【4.3.2.2】量化预测结果--分类变量--ROC曲线和AUC评价指标
ROC(Receiver Operating Characteristic)曲线和AUC常被用来评价一个二值分类器(binary classifier)的优劣。
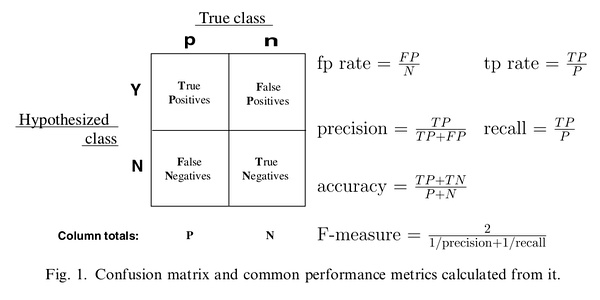
一、分类器评价指标
对于分类器,或者说分类算法,评价指标主要有precision,recall,F-score,ROC和AUC
查准率和查全率是信息检索效率评价的两个定量指标,不仅可以用来评价每次检索的准确性和全面性,也是在信息检索系统评价中衡量系统检索性能的重要方面。 查准率(Precision ratio,简称为P),是指检出的相关文献数占检出文献总数的百分比。查准率反映检索准确性,其补数就是误检率。 查全率(Recall ratio,简称为R),是指检出的相关文献数占系统中相关文献总数的百分比。查全率反映检索全面性,其补数就是漏检率。
查全率=(检索出的相关信息量/系统中的相关信息总量)*100%
查准率=(检索出的相关信息量/检索出的信息总量)*100%
前者是衡量检索系统和检索者检出相关信息的能力,后者是衡量检索系统和检索者拒绝非相关信息的能力。两者合起来,即表示检索效率。
二、ROC
ROC的全名叫做Receiver Operating Characteristic。ROC关注两个指标true positive rate (TPR= TP / [TP + FN] ) 和 false positive rate (FPR= FP / [FP + TN] ),直观上,TPR代表能将正例分对的概率,FPR代表将负例错分为正例的概率。在ROC 空间中,每个点的横坐标是FPR,纵坐标是TPR,这也就描绘了分类器在TP(真正的正例)和FP(错误的正例)间的trade-off。ROC的主要分析工具是一个画在ROC空间的曲线——ROC curve。我们知道,对于二值分类问题,实例的值往往是连续值,我们通过设定一个阈值,将实例分类到正类或者负类(比如大于阈值划分为正类)。因此我们可以变化阈值,根据不同的阈值进行分类,根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve。ROC curve经过(0,0)(1,1),实际上(0, 0)和(1, 1)连线形成的ROC curve实际上代表的是一个随机分类器。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方
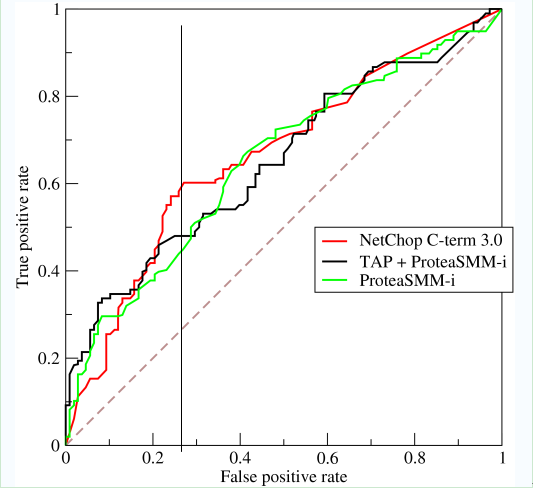
正如我们在这个ROC曲线的示例图中看到的那样,ROC曲线的横坐标为false positive rate(FPR),纵坐标为true positive rate(TPR)。下图中详细说明了FPR和TPR是如何定义的。
三、AUC
AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好
计算方式:略
四、AUC和其他方法的比较
Precision:P=TP/(TP+FP)
Recall:R=TP/(TP+FN)
F1-score:2/(1/P+1/R)
ROC/AUC:TPR=TP/(TP+FN), FPR=FP/(FP+TN)
AUC是ROC的积分(曲线下面积),是一个数值,一般认为越大越好,数值相对于曲线而言更容易当做调参的参照。
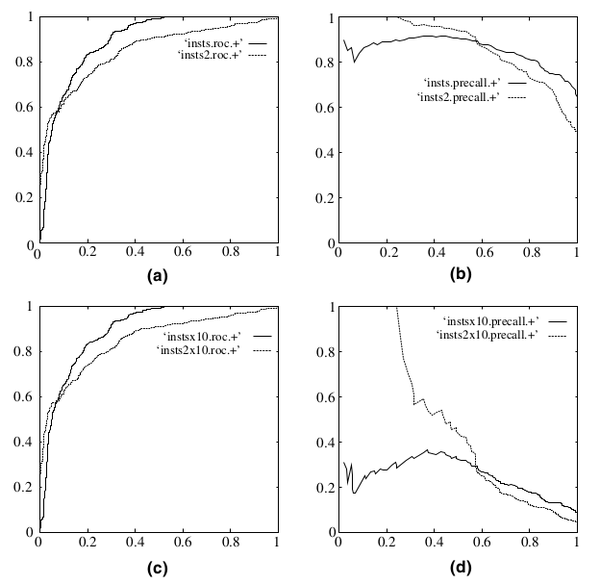
PR曲线会面临一个问题,当需要获得更高recall时,model需要输出更多的样本,precision可能会伴随出现下降/不变/升高,得到的曲线会出现浮动差异(出现锯齿),无法像ROC一样保证单调性。 real world data经常会面临class imbalance问题,即正负样本比例失衡。根据计算公式可以推知,在testing set出现imbalance时ROC曲线能保持不变,而PR则会出现大变化。引用图(Fawcett, 2006), (a)(c)为ROC,(b)(d)为PR,(a)(b)样本比例1:1,(c)(d)为1:10。
五、代码实现
from sklearn import metrics
import numpy as np
fpr1, tpr1, thresholds1 = metrics.roc_curve(np.array(raw_category), np.array(predict_scores1), pos_label=2)
auc1 = metrics.auc(fpr1, tpr1)
注: raw_category是一个2分类变量??
这是一个如何使用该roc_curve功能的小例子
>>> import numpy as np
>>> from sklearn.metrics import roc_curve
>>> y = np.array([1, 1, 2, 2])
>>> scores = np.array([0.1, 0.4, 0.35, 0.8])
>>> fpr, tpr, thresholds = roc_curve(y, scores, pos_label=2)
>>> fpr
array([ 0. , 0.5, 0.5, 1. ])
>>> tpr
array([ 0.5, 0.5, 1. , 1. ])
>>> thresholds
array([ 0.8 , 0.4 , 0.35, 0.1 ])
auc的计算:
>>> import numpy as np
>>> from sklearn.metrics import roc_auc_score
>>> y_true = np.array([0, 0, 1, 1])
>>> y_scores = np.array([0.1, 0.4, 0.35, 0.8])
>>> roc_auc_score(y_true, y_scores)
0.75
参考资料
