【2.2.4】spearman correlation coefficient(斯皮尔曼相关性系数)
斯皮尔曼相关性系数,通常也叫斯皮尔曼秩相关系数。“秩”,可以理解成就是一种顺序或者排序,那么它就是根据原始数据的排序位置进行求解,这种表征形式就没有了求皮尔森相关性系数时那些限制。下面来看一下它的计算公式:
$$ \rho_{s} = 1- {\frac{6 \sum d _{i} ^{2}} {n (n^{2}-1) } } $$
计算过程就是:首先对两个变量(X, Y)的数据进行排序,然后记下排序以后的位置(X’, Y’),(X’, Y’)的值就称为秩次,秩次的差值就是上面公式中的di,n就是变量中数据的个数,最后带入公式就可求解结果。举个例子吧,假设我们实验的数据如下:
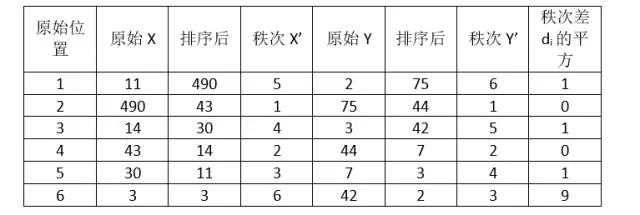
带入公式,求得斯皮尔曼相关性系数:
ρs= 1-6*(1+1+1+9)/6*35=0.657
也就是说,我们不用管X和Y这两个变量具体的值到底差了多少,只需要算一下它们每个值所处的排列位置的差值,就可以求出相关性系数了。这下理解起来是不是容易多了!还是用上面的数据,下面写下代码实现:
> X= c(11,490,14,43,30,3)
> Y = c(2,75,3,44,7,42)
> cor(X,Y,method='spearman')
[1] 0.6571429
给变量赋值:
而且,你发现了没?即便在变量值没有变化的情况下,也不会出现像皮尔森系数那样分母为0而无法计算的情况。另外,即使出现异常值,由于异常值的秩次通常不会有明显的变化(比如过大或者过小,那要么排第一,要么排最后),所以对斯皮尔曼相关性系数的影响也非常小!
由于斯皮尔曼相关性系数没有那些数据条件要求,适用的范围就广多了。在我们生物实验数据分析中,尤其是在分析多组学交叉的数据中说明不同组学数据之间的相关性时,使用的频率很高。下次童鞋们读文献的时候再看到“spearman correlation coefficient”,是不是会觉得亲切多啦!
参考资料:
药企,独角兽,苏州。团队长期招人,感兴趣的都可以发邮件聊聊:tiehan@sina.cn
![]() 个人公众号,比较懒,很少更新,可以在上面提问题,如果回复不及时,可发邮件给我: tiehan@sina.cn
个人公众号,比较懒,很少更新,可以在上面提问题,如果回复不及时,可发邮件给我: tiehan@sina.cn
