【6.5.2】tensorflow--多GPU并行
前两天,刚刚让tensorflow的程序跨节点运行,本来以为速度会有个线性增长,今天一看,原来我一个节点上就只用了一个GPU呀,尴尬。。。
多GPU并行可分为模型并行和数据并行两大类,下图展示的是数据并行,这也是我们经常用到的方法,而其中数据并行又可分为同步方式和异步方式两种,由于我们一般都会配置同样的显卡,因此这儿也选择了同步方式,也就是把数据分给不同的卡,等所有的GPU都计算完梯度后进行平均,最后再更新梯度。
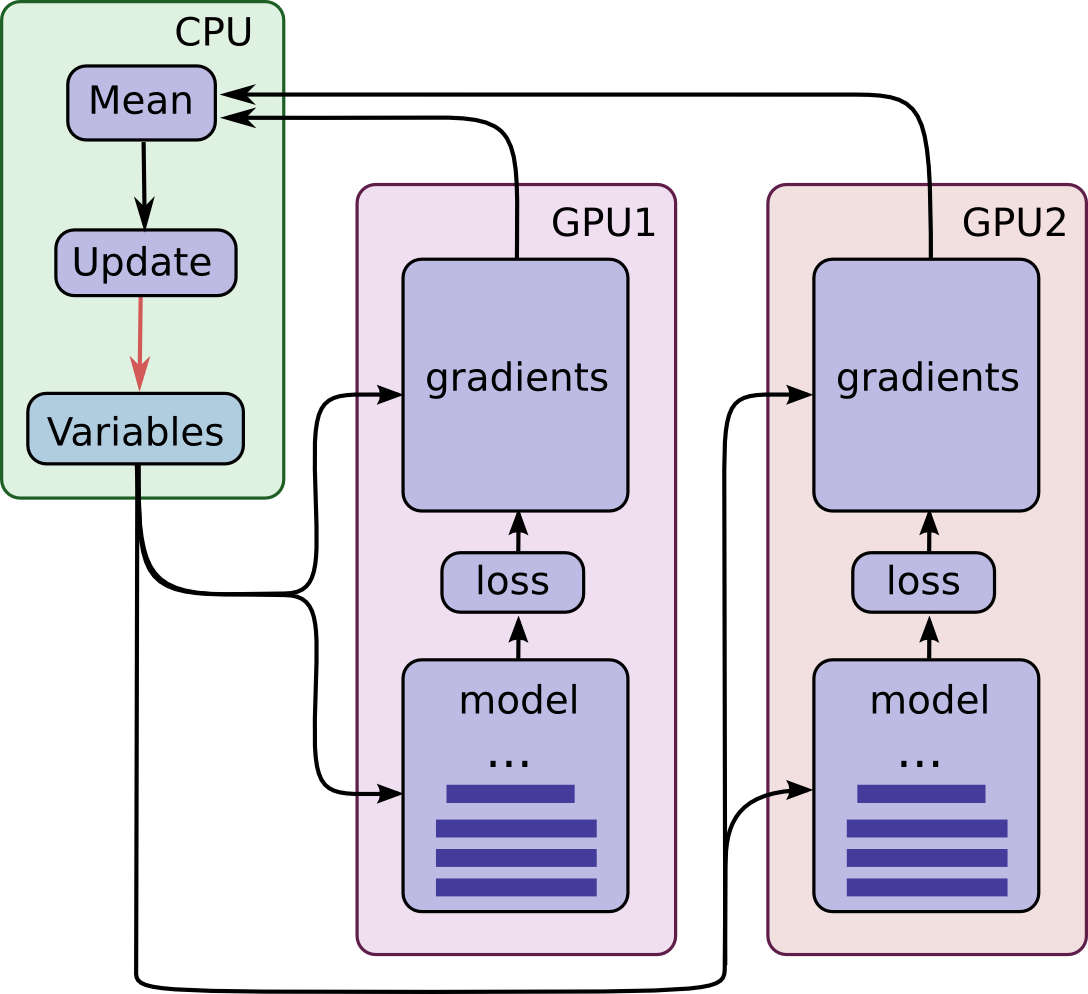
初步认知多个GPU的例子,见: https://gist.github.com/j-min/69aae99be6f6acfadf2073817c2f61b0
整个流程说白了就3个过程:
- 将数据分别分配到不同的GPU
- 不同的GPU分开求loss, 然后对这个Loss求平均值,更新梯度 (train_op)
- batch数据的时候,考虑GPU的个数
代码:
import tensorflow as tf
import numpy as np
from tensorflow.contrib import slim
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/mnist/", one_hot=True)
num_gpus = 2 # gpu个数
num_steps = 1000
learning_rate = 0.001
batch_size = 1000
display_step = 10
num_input = 784
num_classes = 10
def conv_net_with_layers(x,is_training,dropout = 0.75):
with tf.variable_scope("ConvNet", reuse=tf.AUTO_REUSE):
x = tf.reshape(x, [-1, 28, 28, 1])
x = tf.layers.conv2d(x, 12, 5, activation=tf.nn.relu)
x = tf.layers.max_pooling2d(x, 2, 2)
x = tf.layers.conv2d(x, 24, 3, activation=tf.nn.relu)
x = tf.layers.max_pooling2d(x, 2, 2)
x = tf.layers.flatten(x)
x = tf.layers.dense(x, 100)
x = tf.layers.dropout(x, rate=dropout, training=is_training)
out = tf.layers.dense(x, 10)
out = tf.nn.softmax(out) if not is_training else out
return out
def conv_net(x,is_training):
# "updates_collections": None is very import ,without will only get 0.10
batch_norm_params = {"is_training": is_training, "decay": 0.9, "updates_collections": None}
#,'variables_collections': [ tf.GraphKeys.TRAINABLE_VARIABLES ]
with slim.arg_scope([slim.conv2d, slim.fully_connected],
activation_fn=tf.nn.relu,
weights_initializer=tf.truncated_normal_initializer(mean=0.0, stddev=0.01),
weights_regularizer=slim.l2_regularizer(0.0005),
normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params):
with tf.variable_scope("ConvNet",reuse=tf.AUTO_REUSE):
x = tf.reshape(x, [-1, 28, 28, 1])
net = slim.conv2d(x, 6, [5,5], scope="conv_1")
net = slim.max_pool2d(net, [2, 2],scope="pool_1")
net = slim.conv2d(net, 12, [5,5], scope="conv_2")
net = slim.max_pool2d(net, [2, 2], scope="pool_2")
net = slim.flatten(net, scope="flatten")
net = slim.fully_connected(net, 100, scope="fc")
net = slim.dropout(net,is_training=is_training)
net = slim.fully_connected(net, num_classes, scope="prob", activation_fn=None,normalizer_fn=None)
return net
#tower_grads里面保存的形式是(第一个GPU上的梯度,第二个GPU上的梯度,...第N-1个GPU上的梯度),这里有一点需要注意的是zip(*),它的作用上把上面的那个列表转换成((grad0_gpu0, var0_gpu0), ... , (grad0_gpuN, var0_gpuN)) 的形式,也就是以列访问的方式,取到的就是某个变量在不同GPU上的值。
def average_gradients(tower_grads):
average_grads = []
for grad_and_vars in zip(*tower_grads):
grads = []
for g, _ in grad_and_vars:
expend_g = tf.expand_dims(g, 0)
grads.append(expend_g)
grad = tf.concat(grads, 0)
grad = tf.reduce_mean(grad, 0)
v = grad_and_vars[0][1]
grad_and_var = (grad, v)
average_grads.append(grad_and_var)
return average_grads
def train():
with tf.device("/cpu:0"):
global_step=tf.train.get_or_create_global_step()
tower_grads = []
X = tf.placeholder(tf.float32, [None, num_input])
Y = tf.placeholder(tf.float32, [None, num_classes])
opt = tf.train.AdamOptimizer(learning_rate) # 定义learning_rate
with tf.variable_scope(tf.get_variable_scope()): # 由于我们多个GPU上共享同样的图,为了防止名字混乱,最好使用name_scope进行区分,
for i in range(num_gpus):
with tf.device("/gpu:%d" % i):
with tf.name_scope("tower_%d" % i):
_x = X[i * batch_size:(i + 1) * batch_size] ## 将输入数据分别分配到不同gpu中
_y = Y[i * batch_size:(i + 1) * batch_size]
logits = conv_net(_x, True)
tf.get_variable_scope().reuse_variables() ##沿用已有的变量
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=_y, logits=logits)) ## 定义损失函数
grads = opt.compute_gradients(loss) #使用当前gpu计算所有变量的梯度
tower_grads.append(grads) # 我们需要有个列表tower_grads存储所有GPU上的梯度
if i == 0:
logits_test = conv_net(_x, False)
correct_prediction = tf.equal(tf.argmax(logits_test, 1), tf.argmax(_y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
grads = average_gradients(tower_grads) #计算变量的平均梯度
train_op = opt.apply_gradients(grads) # 最后就是更新梯度了
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(1, num_steps + 1):
batch_x, batch_y = mnist.train.next_batch(batch_size * num_gpus) # 注意,这里batch_size 乘以了num_gpus,因为输入的数据会被拆分到不同gpu中
sess.run(train_op, feed_dict={X: batch_x, Y: batch_y})
if step % 10 == 0 or step == 1:
loss_value, acc = sess.run([loss, accuracy], feed_dict={X: batch_x, Y: batch_y})
print("Step:" + str(step) + ":" + str(loss_value) + " " + str(acc))
print("Done")
print("Testing Accuracy:",
np.mean([sess.run(accuracy, feed_dict={X: mnist.test.images[i:i + batch_size],
Y: mnist.test.labels[i:i + batch_size]}) for i in
range(0, len(mnist.test.images), batch_size)]))
def train_single():
X = tf.placeholder(tf.float32, [None, num_input])
Y = tf.placeholder(tf.float32, [None, num_classes])
logits=conv_net(X,True)
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=Y,logits=logits))
opt=tf.train.AdamOptimizer(learning_rate)
train_op=opt.minimize(loss) #反向传播,调参数
logits_test=conv_net(X,False)
correct_prediction = tf.equal(tf.argmax(logits_test, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(1,num_steps+1):
batch_x, batch_y = mnist.train.next_batch(batch_size)
sess.run(train_op,feed_dict={X:batch_x,Y:batch_y})
if step%display_step==0 or step==1:
loss_value,acc=sess.run([loss,accuracy],feed_dict={X:batch_x,Y:batch_y})
print("Step:" + str(step) + ":" + str(loss_value) + " " + str(acc))
print("Done")
print("Testing Accuracy:",np.mean([sess.run(accuracy, feed_dict={X: mnist.test.images[i:i + batch_size],
Y: mnist.test.labels[i:i + batch_size]}) for i in
range(0, len(mnist.test.images), batch_size)]))
if __name__ == "__main__":
#train_single()
train()
二、讨论
1. 如何查看GPU是否被调用
nvidia-smi
参考资料
药企,独角兽,苏州。团队长期招人,感兴趣的都可以发邮件聊聊:tiehan@sina.cn
![]() 个人公众号,比较懒,很少更新,可以在上面提问题,如果回复不及时,可发邮件给我: tiehan@sina.cn
个人公众号,比较懒,很少更新,可以在上面提问题,如果回复不及时,可发邮件给我: tiehan@sina.cn
