【3.8.1】所有蛋白质都有一个基本的分子式(molecular formula)
本研究提出了所有蛋白质的基本分子式。随机选择了根据其功能分类的属于9个不同蛋白质组的10,739个蛋白质。它们包括酶,贮藏蛋白,激素,信号蛋白,结构蛋白,转运蛋白,免疫球蛋白或抗体,运动蛋白和受体蛋白。使用ProtParam工具获得蛋白质分子式后,针对每个随机选择的样品确定H / C,N / C,O / C和S / C比。在这种情况下,每个碳原子指定H,N,O和S系数。出乎意料的是,结果表明所有10,739种蛋白质的H,N,O和S系数相似且高度相关。这项研究表明,尽管结构和功能有所不同,但所有已知的蛋白质都具有相似的基本分子式CnH1.58±0.015nN0.28±0.005nO0.30±0.007nS0.01±0.002n。发现所有系数之间的总相关性是0.9999。
一、前言
蛋白质是参与生物体内许多重要生物学结构和功能的大分子。 结构蛋白的例子是韧带,指甲和头发。 功能蛋白的例子分别是可引起新陈代谢和运动的消化酶和肌肉蛋白。 蛋白质是由氨基酸单体构成的生物聚合物。 特定蛋白质的氨基酸序列由编码蛋白质的基因中的核酸碱基序列决定
组成氨基酸的化学性质决定了蛋白质的生物学活性(图1)[1]。蛋白质在生物系统中起着极其重要的作用[2]。单细胞微生物,植物,动物和人类中存在的蛋白质差异很大。氨基酸数量和序列的不同会导致蛋白质的独特形状,结构和功能。蛋白质是特定于任务和位置的,并且根据结构和功能大致分类。结构分类基于蛋白质折叠,基序和蛋白质家族信息。功能分类基于生化和细胞作用,代谢途径,亚细胞定位和分子相互作用。功能分类根据酶反应机理,参与生化途径,功能作用和细胞定位的相似性进一步细分[3]。尽管根据分子相似性的标准可能很好地定义了结构分类,但它们的重叠却受到了令人惊讶的限制。另一方面,功能分类涵盖许多过程和要素,范围从途径到细胞区室。这些功能分类已显示彼此相当重叠[4]。从功能上讲,蛋白质分为以下几类:酶(催化活细胞内部和外部发生化学和生化反应的蛋白质),储存蛋白(参与储存在代谢过程中释放的能量的蛋白质),激素(负责调节生物中的许多生化过程细胞内脂肪的蛋白质),信号蛋白(信号翻译过程中涉及的蛋白质),结构蛋白(这些蛋白质维持其他生物成分的结构,例如细胞和组织),转运蛋白(涉及转运或储存化学化合物和离子的蛋白质),免疫球蛋白或抗体(与生物体抵抗大的外来分子的免疫反应有关的蛋白质,例如通过感染引入),运动蛋白(与化学能转化为机械能的蛋白质有关)和受体蛋白质(负责信号检测和翻译成其他蛋白质的蛋白质)。这些分类的蛋白质中的每一种都具有自己的特定活性[5]。这项研究比较了氢,氮,氧和硫相对于蛋白质中碳原子数量的系数。使用数据提取工具从生物信息学数据库中获得了10,000多个随机蛋白质样品的数据。研究结果表明,单个基本分子式可用于描述所有蛋白质中元素的相对含量。
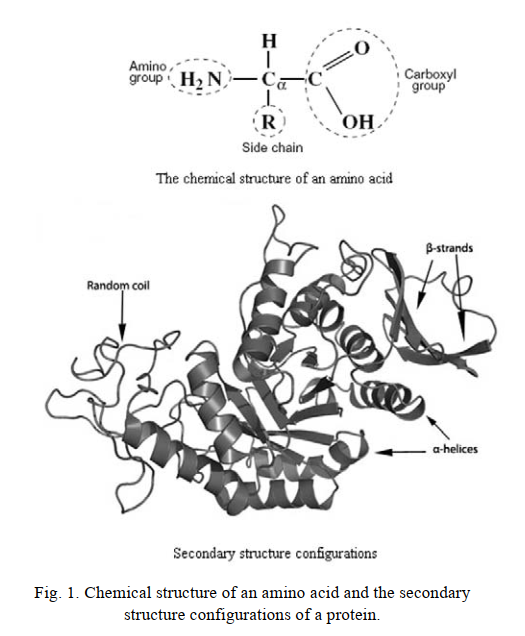
二、方法
2.1 A.蛋白质配方的数据库和定义。Databases and Definition of the Protein Formula
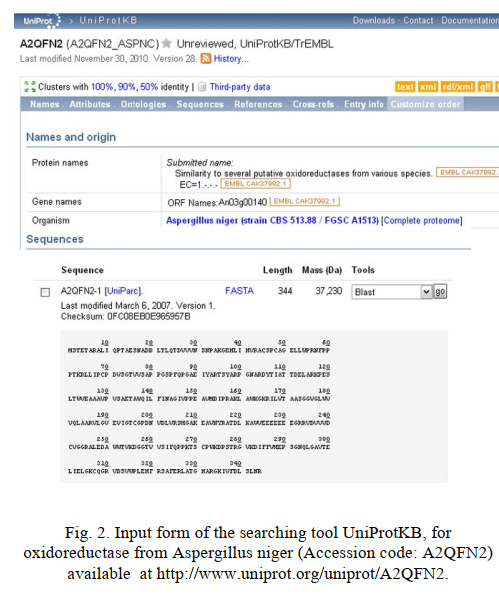
在这项研究中,使用生物信息学工具和数据库为每种蛋白质确定了蛋白质配方。首先获取氨基酸序列,然后将其输入可用的计算工具中,以进行此操作。这允许确定单个蛋白质的配方。所有分析均使用Expasy select作为UniProtKB(通用蛋白资源知识库数据库 http://www.expasy.org/sprot/ 和 http://www.expasy.org/tools 中一组实验确定的蛋白谱进行的)位于Expasy服务器中。例如,在氧化还原酶的情况下,随机选择的800种酶之一是黑曲霉(UniProt ID:A2QFN2)的氧化还原酶(图2)。该酶具有344个氨基酸,分子量为37,230道尔顿。首先,选择并复制酶的氨基酸序列。然后将序列粘贴到ProtParam工具的计算窗口中,以测定蛋白质配方(图3)。

在这项研究中,从9组蛋白质中随机选择了10,739种不同的蛋白质。 从每个蛋白质序列的N端开始,选择n个氨基酸的运行窗口。 然后将每种蛋白质的指定氨基酸序列复制并粘贴到ProtParam程序的计算窗口中。 最终,除了计算出所需蛋白质的图谱外,还确定了相关的分子式。 然后将氢,氮,氧和硫原子的总数除以碳原子的总数。 以这种方式,获得了碳,氢,氮,氧和硫的系数。 这些系数表示相对于碳原子数,蛋白质结构中的氢,氮,氧和硫原子数。 这提供了为每个蛋白质样品组装基本配方的能力。 表I是氧化还原酶的所得配方的实例。

三、结果
所得系数允许为每个选定的蛋白质提取基本公式。 最后,通过确定系数的平均值,获得每种蛋白质(例如酶)分类的基本单位公式。 结果显示在表中。

确定了表示碳,氢,氮,氧和硫含量的系数的平均值,列于表Ш中。 然后,计算每个原子的平均系数的总平均值。 如表ш中所示。 在此表中,系数之间的总相关性为0.9999
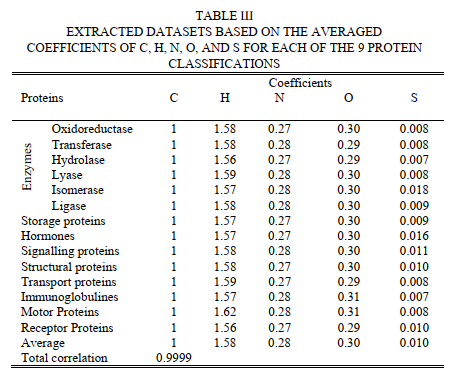
现在,可能想到的问题是,这些原子的系数之间的高度相似性是否可能是作为21种已知氨基酸(在所有蛋白质中均构成构件)的系数之间相似性的结果? 为了找到该问题的答案并评估预测的成功性,有必要将确定的蛋白质元素(H,N,O和S)系数与从单个氨基酸公式中获得的系数进行比较。 对单个氨基酸的分子式进行的计算表明,它们没有用单个基本式共同描述。 表IV提供了基于每种氨基酸的计算系数的分子式和基本式
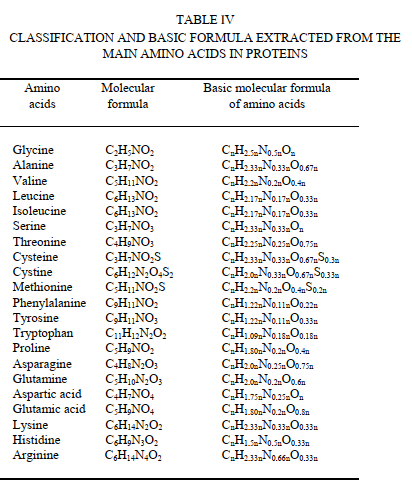
表V中所示的数字是从针对每种氨基酸的分子式中针对每个原子确定的系数获得的。 然后,指定每列的平均值,并计算每种氨基酸的所得系数之间的总相关性。 发现相关性为0.896,(表V)
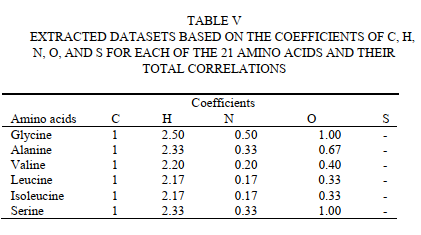
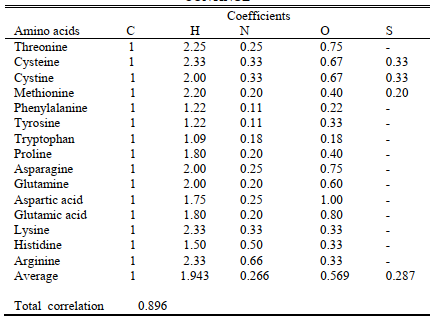
表VI显示了氨基酸平均系数的标准偏差和所有10,739种蛋白质的平均系数。
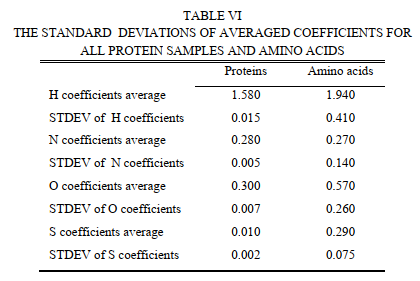
比较蛋白质和氨基酸系数的标准偏差,发现数据点趋向于非常接近均值,如方程式1、2、3和4所述。与蛋白质不同,氨基酸系数的这些值分布 在均值附近的更大范围内取值。

四、结论
作为前沿研究领域,生物信息学在过去的几十年中取得了长足的发展。这项研究利用生物信息学数据库和工具来指定蛋白质的基本分子式,该分子式表明了构成元素C,H,N,O和S的比例。该研究表明,尽管结构和功能有所不同,所有已知的蛋白质都是基于单个基本分子式构建的。据认为,通过从mRNA翻译来形成所有蛋白质是基于一种独特的模式,其中各贡献元素的系数彼此之间的比率保持恒定。据认为,所有蛋白质都是基于相似的基本分子式形成的。由于特定的氨基酸序列具有完全不同的结构和功能特性,因此基于特定遗传密码的核糖体在转录和rRNA特异性翻译方面存在着显着的多样性,从而可以生产蛋白质。这项调查的结果令人惊讶,因为尽管所有蛋白质的分子结构之间都具有极高的多样性,但对于每个1.0个碳原子,仍然有1.57-1.60个氢原子,0.28-0.29个氮原子,0.29-0.31个氧原子和0.01个碳原子。所有蛋白质中的硫原子。结果,最小和最大的蛋白质分子具有相同的基本分子式。指定的公式可以应用于科学研究的蛋白质模型预测任务。此外,另一个有趣的研究主题似乎是开发一种工具,该工具可设计用于治疗,药物和工业用途的新蛋白质和肽。这不是一个饱和的研究领域,正在进行进一步的研究。
参考资料
