【3】数据分析-1-数据的处理--numpy--4--运算
一、NumPy一元函数
对ndarray中的数据执行元素级运算的函数
np.abs(x) np.fabs(x) 计算数组各元素的绝对值
np.sqrt(x) 计算数组各元素的平方根
np.square(x) 计算数组各元素的平方
np.log(x) np.log10(x) np.log2(x) 计算数组各元素的自然对数、10底对数和2底对数
np.ceil(x) np.floor(x) 计算数组各元素的ceiling值 或 floor值
np.rint(x) 计算数组各元素的四舍五入值
np.modf(x) 将数组各元素的小数和整数部分以两个独立数组形式返回
np.cos(x) np.cosh(x) np.sin(x) np.sinh(x) np.tan(x) np.tanh(x) 计算数组各元素的普通型和双曲型三角函数
np.exp(x) 计算数组各元素的指数值
np.sign(x) 计算数组各元素的符号值,1(+), 0, ‐1(‐)
二、NumPy二元函数
+ ‐ * / ** 两个数组各元素进行对应运算
np.maximum(x,y)
np.fmax()
np.minimum(x,y)
np.fmin() 元素级的最大值/最小值计
np.mod(x,y) 元素级的模运算
np.copysign(x,y) 将数组y中各元素值的符号赋值给数组x对应元素
> < >= <= == != 算术比较,产生布尔型数组
>>> a = array( [20,30,40,50] )
>>> b = arange( 4 )
>>> b
array([0, 1, 2, 3])
>>> c = a-b
>>> c
array([20, 29, 38, 47])
>>> b**2
array([0, 1, 4, 9])
>>> 10*sin(a)
array([ 9.12945251, -9.88031624, 7.4511316 , -2.62374854])
>>> a
*是元素的相乘,dot才是线性计算
>>> A = array( [[1,1],
... [0,1]] )
>>> B = array( [[2,0],
... [3,4]] )
>>> A*B # elementwise product
array([[2, 0],
[0, 4]])
>>> dot(A,B) # matrix product
array([[5, 4],
[3, 4]])
元素的加减
>>> a = ones((2,3), dtype=int)
>>> b = random.random((2,3))
>>> a *= 3
>>> a
array([[3, 3, 3],
[3, 3, 3]])
>>> b += a
>>> b
array([[ 3.69092703, 3.8324276 , 3.0114541 ],
[ 3.18679111, 3.3039349 , 3.37600289]])
>>> a += b # b is converted to integer type
>>> a
array([[6, 6, 6],
[6, 6, 6]])
不同数据类型的数组运算时,结果的数据类型默认的为更加精确的数据类型
>>> a = ones(3, dtype=int32)
>>> b = linspace(0,pi,3)
>>> b.dtype.name
'float64'
>>> c = a+b
>>> c
array([ 1. , 2.57079633, 4.14159265])
>>> c.dtype.name
'float64'
>>> d = exp(c*1j)
>>> d
array([ 0.54030231+0.84147098j, -0.84147098+0.54030231j,
-0.54030231-0.84147098j])
>>> d.dtype.name
'complex128'
求和是所有元素的和
>>> a = random.random((2,3))
>>> a
array([[ 0.6903007 , 0.39168346, 0.16524769],
[ 0.48819875, 0.77188505, 0.94792155]])
>>> a.sum()
3.4552372100521485
>>> a.min()
0.16524768654743593
>>> a.max()
0.9479215542670073
指定具体的某一个列或者行的统计
>>> b = arange(12).reshape(3,4)
>>> b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> b.sum(axis=0) # sum of each column
array([12, 15, 18, 21])
>>>
>>> b.min(axis=1) # min of each row
array([0, 4, 8])
>>>
>>> b.cumsum(axis=1) # cumulative sum along each row
array([[ 0, 1, 3, 6],
[ 4, 9, 15, 22],
[ 8, 17, 27, 38]])
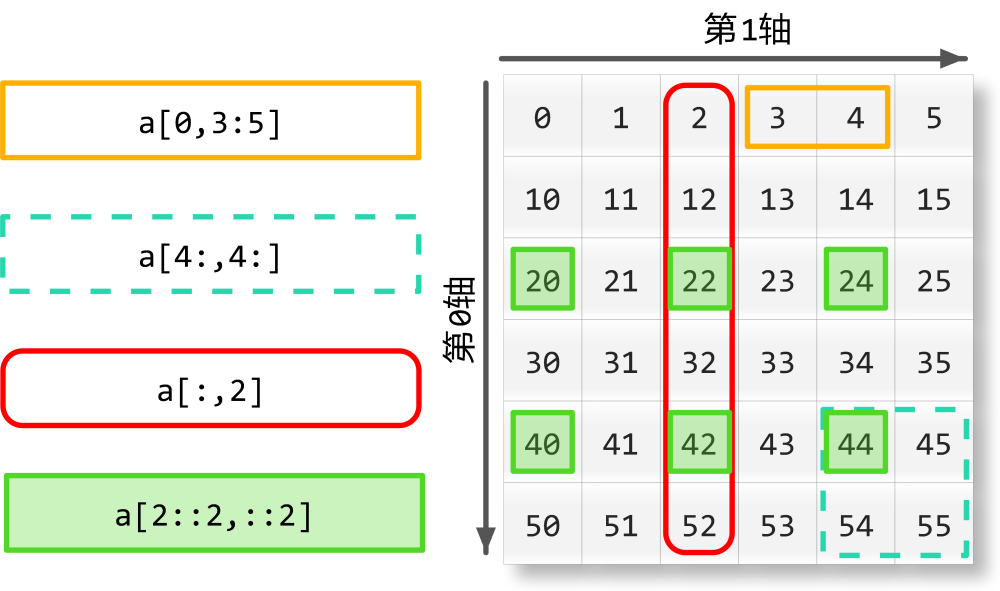
三、取整
1. round 和around
- numpy.ndarray.round
- numpy.around
示例:
>>> np.around([0.37, 1.64])
array([ 0., 2.])
>>> np.around([0.37, 1.64], decimals=1) # decimals指定小数点
array([ 0.4, 1.6])
>>> np.around([.5, 1.5, 2.5, 3.5, 4.5]) #如果是5,则出来的结果是偏向最近的偶数
array([ 0., 2., 2., 4., 4.])
>>> np.around([1,2,3,11], decimals=1) # ndarray of ints is returned
array([ 1, 2, 3, 11])
>>> np.around([1,2,3,11], decimals=-1)
array([ 0, 0, 0, 10])
四、其他 ( Miscellaneous )
4.1 nan_to_num
用0代替NaN,用最大的有限数代替无限数
例子:
1.7976931348623157e+308
>>> np.nan_to_num(-np.inf)
-1.7976931348623157e+308
>>> np.nan_to_num(np.nan)
0.0
>>> x = np.array([np.inf, -np.inf, np.nan, -128, 128])
>>> np.nan_to_num(x)
array([ 1.79769313e+308, -1.79769313e+308, 0.00000000e+000,
-1.28000000e+002, 1.28000000e+002])
>>> y = np.array([complex(np.inf, np.nan), np.nan, complex(np.nan, np.inf)])
>>> np.nan_to_num(y)
array([ 1.79769313e+308 +0.00000000e+000j,
0.00000000e+000 +0.00000000e+000j,
0.00000000e+000 +1.79769313e+308j])
4.2 计算分位数
import numpy as np
a=np.array(([1,2,3,4]))
np.median(a)#中位数
np.percentile(a,95) #95%分位数
df[df.a < np.percentile(df.a,95)]
参考资料
药企,独角兽,苏州。团队长期招人,感兴趣的都可以发邮件聊聊:tiehan@sina.cn
![]() 个人公众号,比较懒,很少更新,可以在上面提问题,如果回复不及时,可发邮件给我: tiehan@sina.cn
个人公众号,比较懒,很少更新,可以在上面提问题,如果回复不及时,可发邮件给我: tiehan@sina.cn
