【1.5】误差
一、样本均数的抽样分布与抽样误差
1. 抽样误差和抽样分布
误差泛指实测值和真实值之差。按其产生原因与性质分两大类:系统误差和随机误差。抽样误差是一种随机误差。
抽样误差:
由于生物固有的个体变异,从某一总体中随机抽取一个样本,所得样本统计量与相应总体参数往往是有差异的,这种 差异称为抽样误差(sampling error)。
误差产生的原因
- 系统误差:由受试对象、研究者、仪器设备、研究方法等确定性原因造成,有倾向性,可避免。
- 随机误差:由多种无法控制的偶然因素引起的,无倾向性,不可 避免。
- 抽样误差:产生的根本原因是个体变异、产生的直接原因是抽 样。
抽样分布:
由于抽样误差存在,从同一总体中随机抽取若干份样本, 所得样本统计量是不一致的,差异无法避免但其存在一定 的分布规律
2. 样本均数抽样分布和抽样误差
正态分布总体样本均数抽样分布的电脑试验
假定某年某地所有13岁女生的身高服从总体均数为155.4 cm,总体标准差为5.3cm的正态分布
$$ N \left(155.4,5.3^{2}\right)$$
。用计算机从该总体中随机抽样,每次抽取30例组成一份样本,重复抽样100次,计算每份样本的平均身高。
电脑试验表明,正态分布总体样本均数抽样分布具有以 下特点:
- 样本均数恰好等于总体均数极其罕见;
- 样本均数之间存在差异;
- 样本均数围绕总体均数,中间多、两边少,左右基本对称,呈近似正态分布;
- 样本均数间的变异小于原始变量值间的变异(样本均数标准误小于原始变量的标准差)。
非正态分布总体样本均数抽样分布的电脑实验
图 (a) 是正偏峰分布原始数据对应的直方图,用计算机随机抽取样本量分别为5, 10, 30和50的样本各1000份,计算样本均数并绘制4个直方图。


中心极限定理表明
从正态总体
$$N\left(m,\sigma^2\right)$$
中随机抽取例数为 n 的多个样本,样本均数服从正态分布;即使是从偏态总体中随机抽样,当 n 足够大时(如 n>30),样本均数也近似正态分布,且样本均数的均数等于原分布的均数
均数抽样误差
由固然存在的个体变异和抽样造成的样本均数与样本均数及样本均数与总体均数之间的差异称为均数的抽样误差
样本均数的标准差
通常称为均数的标准差(standard error of mean, SEM或SE),可用于反映均数抽样误差的大小。
据数理统计学原理,若随机变量X均数为µ,方差为σ2,则样本眷属的标准差,即均数的标准差为:
$$\sigma_{\bar X} = {\frac{\sigma}{\sqrt{n}}} $$
又根据正态分布原理,若随机变量 X~N(µ, σ2),则样本均数
$$\bar X \sim N\left(\mu,\sigma_{\bar X}^2\right)$$
在实际应用中,总体标准差σ通常未知,需要用样本标准差S来估计标准差。此时,均数标准差的估计值为:
$$S_{\bar X} = {\frac{S}{\sqrt{n}}} $$
标准误的大小与原变量的标准差成正比,与样本含量的平方根成反比,因此,实际应用中可通过增加赝本含量来减小均数的标准误,从而降低抽样误差。
例题:
2000年某研究所随机调查某地健康成年男子27人,得到血红蛋白的均数为125g/L,标准差为15g/L。试估计该样本均数的抽样误差。
$$S_{\bar X} = {\frac{S}{\sqrt{n}}} ={\frac{15}{\sqrt{27}}} = 2.89g/L $$
二、样本频率的抽样分布与抽样误差
电脑摸球试验,探讨二项分布总体样本频率抽象样分布规律
口袋内有形状,质量完全啊相同的黑球和白球,已知黑球比例为20%(总体概率 π=20%)。有放回地摸球50次(ni=50),计算摸到黑球的百分比(样本频率p)。重复试验100次,绘制样本频率分布表。
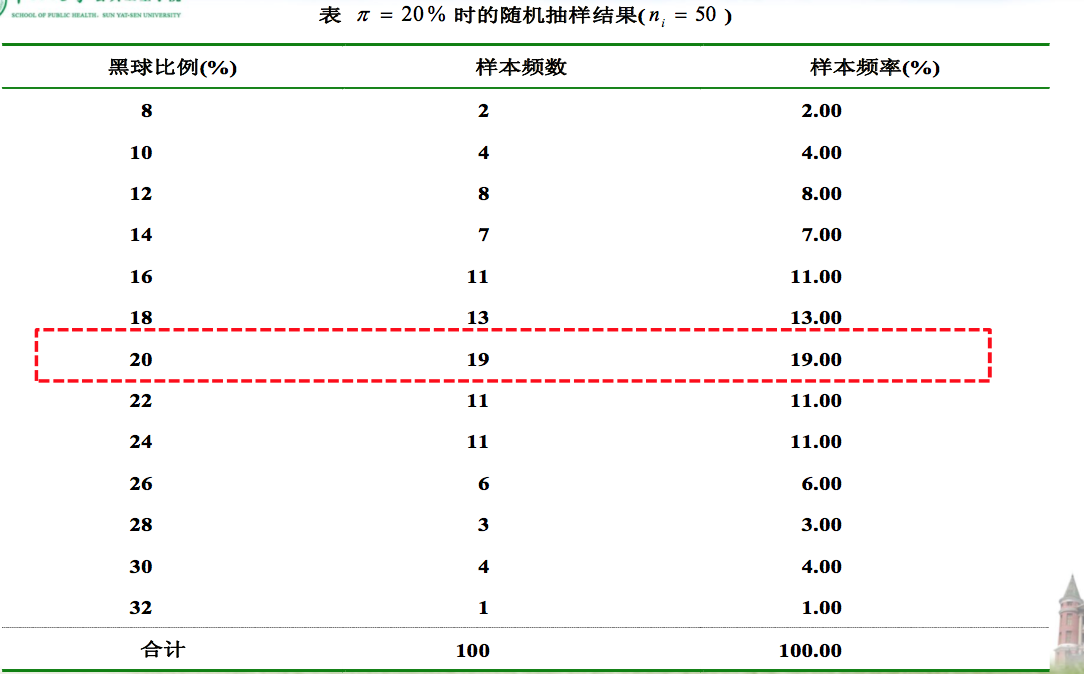
样本概率抽样误差
从同一总体中随机抽出观察单位相等的多个样本,样本率与总体率及各样本率之间都存在差异,称为频率的抽样误差。
样本概率的标准误
表示样本频率抽样误差大小的指标即为频率的标准误。
据二项分布原理,若随机变量 X ~B(n,π),则样本频率 p= X/n的总体概率为π,标准误为:
$$\sigma_{p} = {\sqrt{\frac{\pi\left(1-\pi\right)}{n}}}$$
频率的标准误越小,用样本频率评估总体概率的可靠性越好;反之。
在实际工作中,总体概率π一般都是未知的,常用样本频率 p = X/n来近似地替换,得到频率标准误的估计值
$$\sigma_{p} = {\sqrt{\frac{\pi\left(1-\pi\right)}{n}}}≈ {\sqrt{\frac{p\left(1-p\right)}{n}}}$$
频率的标准误与样本含量n的平方根成反比,增加样本含量可以减少样本频率的抽样误差。
例题:
某市随机调查了50岁以上的中老年妇女776人,其中患有骨质疏松症者322人,患病率为41.5%,试计算该样本频率的抽样误差。
$$\sigma_{p} = {\sqrt{\frac{\pi\left(1-\pi\right)}{n}}}={\sqrt{\frac{0.415\left(1-0.415\right)}{776}}} =0.0177 = 1.77\% $$
本例标准误的估计值较小,说明用样本患病率41.5%来估计总体患病率的可靠性较好。
参考资料
中山大学课程 《医学统计学》方积乾
