【2.8】马氏距离(Mahalanobis Distance)
马氏距离(Mahalanobis distance)是由印度统计学家马哈拉诺比斯(P. C. Mahalanobis)提出的,表示点与一个分布之间的距离。它是一种有效的计算两个未知样本集的相似度的方法。与欧氏距离不同的是,它考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的),并且是尺度无关的(scale-invariant),即独立于测量尺度。(百科也很详细)
 生来清贫,没有头像,只留下一本书
生来清贫,没有头像,只留下一本书
马氏距离(Mahalanobis Distance)是度量学习中一种常用的距离指标,同欧氏距离、曼哈顿距离、汉明距离等一样被用作评定数据之间的相似度指标。但却可以应对高维线性分布的数据中各维度间非独立同分布的问题
一、引子
上图有两个正态分布的总体,它们的均值分别为a和b,但方差不一样,则图中的A点离哪个总体更近?或者说A有更大的概率属于谁?显然,A离左边的更近,A属于左边总体的概率更大,尽管A与a的欧式距离远一些。这就是马氏距离的直观解释。

二、概念
马氏距离是基于样本分布的一种距离。物理意义就是在规范化的主成分空间中的欧氏距离。所谓规范化的主成分空间就是利用主成分分析对一些数据进行主成分分解。再对所有主成分分解轴做归一化,形成新的坐标轴。由这些坐标轴张成的空间就是规范化的主成分空间。
简单来说就是,作为一种距离的度量,可以看作是欧氏距离的一种修正,修正了欧式距离中各个维度尺度不一致且相关的问题。
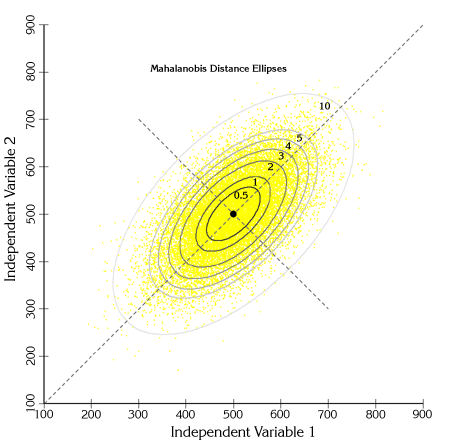
用来度量一个样本点P与数据分布为D的集合的距离。
假设样本点为:
$$ \underset{x}\rightarrow = (x_{1},x_{2},x_{3},...,x_{N})^{T} $$
数据集分布的均值为:
$$ \underset{μ}\rightarrow = (μ_{1},μ_{2},μ_{3},...,μ_{N})^{T} $$
协方差矩阵为S。
则这个样本点P与数据集合的马氏距离为:
$$ D_{M}{ (\underset{μ}\rightarrow) } = \sqrt{ (\underset{x}\rightarrow - \underset{μ}\rightarrow)^{T}S^{-1}(\underset{x}\rightarrow - \underset{μ}\rightarrow) } $$
马氏距离也可以衡量两个来自同一分布的样本x和y的相似性:
$$ d(\underset{x}\rightarrow ,\underset{y}\rightarrow ) = \sqrt{ (\underset{x}\rightarrow - \underset{y}\rightarrow)^{T}S^{-1}(\underset{x}\rightarrow - \underset{y}\rightarrow) } $$
当样本集合的协方差矩阵是单位矩阵时,即样本的各个维度上的方差均为1.马氏距离就等于欧式距离相等
当协方差矩阵是对角矩阵时,即样本数据在各个维度上的方差可能不为1.此时
$$ d(\underset{x}\rightarrow ,\underset{y}\rightarrow ) = \sqrt{ \sum \limits_{i=1}^{N} \frac{ (x_{i}-y_{i})^{2} }{s_{i}^{2}} } $$
可以看做是标准化了的欧氏距离。其中,si为样本数据在第i个维度上的标准差。
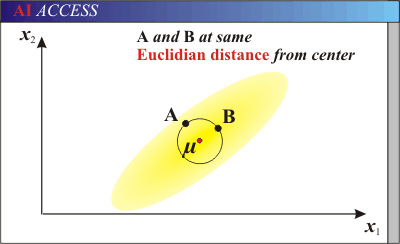
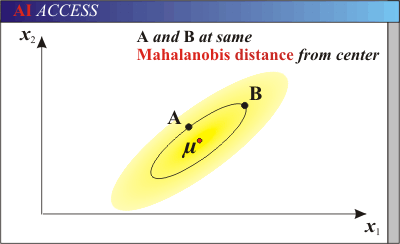
三、马氏距离的特点
- 量纲无关,排除变量之间的相关性的干扰;
- 想判断一个点是否属于一个集合,首先计算出这个集合的中心点(通过计算这个集合中所有样本的均值向量可以得到),然后求出这个点到中心点的距离,若大于一个阈值则认为不属于这个集合。但是这样有个问题,有的集合包含的范围比较大,待分类样本虽然离此集合中心点较其他集合的中心点远,但实际上属于这个集合,这就是尺度对分类结果的影响。为了消除这个影响,计算出集合中所有数据点到中心点的平均距离,这样,范围大的集合计算出来的平均距离就会较范围小的集合平均距离大,这个平均距离就是下式中的分母:标准差。
- 马氏距离的计算是建立在总体样本的基础上的,如果拿同样的两个样本,放入两个不同的总体中,最后计算得出的两个样本间的马氏距离通常是不相同的,除非这两个总体的协方差矩阵碰巧相同;
- 计算马氏距离过程中,要求总体样本数大于样本的维数,否则得到的总体样本协方差矩阵逆矩阵不存在,这种情况下,用欧式距离计算即可。
四、例子
如果我们以厘米为单位来测量人的身高,以克(g)为单位测量人的体重。每个人被表示为一个两维向量,如一个人身高173cm,体重50000g,表示为(173,50000),根据身高体重的信息来判断体型的相似程度。
我们已知小明(160,60000);小王(160,59000);小李(170,60000)。根据常识可以知道小明和小王体型相似。但是如果根据欧几里得距离来判断,小明和小王的距离要远远大于小明和小李之间的距离,即小明和小李体型相似。这是因为不同特征的度量标准之间存在差异而导致判断出错。
以克(g)为单位测量人的体重,数据分布比较分散,即方差大,而以厘米为单位来测量人的身高,数据分布就相对集中,方差小。马氏距离的目的就是把方差归一化,使得特征之间的关系更加符合实际情况。
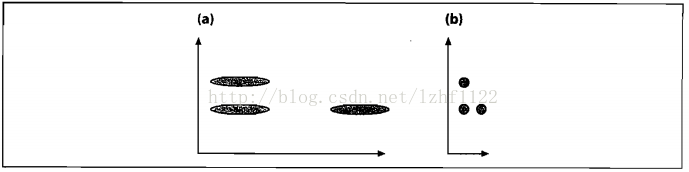
图(a)展示了三个数据集的初始分布,看起来竖直方向上的那两个集合比较接近。在我们根据数据的协方差归一化空间之后,如图(b),实际上水平方向上的两个集合比较接近。
五、讨论
马氏距离实际意义:
- 那么马氏距离就能能干什么?它比欧氏距离好在哪里?再炒几个栗子
- 欧式距离近就一定相似?
先举个比较常用的例子,身高和体重,这两个变量拥有不同的单位标准,也就是有不同的scale。比如身高用毫米计算,而体重用千克计算,显然差10mm的身高与差10kg的体重是完全不同的。但在普通的欧氏距离中,这将会算作相同的差距。
归一化后欧氏距离近就一定相似?
当然我们可以先做归一化来消除这种维度间scale不同的问题,但是样本分布也会影响分类
举个一维的栗子,现在有两个类别,统一单位,第一个类别均值为0,方差为0.1,第二个类别均值为5,方差为5。那么一个值为2的点属于第一类的概率大还是第二类的概率大?距离上说应该是第一类,但是直觉上显然是第二类,因为第一类不太可能到达2这个位置。
所以,在一个方差较小的维度下很小的差别就有可能成为离群点。就像下图一样,A与B相对于原点的距离是相同的。但是由于样本总体沿着横轴分布,所以B点更有可能是这个样本中的点,而A则更有可能是离群点。
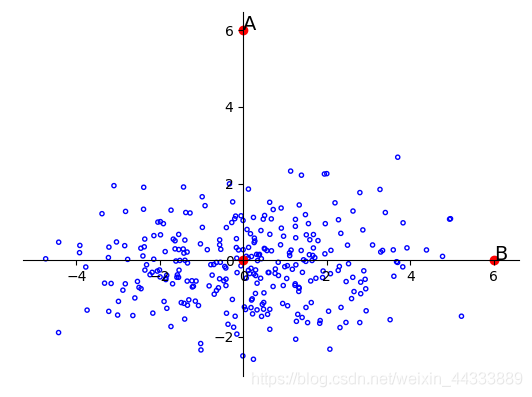
算上维度的方差就够了?
还有一个问题——如果维度间不独立同分布,样本点一定与欧氏距离近的样本点同类的概率更大吗

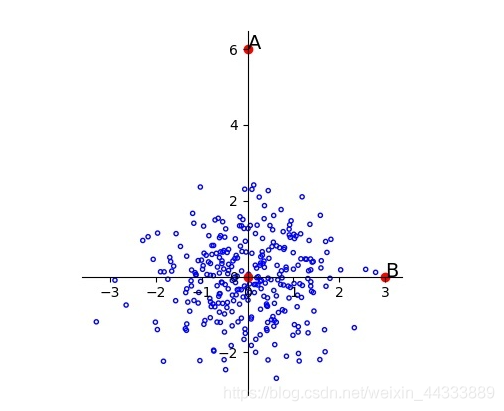
可以看到样本基本服从f(x) = x的线性分布,A与B相对于原点的距离依旧相等,显然A更像是一个离群点
即使数据已经经过了标准化,也不会改变AB与原点间距离大小的相互关系。所以要本质上解决这个问题,就要针对主成分分析(PCA)中的主成分来进行标准化。
马氏距离的几何意义
上面搞懂了,马氏距离就好理解了,只需要将变量按照主成分进行旋转,让维度间相互独立,然后进行标准化,让维度同分布就OK了。
由主成分分析可知,由于主成分就是特征向量方向,每个方向的方差就是对应的特征值,所以只需要按照特征向量的方向旋转,然后缩放特征值倍就可以了,可以得到以下的结果:
离群点就被成功分离,这时候的欧式距离就是马氏距离。(很妙啊!)
马氏距离的问题:
- 协方差矩阵必须满秩。 里面有求逆矩阵的过程,不满秩不行,要求数据要有原维度个特征值,如果没有可以考虑先进行PCA,这种情况下PCA不会损失信息
- 不能处理非线性流形(manifold)上的问题。只对线性空间有效,如果要处理流形,只能在局部定义,可以用来建立KNN图
参考资料
