【2.4.1.4】tensorflow多GPU的实现(Horovod)-4
使用Horovod扩展到多个GPU
Horovod是一个分布式深度学习训练框架,它可用于TensorFlow,Keras,PyTorch和Apache MXNet。在本实验中,您将学习如何在多个GPU上训练一个模型,此模型是我们在实验1的练习3中使用的分类模型,从而了解Horovod是什么以及如何使用它。
实验大纲:
该实验的进度安排如下:
- 对Horovod的概括性的介绍,包括与并行计算协议MPI的联系,以及在使用诸如Horovod之类的并行计算框架时必须考虑的其他细节。
- 我们已有的模型是一个使用Keras和Fashion-MNIST数据集的分类模型,是为单GPU上运行而构建的。请回顾并运行已有的代码。我们将用Horovod对这个代码进行重写。
- 引入Horovod的概念和技术,对现有代码进行多步重构,使它可用Horovod在多个GPU上分布式运行。
- 运行经过重构的分布式代码,并讨论它带来的加速。
本实验主要借鉴Horovod教程中提供的内容。
学习目标:
在完成本练习时,您将能够:
- 了解Horovod是什么,它是如何工作的,以及为什么它是进行分布式训练的有效工具。
- 使用Horovod重构或构建深度学习模型,并在多个GPU上分布训练深度学习模型。
一、Horovod简介
Horovod是一种最初由Uber开发的开源工具,旨在满足他们许多工程团队对更快的深度学习模型训练的需求。它是分布式训练方法不断发展的生态系统的一部分,其中还包括Distributed TensorFlow。 Uber开发的这种解决方案利用MPI进行分布式进程间通信,并利用NVIDIA联合通信库(NCCL),以高度优化的方式实现跨分布式进程和节点的平均值计算。 由此产生的Horovod软件包实现了它的目标:仅需进行少量代码修改和直观的调试即可在多个GPU和多个节点上扩展深度学习模型的训练。
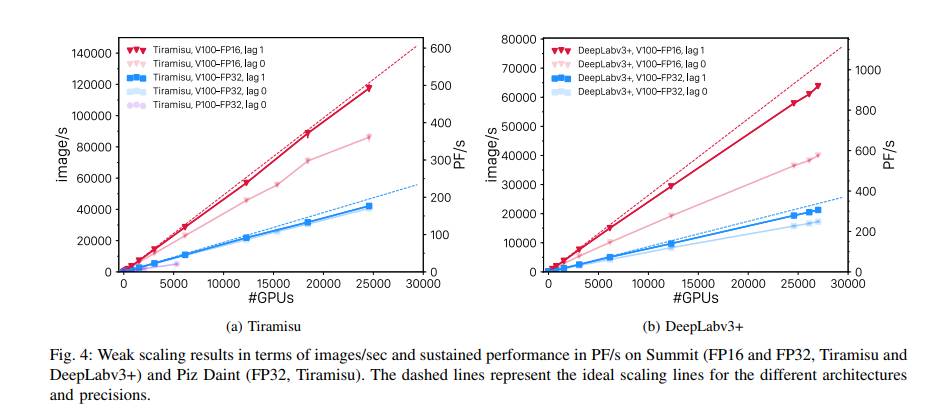
自2017年开始实施以来,Horovod已显著成熟,将其支持范围从TensorFlow扩展到了Keras,PyTorch和Apache MXNet。 Horovod经过了广泛的测试,迄今已用于一些最大的深度学习训练当中。例如,在Summit系统上支持 exascale 深度学习,可扩展到 27,000多个V100 GPU:
现在,我们导入Horovod库,以便稍后进行调用。通常做法是将其导入为hvd。
import horovod.tensorflow.keras as hvd
二、Horovod与MPI的渊源
Horovod与MPI具有非常深厚的联系。对于熟悉MPI编程的程序员来说,您对通过Horovod实现的分布式模型训练会感到非常熟悉。对于那些不熟悉MPI编程的人来说,简短地讨论一下Horovod或MPI分布式进程所需的一些约定和注意事项是值得的。
与MPI一样,Horovod严格遵循单程序多数据(SPMD)范例,即在同一文件或程序中实现多个进程的指令流。由于多个进程并行执行代码,因此我们必须注意竞争条件以及这些进程间的同步。
Horovod为执行程序的每个进程分配一个唯一的数字标识或rank(来自MPI的概念)。rank是可以通过编程的方式获得的。正如您在编写Horovod代码时将在下面看到的那样,通过以编程方式在代码中标识进程的rank,我们可以进一步采取以下步骤:
- 将该进程固定到自己的专属GPU上。
- 使用单个rank来广播需要所有ranks统一使用的值。
- 利用单个rank收集所有ranks产生的值和/或计算它们的均值。
- 利用一个rank来记录或写入磁盘。
在学习本课程时,请牢记这些概念,尤其是Horovod将您的单个程序发送给多个进程并行执行。牢记这一点将帮助您理解我们为什么要用Horovod进行的那些操作,即使您只对单个程序进行了编辑。
三、现有模型文件概述
在此实验环境的左侧,您将看到带有此笔记本的文件目录,几个Python文件和一个“ solutions”目录。
文件fashion_mnist.py包含没有任何Horovod代码的Keras模型,而solutions/fashion_mnist_solution.py已添加了所有Horovod功能。 在本教程中,我们将指导您一步一步将fashion_mnist.py转换为solutions/fashion_mnist_solution.py。 在完成此任务的过程中,如有必要,您可以将您的代码与solutions/fashion_mnist_after_step_N.py中对应的步骤进行比较。
fashion_mnist.py:
import argparse
import tensorflow as tf
from tensorflow.keras import backend as K
from tensorflow.keras.preprocessing import image
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.layers import Input, Conv2D, BatchNormalization, Dense, \
Add, Activation, Dropout, MaxPooling2D, GlobalAveragePooling2D
import numpy as np
import os
from time import time
# TODO: Step 1: import Horovod
# TODO: Step 1: initialize Horovod
# TODO: Step 1: pin to a GPU
# Parse input arguments
parser = argparse.ArgumentParser(description='Fashion MNIST Example',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--log-dir', default='./logs',
help='tensorboard log directory')
parser.add_argument('--batch-size', type=int, default=32,
help='input batch size for training')
parser.add_argument('--val-batch-size', type=int, default=32,
help='input batch size for validation')
parser.add_argument('--epochs', type=int, default=40,
help='number of epochs to train')
parser.add_argument('--base-lr', type=float, default=0.01,
help='learning rate for a single GPU')
parser.add_argument('--wd', type=float, default=0.000005,
help='weight decay')
parser.add_argument('--target-accuracy', type=float, default=.85,
help='Target accuracy to stop training')
parser.add_argument('--patience', type=float, default=2,
help='Number of epochs that meet target before stopping')
args = parser.parse_args()
# Define a function for a simple learning rate decay over time
def lr_schedule(epoch):
if epoch < 15:
return args.base_lr
if epoch < 25:
return 1e-1 * args.base_lr
if epoch < 35:
return 1e-2 * args.base_lr
return 1e-3 * args.base_lr
# Define the function that creates the model
def cbr(x, conv_size):
channel_axis = 1 if K.image_data_format() == 'channels_first' else -1
x = Conv2D(conv_size, (3,3), padding='same')(x)
x = BatchNormalization(axis=channel_axis)(x)
x = Activation('relu')(x)
return x
def conv_block(x, conv_size, scale_input = False):
x_0 = x
if scale_input:
x_0 = Conv2D(conv_size, (1, 1), activation='linear', padding='same')(x_0)
x = cbr(x, conv_size)
x = Dropout(0.01)(x)
x = cbr(x, conv_size)
x = Add()([x_0, x])
return x
def create_model():
# Implementation of WideResNet (depth = 16, width = 10) based on keras_contrib
# https://github.com/keras-team/keras-contrib/blob/master/keras_contrib/applications/wide_resnet.py
inputs = Input(shape=(28, 28, 1))
x = cbr(inputs, 16)
x = conv_block(x, 160, True)
x = conv_block(x, 160)
x = MaxPooling2D((2, 2))(x)
x = conv_block(x, 320, True)
x = conv_block(x, 320)
x = MaxPooling2D((2, 2))(x)
x = conv_block(x, 640, True)
x = conv_block(x, 640)
x = GlobalAveragePooling2D()(x)
outputs = Dense(num_classes, activation='softmax')(x)
model = tf.keras.models.Model(inputs, outputs)
opt = tf.keras.optimizers.SGD(lr=args.base_lr)
# TODO: Step 3: Wrap the optimizer in a Horovod distributed optimizer
model.compile(loss=tf.keras.losses.categorical_crossentropy,
optimizer=opt,
metrics=['accuracy'])
return model
# TODO: Step 2: only set `verbose` to `1` if this is the root worker.
# Otherwise, it should be zero.
verbose = 1
# Input image dimensions
img_rows, img_cols = 28, 28
num_classes = 10
# Load Fashion MNIST data.
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
# Convert class vectors to binary class matrices
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
# Training data iterator.
train_gen = image.ImageDataGenerator(featurewise_center=True, featurewise_std_normalization=True,
horizontal_flip=True, width_shift_range=0.2, height_shift_range=0.2)
train_gen.fit(x_train)
train_iter = train_gen.flow(x_train, y_train, batch_size=args.batch_size)
# Validation data iterator.
test_gen = image.ImageDataGenerator(featurewise_center=True, featurewise_std_normalization=True)
test_gen.mean = train_gen.mean
test_gen.std = train_gen.std
test_iter = test_gen.flow(x_test, y_test, batch_size=args.val_batch_size)
callbacks = []
callbacks.append(tf.keras.callbacks.LearningRateScheduler(lr_schedule))
# TODO: Step 4: broadcast initial variable states from the first worker to
# all others by adding the broadcast global variables callback.
# TODO: Step 6: average the metrics among workers at the end of every epoch
# by adding the metric average callback.
class PrintThroughput(tf.keras.callbacks.Callback):
def __init__(self, total_images=0):
self.total_images = total_images
def on_epoch_begin(self, epoch, logs=None):
self.epoch_start_time = time()
def on_epoch_end(self, epoch, logs={}):
epoch_time = time() - self.epoch_start_time
images_per_sec = round(self.total_images / epoch_time, 2)
print('Images/sec: {}'.format(images_per_sec))
if verbose:
callbacks.append(PrintThroughput(total_images=len(y_train)))
class StopAtAccuracy(tf.keras.callbacks.Callback):
def __init__(self, target=0.85, patience=2, verbose=0):
self.target = target
self.patience = patience
self.verbose = verbose
self.stopped_epoch = 0
self.met_target = 0
def on_epoch_end(self, epoch, logs=None):
if logs.get('val_accuracy') > self.target:
self.met_target += 1
else:
self.met_target = 0
if self.met_target >= self.patience:
self.stopped_epoch = epoch
self.model.stop_training = True
def on_train_end(self, logs=None):
if self.stopped_epoch > 0 and self.verbose == 1:
print('Early stopping after epoch {}'.format(self.stopped_epoch + 1))
callbacks.append(StopAtAccuracy(target=args.target_accuracy, patience=args.patience, verbose=verbose))
class PrintTotalTime(tf.keras.callbacks.Callback):
def on_train_begin(self, logs=None):
self.start_time = time()
def on_epoch_end(self, epoch, logs=None):
total_time = round(time() - self.start_time, 2)
print("Cumulative training time after epoch {}: {}".format(epoch + 1, total_time))
def on_train_end(self, logs=None):
total_time = round(time() - self.start_time, 2)
print("Cumulative training time: {}".format(total_time))
if verbose:
callbacks.append(PrintTotalTime())
# Create the model.
model = create_model()
# Train the model.
model.fit(train_iter,
# TODO: Step 5: keep the total number of steps the same despite of an increased number of workers
steps_per_epoch=len(train_iter),
callbacks=callbacks,
epochs=args.epochs,
verbose=verbose,
workers=4,
initial_epoch=0,
validation_data=test_iter,
# TODO: Step 5: set this value to be 3 * num_test_iterations / number_of_workers
validation_steps=len(test_iter))
# Evaluate the model on the full data set.
score = model.evaluate(test_iter, steps=len(test_iter), workers=4, verbose=verbose)
if verbose:
print('Test loss:', score[0])
print('Test accuracy:', score[1])
基准:训练模型
在进行扩展我们的WideResNet模型所需的修改之前,请确保您可以训练该模型的单GPU版本,它与我们在第一个实验结束时获得的模型相同,只不过现在我们使用的是完整的数据集。我们将以相对较大的批量大小运行几个训练周期,这将花费比以前更长的时间,因此在训练期间,您可以阅读后面的内容。请记录下来训练完成后花了多长时间。
!python fashion_mnist.py --epochs 5 --batch-size 512
四、 修改训练脚本
我们将开始对训练脚本进行修改。在进行此操作之前,让我们在磁盘上制作一个副本。这样,如果您犯了一个错误并想要从头开始,则需要参考副本。
!cp fashion_mnist.py fashion_mnist_original.py
双击左窗格中的fashion_mnist.py以在编辑器中将其打开。
4.1.初始化Horovod并选择要在其上运行的GPU
当然,我们需要从导入Horovod开始。
练习:将import horovod.tensorflow.keras as hvd添加到训练脚本中,并在参数解析之前初始化Horovod:
# Horovod:初始化Horovod。
hvd.init()
(查找TODO:Step 1行)。
使用Horovod,它可以在多个GPU上运行多个进程,因此通常每个训练进程使用一个GPU。Horovod易于使用的部分原因在于它利用了MPI,因此使用了许多MPI命名法。MPI中的rank概念指的是唯一的进程标识。在本实验中,我们将广泛使用术语“rank”。如果您想了解在Horovod中大量使用的MPI概念的更多信息,请参考Horovod文档。
在下面的示意图里,让我们看一下MPI如何在多个节点上运行多个GPU进程。 请注意每个进程或rank是如何固定到特定的GPU上的:

使用这种方法,我们不必处理将特定数据放置在特定GPU上的问题。 相反,您只需在脚本开头指定要使用的GPU。
在做这一步之前,让我们回顾一下如何在一个节点上使用多个GPU。在NVIDIA的CUDA平台上,如果我们有N个GPU,则它们的编号从0到N-1是唯一的。在本实验中,我们无需考虑如何选择编号或顺序是否重要。如果我们想将进程固定为使用特定的GPU(例如GPU 1),则可以使用以下TensorFlow代码:
# Pin to GPU 1
gpu_id = 1
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[gpu_id], True)
tf.config.experimental.set_visible_devices(gpus[gpu_id], 'GPU')
gpus列表包含CUDA允许TensorFlow进程能看到的所有GPU,默认情况下它将从中选择一个。如果想从这些GPU中选择多个来使用,您只需手工控制哪些设备(即GPU)将被使用,请参见TensorFlow的文档。 这种方式通常是当需要手动控制数据分发时会被使用,它的一个常见的用例是模型并行(这是Horovod 本身不支持的)。 在本实验中,每个rank我们只会使用一个GPU。(注意:set_memory_growth()调用告诉TensorFlow仅分配所需的内存,而不是预先分配完整的GPU内存。它与Horovod并不严格有联系,但通常建议这样做。)
现在,让我们测试一下您对该工作原理的理解。首先确定我们的节点上有多少个GPU:
!nvidia-smi
“!” 前缀意味着我们是在终端中执行上述操作的;现在让我们在实际的终端中执行此操作。打开一个新的启动器(菜单栏中的“文件”>“新启动器”),选择“终端”选项,在此处执行“nvidia-smi”命令,并验证它是否提供相同的输出。注意,有一个“GPU-Util”列,用于测量GPU的利用率。它告诉您使用GPU的最后一秒的百分比。 因此,我们可以通过定期检查此输出来轻松监视GPU活动。 一种实现方法是使用Linux实用程序watch:watch -n 5 nvidia-smi将建立一个循环,每5秒刷新nvidia-smi的输出。请确保在单独的终端窗口(而不是此处的notebook)中运行该程序,因为notebook一次只能运行一个进程。您可以在终端中键入Ctrl+C,以结束循环。
练习:如上所示设置nvidia-smi在终端中定期监视GPU的活动,然后在notebook中开始一个训练过程,再切换回终端并查看GPU活动。您能验证仅一个GPU正在被使用吗? 它是否与您在训练脚本中要求的GPU标识相匹配?另外,请注意其他利用率指标,例如功耗和内存使用率。
!mpirun -np 1 python fashion_mnist.py --epochs 1 --batch-size 512
现在,让我们修改上面的代码,以使Horovod可以针对任何数量的训练进程自动执行正确的操作。 通过编程,我们可以任意选择与Horovod rank相对应的GPU并使用该GPU。 由于我们可能使用多个节点,并且Horovod rank是训练进程中所有rank的唯一标识符,因此我们希望获得本地节点的rank标识,这由local_rank说明符提供:
# Horovod: pin GPU to be used to process local rank (one GPU per process)
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
tf.config.experimental.set_memory_growth(gpus[hvd.local_rank()], True)
tf.config.experimental.set_visible_devices(gpus[hvd.local_rank()], 'GPU')
查看有关下面两个功能的文档:
?hvd.rank
?hvd.local_rank
练习:掌握了这一知识后,请编辑fashion_mnist.py,以在初始化Horovod之后立即使用其本地rank ID将一个GPU固定到一个rank上。
同样地,在代码中查找TODO:Step 1行。 如果卡住了,请参考solutions/fashion_mnist_after_step_01.py。
练习:现在让我们测试一下您是否做正确了。下面只用一次epoch运行训练脚本,以确保一切都工作正常。我们将养成使用MPI作业启动器mpirun的习惯,尽管对于单个进程而言,这是不必要的。 在终端中使用nvidia-smi,验证仅一个训练进程正在运行,并注意使用了哪个GPU。是您期望的那个吗?
!mpirun -np 1 python fashion_mnist.py --epochs 1 --batch-size 512
mpirun可以启动训练脚本的N个副本,其中N是-np后面的参数,我们稍后将使用它来协调训练进程。 这些进程是在MPI环境中启动的,所以它们可以通过标准API在彼此之间进行通信,而Horovod为我们处理这一切,尽管我们尚未指示训练脚本实际开始协调。目前,我们将只启动同一个训练脚本的N个独立副本,即通过运行与GPU一样多的进程(ranks)来尝试这个过程。请观察输出,看看训练进程是否看起来很协调 – 训练正常进行吗? 是否所有进程都在您期望它们运行的GPU上运行,并且与nvidia-smi的输出匹配吗?
num_gpus = 4
!mpirun -np $num_gpus python fashion_mnist.py --epochs 1 --batch-size 512
4.2.仅在第一个worker进程上打印详细日志
您可能已经注意到,所有N个TensorFlow进程都将其进度打印到stdout(标准输出),这会导致输出混乱 – 我们只希望在任何给定时间查看一次输出状态。 为此,我们可以任意选择一个rank来显示训练进度。按照惯例,我们通常将rank 0称为 “根” rank,并仅用它处理诸如I/O之类的后勤工作。
练习:编辑fashion_mnist.py,以便仅当它是执行代码的第一个worker(rank等于0)时才设置verbose = 1。
在fashion_mnist.py中查找TODO: Step2。 如果卡住了,请参考solutions/fashion_mnist_after_step_02.py。
重新运行训练会话,以确保您现在看到了预期的输出。这次我们将运行3个epochs,以便与下一个练习进行比较。在运行期间,您可以开始执行步骤3。
!mpirun -np $num_gpus python fashion_mnist.py --epochs 3 --batch-size 512
4.3. 添加分布式优化器
Horovod执行一个对所有workers的梯度进行平均的操作。其实现是非常简单的,只需要将现有的优化器(tensorflow.keras.optimizers.Optimizer)用Horovod分布式优化器(horovod.tensorflow.keras.DistributedOptimizer)包装一下即可。
?hvd.DistributedOptimizer
练习:用Horovod分布式优化器包装现有的优化器(fashion_mnist.py中的opt)。
在fashion_mnist.py中查找TODO:Step 3。 如果卡住了,请参考solutions/fashion_mnist_after_step_03.py。
重新运行训练脚本,看看您是否获得合理的答案。精度变得更好了吗?请注意,我们仅训练了几个周期,其结果还将取决于初始随机权重,因此无需在此对结果做过度解读。
!mpirun -np $num_gpus python fashion_mnist.py --epochs 3 --batch-size 512
4.4. 仅在一个处理器上初始化随机权重
使用随机梯度下降法的数据并行,至少在其传统定义的顺序算法中,要求权重在所有处理器之间同步。我们已经知道,这可在实现反向传播时,先在权重更新之前对所有处理器之间的梯度求平均。接下来,唯一需要执行的其他步骤是使权重的初始值也同步。假设我们从训练的起点开始(即我们不会在本实验中处理检查点或重新启动,但是这是一个简单的扩展),这意味着每个处理器都需要具有相同的随机权重值。
在上一节中,我们提到了第一个worker进程将向其它进程广播权重参数。我们将使用horovod.tensorflow.keras.callbacks.BroadcastGlobalVariablesCallback来实现这一目标。请执行下面单元内的代码以获取有关该方法的更多信息:
?hvd.callbacks.BroadcastGlobalVariablesCallback
练习:将此回调函数附加到我们的回调函数列表中。请注意此回调函数所需的参数,即root worker的rank。
在fashion_mnist.py中查找TODO:Step 4。 如果卡住了,请参考solutions/fashion_mnist_after_step_04.py。
再次运行几次训练会话,以确保一切都正常工作,并注意最后的结果是否受到影响。
!mpirun -np $num_gpus python fashion_mnist.py --epochs 3 --batch-size 512
4.5.修改训练循环以在每个周期执行更少的步骤
就目前而言,我们为每个周期的训练执行相同数量的步数。但是,由于我们将worker数量增加了N倍,所以这意味着我们做的工作量是过去的N倍(当我们将所有进程中完成的工作量相加时)。我们的目标是在更短的时间内得到相同的答案(即加快训练速度),因此我们希望保持相同的总工作量(即处理相同数量的数据样本)。这意味着我们需要每个训练周期的训练步数减少为原来的N分之一,因此步数为steps_per_epoch / number_of_workers。
我们还将在每个worker上分布执行3 * num_test_iterations / number_of_workers个步数的验证。虽然我们可以在每个worker上执行num_test_iterations / number_of_workers步的验证,以线性地加快验证速度,但是乘数3会提供验证数据的多次采样,有助于提高每个验证样本都被评估的可能性。
?hvd.size
练习:遵循上述计划,修改model.fit里的steps_per_epoch和validation_steps参数。 此实验环境使用的是Python 3,并且每个参数都期望使用整数,因此请注意将任何潜在的浮点数舍入到最接近的整数。
在fashion_mnist.py中查找TODO:Step 5。 如果卡住了,请参考solutions/fashion_mnist_after_step_05.py。
!mpirun -np $num_gpus python fashion_mnist.py --epochs 3 --batch-size 512
4.6. workers之间的平均验证结果
由于我们在每个worker上所做的验证并非是在完整的数据集上,因此每个worker将具有不同的验证结果。为了提高验证指标的质量并减少差异,我们将对所有的workers的验证结果进行平均。
为此,我们可以使用horovod.tensorflow.keras.callbacks.MetricAverageCallback。 执行以下单元内的代码以获取更多信息:
?hvd.callbacks.MetricAverageCallback
练习:在每个训练周期结束时,通过在BroadcastGlobalVariablesCallback之后加入MetricAverageCallback来对所有workers的验证结果进行平均。 请注意,此回调函数在回调函数表里的位置必须先于其它需要使用验证指标的回调函数,比如ReduceLROnPlateau和TensorBoard,等等。
在fashion_mnist.py中查找TODO:Step 6。 如果卡住了,请参考solutions/fashion_mnist_after_step_06.py。
!mpirun -np $num_gpus python fashion_mnist.py --epochs 3 --batch-size 512
4.7. 与CPU比较
现在,您已经在多个GPU上实施了训练,让我们来看一个比较,如果仅在CPU上进行训练,您可以通过将’CUDA_VISIBLE_DEVICES’设置为空字符串来实现。您应该会看到很大的不同!
!CUDA_VISIBLE_DEVICES= python fashion_mnist.py --epochs 1 --batch-size 512
检查您的工作
祝贺!您已经取得这么大的进步了,现在您的fashion_mnist.py应该已经完全是分布式的了。如果要对此进行验证,请将fashion_mnist.py与solutions/fashion_mnist_solution.py进行比较。
fashion_mnist_solution.py
import argparse
import tensorflow as tf
from tensorflow.keras import backend as K
from tensorflow.keras.preprocessing import image
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.layers import Input, Conv2D, BatchNormalization, Dense, \
Add, Activation, Dropout, MaxPooling2D, GlobalAveragePooling2D
import numpy as np
import os
from time import time
# TODO: Step 1: import Horovod
import horovod.tensorflow.keras as hvd
# TODO: Step 1: initialize Horovod
hvd.init()
# TODO: Step 1: pin to a GPU
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
tf.config.experimental.set_memory_growth(gpus[hvd.local_rank()], True)
tf.config.experimental.set_visible_devices(gpus[hvd.local_rank()], 'GPU')
# Parse input arguments
parser = argparse.ArgumentParser(description='Fashion MNIST Example',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--log-dir', default='./logs',
help='tensorboard log directory')
parser.add_argument('--batch-size', type=int, default=32,
help='input batch size for training')
parser.add_argument('--val-batch-size', type=int, default=32,
help='input batch size for validation')
parser.add_argument('--epochs', type=int, default=40,
help='number of epochs to train')
parser.add_argument('--base-lr', type=float, default=0.01,
help='learning rate for a single GPU')
parser.add_argument('--wd', type=float, default=0.000005,
help='weight decay')
parser.add_argument('--target-accuracy', type=float, default=.85,
help='Target accuracy to stop training')
parser.add_argument('--patience', type=float, default=2,
help='Number of epochs that meet target before stopping')
args = parser.parse_args()
# Define a function for a simple learning rate decay over time
def lr_schedule(epoch):
if epoch < 15:
return args.base_lr
if epoch < 25:
return 1e-1 * args.base_lr
if epoch < 35:
return 1e-2 * args.base_lr
return 1e-3 * args.base_lr
# Define the function that creates the model
def cbr(x, conv_size):
channel_axis = 1 if K.image_data_format() == 'channels_first' else -1
x = Conv2D(conv_size, (3,3), padding='same')(x)
x = BatchNormalization(axis=channel_axis)(x)
x = Activation('relu')(x)
return x
def conv_block(x, conv_size, scale_input = False):
x_0 = x
if scale_input:
x_0 = Conv2D(conv_size, (1, 1), activation='linear', padding='same')(x_0)
x = cbr(x, conv_size)
x = Dropout(0.01)(x)
x = cbr(x, conv_size)
x = Add()([x_0, x])
return x
def create_model():
# Implementation of WideResNet (depth = 16, width = 10) based on keras_contrib
# https://github.com/keras-team/keras-contrib/blob/master/keras_contrib/applications/wide_resnet.py
inputs = Input(shape=(28, 28, 1))
x = cbr(inputs, 16)
x = conv_block(x, 160, True)
x = conv_block(x, 160)
x = MaxPooling2D((2, 2))(x)
x = conv_block(x, 320, True)
x = conv_block(x, 320)
x = MaxPooling2D((2, 2))(x)
x = conv_block(x, 640, True)
x = conv_block(x, 640)
x = GlobalAveragePooling2D()(x)
outputs = Dense(num_classes, activation='softmax')(x)
model = tf.keras.models.Model(inputs, outputs)
opt = tf.keras.optimizers.SGD(lr=args.base_lr)
# TODO: Step 3: Wrap the optimizer in a Horovod distributed optimizer
opt = hvd.DistributedOptimizer(opt)
model.compile(loss=tf.keras.losses.categorical_crossentropy,
optimizer=opt,
metrics=['accuracy'])
return model
# TODO: Step 2: only set `verbose` to `1` if this is the root worker.
# Otherwise, it should be zero.
if hvd.rank() == 0:
verbose = 1
else:
verbose = 0
# Input image dimensions
img_rows, img_cols = 28, 28
num_classes = 10
# Load Fashion MNIST data.
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
# Convert class vectors to binary class matrices
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
# Training data iterator.
train_gen = image.ImageDataGenerator(featurewise_center=True, featurewise_std_normalization=True,
horizontal_flip=True, width_shift_range=0.2, height_shift_range=0.2)
train_gen.fit(x_train)
train_iter = train_gen.flow(x_train, y_train, batch_size=args.batch_size)
# Validation data iterator.
test_gen = image.ImageDataGenerator(featurewise_center=True, featurewise_std_normalization=True)
test_gen.mean = train_gen.mean
test_gen.std = train_gen.std
test_iter = test_gen.flow(x_test, y_test, batch_size=args.val_batch_size)
callbacks = []
callbacks.append(tf.keras.callbacks.LearningRateScheduler(lr_schedule))
# TODO: Step 4: broadcast initial variable states from the first worker to
# all others by adding the broadcast global variables callback.
callbacks.append(hvd.callbacks.BroadcastGlobalVariablesCallback(0))
# TODO: Step 6: average the metrics among workers at the end of every epoch
# by adding the metric average callback.
callbacks.append(hvd.callbacks.MetricAverageCallback())
class PrintThroughput(tf.keras.callbacks.Callback):
def __init__(self, total_images=0):
self.total_images = total_images
def on_epoch_begin(self, epoch, logs=None):
self.epoch_start_time = time()
def on_epoch_end(self, epoch, logs={}):
epoch_time = time() - self.epoch_start_time
images_per_sec = round(self.total_images / epoch_time, 2)
print('Images/sec: {}'.format(images_per_sec))
if verbose:
callbacks.append(PrintThroughput(total_images=len(y_train)))
class StopAtAccuracy(tf.keras.callbacks.Callback):
def __init__(self, target=0.85, patience=2, verbose=0):
self.target = target
self.patience = patience
self.verbose = verbose
self.stopped_epoch = 0
self.met_target = 0
def on_epoch_end(self, epoch, logs=None):
if logs.get('val_accuracy') > self.target:
self.met_target += 1
else:
self.met_target = 0
if self.met_target >= self.patience:
self.stopped_epoch = epoch
self.model.stop_training = True
def on_train_end(self, logs=None):
if self.stopped_epoch > 0 and self.verbose == 1:
print('Early stopping after epoch {}'.format(self.stopped_epoch + 1))
callbacks.append(StopAtAccuracy(target=args.target_accuracy, patience=args.patience, verbose=verbose))
class PrintTotalTime(tf.keras.callbacks.Callback):
def on_train_begin(self, logs=None):
self.start_time = time()
def on_epoch_end(self, epoch, logs=None):
total_time = round(time() - self.start_time, 2)
print("Cumulative training time after epoch {}: {}".format(epoch + 1, total_time))
def on_train_end(self, logs=None):
total_time = round(time() - self.start_time, 2)
print("Cumulative training time: {}".format(total_time))
if verbose:
callbacks.append(PrintTotalTime())
# Create the model.
model = create_model()
# Train the model.
model.fit(train_iter,
# TODO: Step 5: keep the total number of steps the same despite of an increased number of workers
steps_per_epoch=len(train_iter) // hvd.size(),
callbacks=callbacks,
epochs=args.epochs,
verbose=verbose,
workers=4,
initial_epoch=0,
validation_data=test_iter,
# TODO: Step 5: set this value to be 3 * num_test_iterations / number_of_workers
validation_steps=3 * len(test_iter) // hvd.size())
# Evaluate the model on the full data set.
score = model.evaluate(test_iter, steps=len(test_iter), workers=4, verbose=verbose)
if verbose:
print('Test loss:', score[0])
print('Test accuracy:', score[1])
参考资料
- Nividia的课件《用多 GPU 训练神经网络》
