【3.3.4】Pandas--DataFrame的行索引和列索引的过渡(stack/unstack/pivot)
- stack()方法是针对索引或者标签的,即将列索引转成最内层的行索引
- pivot()针对列的值,即指定某列的值作为行索引,指定某列的值作为列索引,然后再指定哪些列作为索引对应的值
- unstack()是stack()的逆操作
一、原理说明
unstack(self, level=-1, fill_value=None)、pivot(self, index=None, columns=None, values=None,对比这两个方法的参数,这里要注意的是,对于pivot(),如果参数values指定了不止一列作为值的话,那么生成的DataFrame的列索引就会出现层次索引,最外层的索引为原来的列标签;unstack()没有指定值的参数,会把剩下的列都作为值,即把剩下的列标签都作为最外层的索引,每个索引对应一个子表。
pivot()方法其实比较容易理解,就是指定相应的列分别作为行、列索引以及值。下面我们通过几张原理图详细说明stack()和unstack(),最后再通过一个具体的例子来对比stack()、unstack()和pivot()这三种方法。
先看stack(),如图。stack()是将原来的列索引转成了最内层的行索引,这里是多层次索引,其中AB索引对应第三层,即最内层索引。

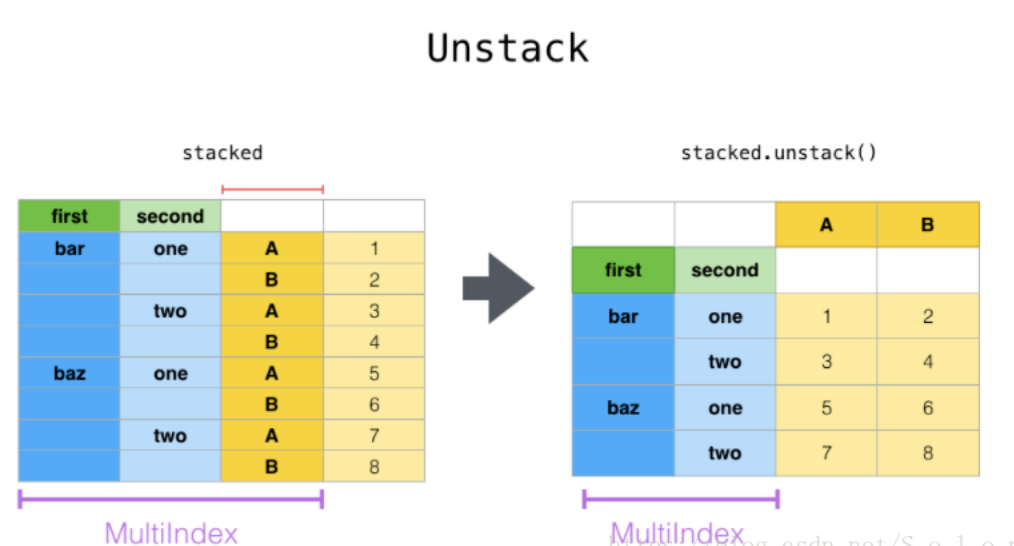
再看unstack(),如图。显然,unstack()是stack()的逆操作,这里把最内层的行索引还原成了列索引。但是unstack()中有一个参数可以指定旋转第几层索引,比如unstack(0)就是把第一层行索引转成列索引,但默认的是把最内层索引转层列索引。
二、具体例子
3.1 stack
DataFrame.stack(self, level=-1, dropna=True)[source]
说明:
- level : int, string, or list of these, default -1 (last level) Level(s) of index to unstack, can pass level name (从外到里 0,1,3,… n 或者是 -n,… -2,-1 。 默认是-1,即最里层)
- fill_value : replace NaN with this value if the stack produces missing values
例子
>>> df_single_level_cols = pd.DataFrame([[0, 1], [2, 3]],
... index=['cat', 'dog'],
... columns=['weight', 'height'])
Stacking a dataframe with a single level column axis returns a Series:
>>> df_single_level_cols
weight height
cat 0 1
dog 2 3
>>> df_single_level_cols.stack()
cat weight 0
height 1
dog weight 2
height 3
dtype: int64
Multi level columns: simple case
>>> multicol1 = pd.MultiIndex.from_tuples([('weight', 'kg'),
... ('weight', 'pounds')])
>>> df_multi_level_cols1 = pd.DataFrame([[1, 2], [2, 4]],
... index=['cat', 'dog'],
... columns=multicol1)
Stacking a dataframe with a multi-level column axis:
>>> df_multi_level_cols1
weight
kg pounds
cat 1 2
dog 2 4
>>> df_multi_level_cols1.stack()
weight
cat kg 1
pounds 2
dog kg 2
pounds 4
Missing values
>>> multicol2 = pd.MultiIndex.from_tuples([('weight', 'kg'),
... ('height', 'm')])
>>> df_multi_level_cols2 = pd.DataFrame([[1.0, 2.0], [3.0, 4.0]],
... index=['cat', 'dog'],
... columns=multicol2)
It is common to have missing values when stacking a dataframe with multi-level columns, as the stacked dataframe typically has more values than the original dataframe. Missing values are filled with NaNs:
>>> df_multi_level_cols2
weight height
kg m
cat 1.0 2.0
dog 3.0 4.0
>>> df_multi_level_cols2.stack()
height weight
cat kg NaN 1.0
m 2.0 NaN
dog kg NaN 3.0
m 4.0 NaN
Prescribing the level(s) to be stacked
The first parameter controls which level or levels are stacked:
>>> df_multi_level_cols2.stack(0)
kg m
cat height NaN 2.0
weight 1.0 NaN
dog height NaN 4.0
weight 3.0 NaN
>>> df_multi_level_cols2.stack([0, 1])
cat height m 2.0
weight kg 1.0
dog height m 4.0
weight kg 3.0
dtype: float64
Dropping missing values
>>> df_multi_level_cols3 = pd.DataFrame([[None, 1.0], [2.0, 3.0]],
... index=['cat', 'dog'],
... columns=multicol2)
Note that rows where all values are missing are dropped by default but this behaviour can be controlled via the dropna keyword parameter:
>>> df_multi_level_cols3
weight height
kg m
cat NaN 1.0
dog 2.0 3.0
>>> df_multi_level_cols3.stack(dropna=False)
height weight
cat kg NaN NaN
m 1.0 NaN
dog kg NaN 2.0
m 3.0 NaN
>>> df_multi_level_cols3.stack(dropna=True)
height weight
cat m 1.0 NaN
dog kg NaN 2.0
m 3.0 NaN
3.2 unstack
DataFrame.unstack(self, level=-1, fill_value=None)[source]
说明:
- level : int, string, or list of these, default -1 (last level) Level(s) of index to unstack, can pass level name (从外到里 0,1,3,… n 或者是 -n,… -2,-1 。 默认是-1,即最里层)
- fill_value : replace NaN with this value if the unstack produces missing values
例子:
>>> index = pd.MultiIndex.from_tuples([('one', 'a'), ('one', 'b'),
... ('two', 'a'), ('two', 'b')])
>>> s = pd.Series(np.arange(1.0, 5.0), index=index)
>>> s
one a 1.0
b 2.0
two a 3.0
b 4.0
dtype: float64
>>> s.unstack(level=-1)
a b
one 1.0 2.0
two 3.0 4.0
>>> s.unstack(level=0)
one two
a 1.0 3.0
b 2.0 4.0
>>> df = s.unstack(level=0)
>>> df.unstack()
one a 1.0
b 2.0
two a 3.0
b 4.0
dtype: float64
3.3 pivot
DataFrame.pivot(self, index=None, columns=None, values=None)[source]
例子:
>>> df = pd.DataFrame({'foo': ['one', 'one', 'one', 'two', 'two',
... 'two'],
... 'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
... 'baz': [1, 2, 3, 4, 5, 6],
... 'zoo': ['x', 'y', 'z', 'q', 'w', 't']})
>>> df
foo bar baz zoo
0 one A 1 x
1 one B 2 y
2 one C 3 z
3 two A 4 q
4 two B 5 w
5 two C 6 t
>>> df.pivot(index='foo', columns='bar', values='baz')
bar A B C
foo
one 1 2 3
two 4 5 6
>>> df.pivot(index='foo', columns='bar')['baz']
bar A B C
foo
one 1 2 3
two 4 5 6
>>> df.pivot(index='foo', columns='bar', values=['baz', 'zoo'])
baz zoo
bar A B C A B C
foo
one 1 2 3 x y z
two 4 5 6 q w t
A ValueError is raised if there are any duplicates.
>>> df = pd.DataFrame({"foo": ['one', 'one', 'two', 'two'],
... "bar": ['A', 'A', 'B', 'C'],
... "baz": [1, 2, 3, 4]})
>>> df
foo bar baz
0 one A 1
1 one A 2
2 two B 3
3 two C 4
Notice that the first two rows are the same for our index and columns arguments.
>>> df.pivot(index='foo', columns='bar', values='baz')
Traceback (most recent call last):
...
ValueError: Index contains duplicate entries, cannot reshape
参考资料
- https://blog.csdn.net/S_o_l_o_n/article/details/80917211
- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.unstack.html#pandas.DataFrame.unstack
- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.stack.html#pandas.DataFrame.stack
- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.pivot.html#pandas.DataFrame.pivot
