献进行采样来使用迷你批处理。也就是说,我们处理多个训练微型计算机,每个微型计算机通过从等式(5)中的边缘总和中仅采样固定数量的贡献而获得,从而产生动态批次的计算图形(图3C)。通过仅考虑对损失函数的固定数量的贡献,我们可以移除当前小批量中不出现的各个数据点。这可以作为正规化的有效手段,并且减少了训练模型的内存需求,这是必要的,这样我们就可以将整个模型融入GPU内存(所有数据和代码都在项目网站上发布)。
5 Experimental setup
我们将预测多种药物副作用的问题视为解决多关系链接预测任务。这里,每个药物对通过零,一种或更多的来自一组关系类型(即所有副作用类型,参见第2节和图1)关系类型(即副作用类型)连接。
对于每种多种药物副作用类型,我们将与该副作用相关的药物对分成训练,验证和测试集,确保验证和测试集各自包含10%的药物对。对于每种副作用类型,我们使用80%的药物对来训练模型,并使用10%的药物对来选择模型参数。然后,任务是预测与每种副作用类型相关的药物对。请注意,我们非常小心,折叠之间存在信息泄漏,并且交叉验证是公平的。
我们应用Decagon,对于每个药物对和每种副作用类型计算给定药物对与给定副作用相关的概率。另外,我们将副作用信息(即单个药物的副作用(第2节))以药物节点i的附加特征xi的形式整合到模型中。为防止评估中出现任何循环和信息泄漏,我们确保:
i.我们预测的副作用是真正的多种药物副作用(即给定的多种药物副作用仅与药物对相关,而不与药物对中的任何个体药物相关) ii.我们预测的无副作用类型 包括在侧面功能中。
例如,恶心是一种多种药物的副作用,因此我们将所有恶心事件作为个别药物的副作用。 我们注意到这是一种保守的方法,它使我们能够可靠地估计预测性能
我们不知道为预测药物副作用而开发的任何其他方法。 因此,我们根据以下多关系链接预测方法评估Decagon的性能:
- RESCAL张量分解(Nickel et al。,2011):这是一种考虑多关系结构的张量分解方法。 给定Xi,一种编码药物对与副作用r的关联,基质Xi被分解为:Xr = A Tr AT,r = 1;2;。。。; 964,其中Tr和A是模型参数。 给定药物i和j,它们与r的关联预测为:ai Tr aj
- DEDICOM张量分解(Papalexakis等,2017):这是一种适用于稀疏数据设置的相关张量分解方法。 给定的药物 - 药物矩阵Xi被分解为:Xr = A Ur T Ur A T。 给定药物i和j,它们与r的关联预测为:ai Ur T Ur aj。
- DeepWalk神经嵌入(Perozzi等,2014; Zong等,2017):该方法基于探索节点网络邻域的偏向随机游走过程来学习节点的d维神经特征。 药物对通过连接学习的药物特征表示来表示,并用作逻辑回归分类器的输入。 对于每种链接类型(即副作用类型),我们训练单独的逻辑回归分类器
- 连锁药物特征:该方法基于药物 - 靶蛋白相互作用基质的PCA表示并基于PCA表示单个药物的副作用,构建每种药物的特征向量。 药物对通过连接相应的药物特征向量来表示,并用作梯度增强树分类器的输入,然后预测一对药物的确切副作用
使用具有对候选参数值的网格搜索的验证集来确定每个方法的参数设置(例如,对于梯度增强树,所使用的树的数量从10到100变化)。 如果方法不是多关系链接预测方法,我们为每个副作用类型单独选择验证集上具有最佳性能的参数。 具体来说,Decagon使用的是一个2层神经结构,d(1)= 64,每层d(2)=32个隐藏单位,droout rate为0.1,所有实验中的小批量大小为512。
使用接收器操作特性(AUROC)下的面积,精确调用曲线(AUPRC)下的面积和50(AP @ 50)的平均精度,每个副作用类型单独计算性能。 值越高表示性能越好。
六、结果
Decagon运行在多模态图和高度多关系设置。 这种灵活性使Decagon特别适合预测药物对的副作用,我们将在下面讨论。
6.1多种药物副作用的预测
我们首先将Decagon的性能与替代方法进行比较。 从表2中的结果可以看出,考虑到多模态网络表示和建模大量不同的副作用,Decagon能够大幅超越其他方法。 在964种副作用类型中,Decagon的表现优于其他方法19.7%(AUROC),22.0%(AUPRC)和36.3%(AP @ 50)。 相对于张量分解方法,Decagon的改进特别明显,其中Decagon超过基于张量的方法高达68.7%(AP @ 50)。这一发现凸显了直接优化张量分解的潜在局限性[即 vanilla RESCAL和DEDICOM(Nickel et al。,2011; Papalexakis et al。,2017)],不依赖于图形结构的卷积编码器。 我们还将Decagon与其他两种方法进行了比较(Perozzi等,2014; Zong等,2017),我们将其用于多关系链接预测任务。 我们观察到DeepWalk神经嵌入和连锁药物特征比基于张量的方法获得9.0%(AUROC)和20.1%增益(AUPRC)。然而,这些方法采用两阶段管道,包括药物特征提取模型和链接预测模型,两者都是单独训练的。此外,他们不能考虑我们展示的包含有用信息的不同副作用的相互依赖性(第3节)。 这些额外的建模见解使Decagon在DeepWalk神经嵌入方面获得了22.0%的增长,在AP @ 50分数中获得了超过12.8%的连锁药物特征。
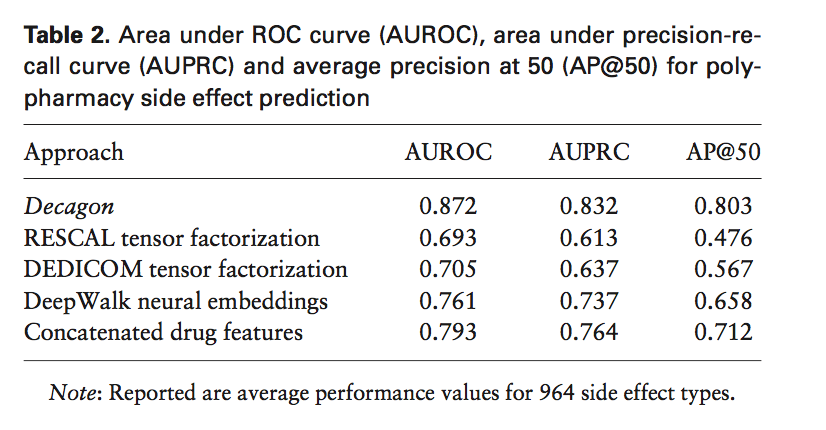
这些发现与结果一致,通过end-to-end学习,特别是使用图形自动编码器,预测通常可以得到显着改善(Hamilton et al。,2017a,b; Kipf and Welling,2016)。 特别是,张量分解和神经嵌入基线方法允许我们量化嵌入(即Decagon的编码器)导致性能改进的百分比以及多任务学习的百分比(即Decagon的解码器)
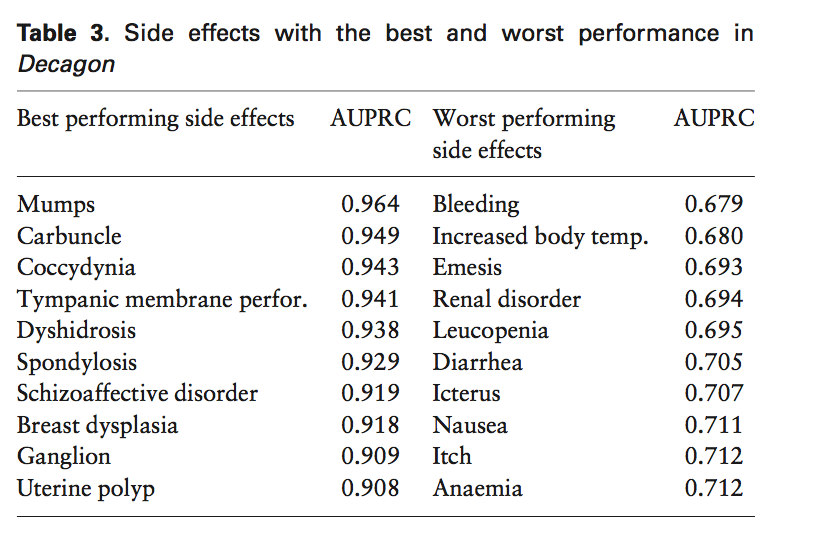
为了更好地理解Decagon的表现,我们按副作用类型对表2中的汇总统计量进行了分层。 对结果的人工检查和与领域专家的讨论揭示了表3中表现最佳副作用的共同特性。我们观察到Decagon模型具有特别好的副作用,具有强烈的表观分子基础。 这一观察结果与我们的预期一致,因为Decagon的多模式图(图1)主要包含药物基因组学信息。 我们还观察到,性能最差的副作用往往是常见的副作用和/或具更多的受环境和行为习惯影响而非分子起源(表3)。 Decagon在这些副作用方面的竞争表现可以通过在不同类型的副作用中有效共享模型参数来解释。
6.2对Decagon新颖预测的调查
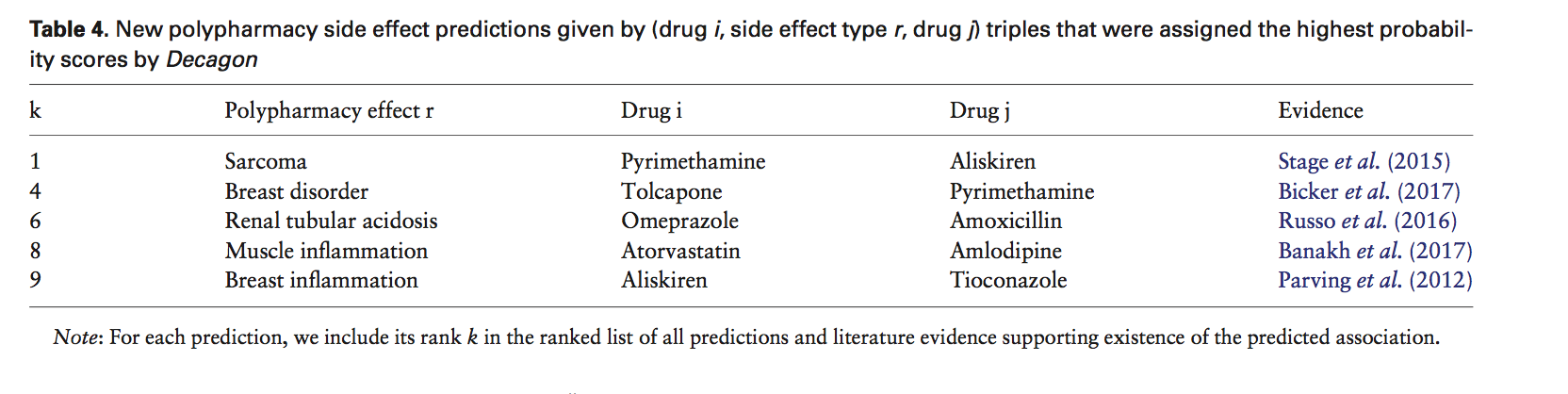
接下来,我们对发现的结果进行基于文献的评估。 我们的目标是评估Decagon对副作用和药物对之间关系的新预测的质量。 为此,我们要求Decagon对数据集中的每个药物对和每种副作用类型进行预测。然后,我们使用这些预测来构建(药物i,副作用类型r,药物j)三元组的排序列表,其中三元组按预测概率分数pij r(等式3)排序。 然后,我们从排序列表中排除药物对和副作用之间的所有已知关联,然后调查列表中排名最高的10个预测。 为了防止调查偏倚的风险,我们不允许在分析的不同阶段之间存在任何串扰。 然后,我们搜索生物医学文献,看看我们是否能找到这些新颖预测的支持证据。
表4显示了Decagon的支持这些预测的预测和文献证据。我们能够找到10个排名最高的预测副作用中的5个的文献证据。也就是说,我们的方法都正确地识别了药物对以及这些排名最高的预测的副作用类型。 该结果是显着的,因为预测是特异性的,并且通过随机选择药物对和副作用关联不太可能找到支持性证据。我们注意到所引用的文献明确地研究了预测的药物对与预测的副作用之间的相互作用。例如,Decagon表示使用阿托伐他汀和氨氯地平可导致肌肉炎症(表4,排名第8位的预测)。事实上,最近的报道(例如Banakh等,2017)由于推测阿托伐他汀与氨氯地平的药物相互作用而在肌肉组织中发现了损伤。 Decagon还标志着乙胺嘧啶之间的潜在关联,如果单独服用,它可以有效地治疗疟疾,而阿利吉仑是一种肾素抑制剂,其临床试验在发现肾脏并发症后停止(Parving等,2012) ),表明癌症风险增加(排名第一的预测)。这里的分析证明了Decagon预测促进转化科学和发现新的(非) - 有效药物组合的潜力
6.3 探索Decagon的副作用嵌入
最后,我们有兴趣了解Decagon是否符合第3节中提出的设计目标。特别是,我们测试Decagon是否可以捕获我们的探索性数据分析揭示的不同副作用类型的相互依赖性(第3节中的第二次观察)。 为了达到这个目的,我们采用对角矩阵Dr,它专门模拟Decagon的多关系链接预测中每个副作用类型r的相互作用的重要性(第4.2节)。 我们从每个Dr中提取对角线并将其用作副作用r的矢量表示。 我们使用t-SNE将这些矢量表示嵌入到2D空间中(Maaten和Hinton,2008),然后在图4中可视化。
将药物用特征向量表示以后,查看这些特征向量的距离,是否能反映副作用的亲疏关系,颜色标记的这些副作用代表本来就容易共同发生的副作用
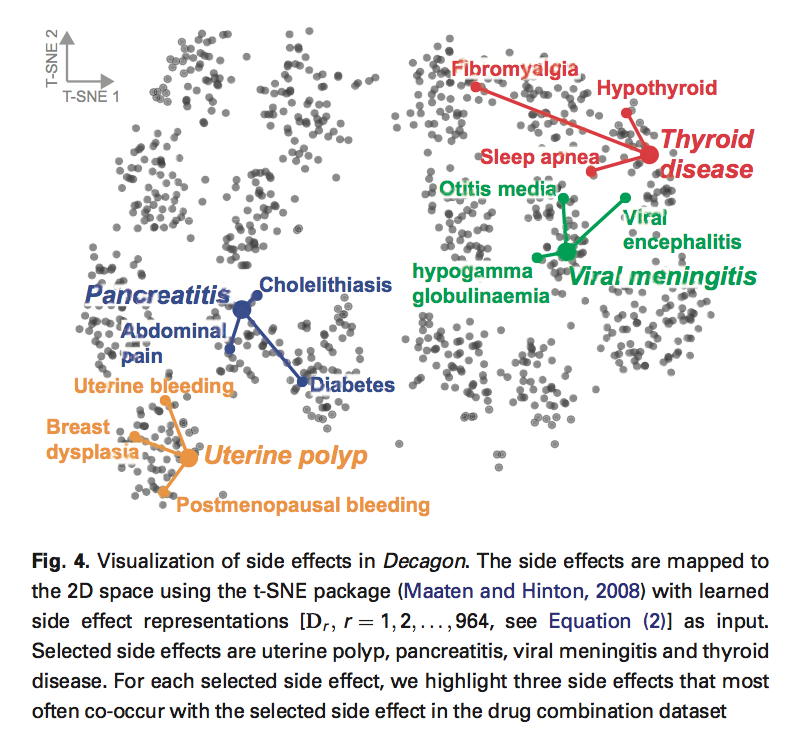
为了测试图4中的吸引人的模式是否适用于许多副作用类型,我们按如下方式进行。 我们计算每个副作用的矢量表示与三个最常见的共同副作用的矢量表示之间的平均欧几里德距离。 我们发现共同发生/相关的副作用具有比偶然预期的显着更相似的表示(即对角因子Dr)(P-value = 1e-34,2样本KS检验)。 因此,我们得出结论,Decagon能够满足多种药物副作用建模的设计目标。 此外,这里的分析表明Decagon的多关系链接预测模型(第4.2节)可以捕获药物组合数据中存在的副作用的相互依赖性。
七、相关工作
我们回顾了药物组合计算预测的相关研究,以及图形结构数据的神经网络。
7.1 药物组合模型
计算药理学的方法旨在找到药物和分子靶标之间的关联,预测潜在的药物不良反应并找到现有药物的新用途(Campillos et al., 2008;Hodos et al., 2016; Li et al., 2016)。与通过这些方法主要考虑的个体药物和单药物治疗(即单一疗法)相反,我们考虑药物组合(即多种药物)。这一点非常重要,因为多种药物治疗是一种治疗复杂疾病的有效策略(Han et al。,2017; Jia et al。,2009),对医疗保健系统具有重要意义(Ernst and Grizzle,2001)
传统上,已经通过实验筛选预定义药物组的所有可能组合来鉴定有效的药物组合(Chen等,2016b)。 鉴于药物数量众多,药物成对组合的实验筛选在成本和时间方面构成了巨大的挑战。 例如,给定n种药物,有n(n -1)/2成对药物组合和更多更高阶组合。 为了解决候选药物组合的组合爆炸,开发了计算方法来鉴定可能相互作用的药物对,即在没有相互作用的情况下产生超出预期的加性反应的夸大反应的药物对(Ryall和Tan,2015).此领域的先前研究侧重于通过协同作用和拮抗作用的概念来定义药物 - 药物相互作用(Lewis等,2015; Loewe,1953), 定量测量剂量 - 效应曲线(Bansal等,2014; Takeda等,2017),并根据测量细胞活力的实验确定给定的药物对是否相互作用(Chen et al。,2016a,b; Huang et al。 al。,2014a,b; Shi et al。,2017; Sun et al。,2015; Zitnik and Zupan,2016)。所有这些方法都将药物 - 药物相互作用预测为标量值,代表给定药物对的相互作用的总体概率/强度。 与此形成鲜明对比的是,我们的研究更进了一步,确定了一个给定的药物对究竟是如何在患者群体中临床表现的。 特别地,我们模拟临床表现,其不能归因于单独的药物和由于药物相互作用而产生的(即多药物副作用)。 以前的研究主要集中在产生代表细胞活力的点相互作用估计或实验药物筛选中的密切相关结果,我们首次预测,当患者将多种药物一起服用时,可能出现哪种多药副作用(如果有的话) ,为临床翻译提供更直接的途径
虽然目前的药物 - 药物相互作用预测方法不能直接用于此处研究的问题,但我们简要概述了这些方法所使用的方法。 药物 - 药物相互作用预测方法可以分为基于分类和基于相似性的方法。
-
基于分类的方法将药物 - 药物相互作用预测视为二元分类问题(Chen et al。,2016b; Cheng and Zhao,2014; Huang et al。,2014a; Shi et al。,2017; Zitnik and Zupan,2016)。这些方法使用已知的相互作用药物对作为正例和其他药物对作为反例训练分类模型,例如朴素贝叶斯,逻辑回归和支持向量机。
-
基于相似性的方法假设类似药物可能具有相似的相互作用模式(Gottlieb等,2012; Huang等,2014b; Li等,2016,2017; Sun等,2015; Vilar等。 。,2012; Zitnik和Zupan,2015)。这些方法使用不同类型的药物 - 药物相似性测量,其定义为药物化学亚结构,相互作用分布指纹,药物副作用,副作用和分子靶标的连接性。 该方法通过聚类或标记传播来聚合相似性测量,以便识别潜在的药物 - 药物相互作用(Ferdousi等,2017; Zhang等,2015,2017)。
然而,所有这些方法产生药物 - 药物相互作用评分,并不能预测确切的多种药物副作用,这是我们这里研究的目标。
7.2 基于图论的神经网络
我们的模型扩展了图论神经网络领域的现有工作(Defferrard等,2016; Gilmer等,2017; Hamilton等,2017a,b; Kipf和Welling,2016; Schlichtkrull等,2017)。图论神经网络通过将通常应用于图像数据集的卷积运算的概念概括为可以在任意图上运算的运算,使得能够学习图结构。这些神经网络也可以看作是一种嵌入方法,可以将关于每个节点邻域的高维信息提取到密集向量嵌入中,而无需手动特征工程。 特别是,图卷积网络(Defferrard等,2016; Hamilton等,2017a; Kipf和Welling,2016)和消息传递神经网络(Gilmer等,2017)是允许层的相关研究layer-wise地学习图中的节点嵌入。
尽管图形卷积网络在社交网络和知识图中的重要预测问题上实现了最先进的性能,但它们尚未用于计算生物学中的问题。 我们的模型通过结合对多个边缘类型的支持来扩展图形卷积网络,每种类型表示不同的副作用,并且通过为具有大量边缘类型的多模态图形提供有效的权重共享形式。
八、结论
我们提出了Decagon,一种预测药物副作用的方法。 Decagon是一种通用图卷积神经网络,设计用于在大型多模态图上运行,其中节点可以通过大量不同的关系类型连接。我们首次使用Decagon推断出能够识别药物副作用的预测模型。 Decagon预测副作用与共同处方药物对(即药物组合)之间的关联,以确定不能仅归因于任一种药物的副作用。 图形卷积模型在多种药物副作用预测任务中实现了极好的准确性,允许我们考虑将近千种不同的副作用类型整合到分子和患者群体数据中,并提供深入了解药物 - 药物相互作用的临床表现。
未来的研究有几个方向。 我们的方法将分子蛋白质-蛋白质和药物-靶标网络与人群水平患者的副作用数据结合在一起。但还有其他的一些事情可以做:
- 整合生物医学信息的其他来源,例如药物的剂量浓度水平,可能与药物对的副作用相关,我们希望研究将它们整合到模型中的效用。
- 该模型在其他领域的应用。由于Decagon的图卷积模型是任何多模态网络中多关系链接预测的一般方法,将其应用于其他领域和问题将是有趣的,例如,找到患者结果与合并疾病之间的关联,或识别基因-基因的相互作用与突变表型之间的依赖关系。
参考资料
《Modeling polypharmacy side effects with graph convolutional networks》
