【3】数据分析-7-科学计算--Scipy-3-sparse稀疏矩阵
稀疏矩阵是指矩阵中的元素大部分是0的矩阵,事实上,实际问题中大规模矩阵基本上都是稀疏矩阵,很多稀疏度在90%甚至99%以上。因此我们需要有高效的稀疏矩阵存储格式。本文总结几种典型的格式:COO,CSR,DIA,ELL,HYB。并用scipy包的sparse模块来实现数据的存储。
一、scipy.sparse简介
python中scipy模块中,有一个模块叫sparse模块,就是专门为了解决稀疏矩阵而生
导入sparse模块
>>> from scipy import sparse
然后help一把,先来看个大概
>>> help(sparse)
Usage information
=================
There are seven available sparse matrix types:
1. csc_matrix: Compressed Sparse Column format
2. csr_matrix: Compressed Sparse Row format
3. bsr_matrix: Block Sparse Row format
4. lil_matrix: List of Lists format
5. dok_matrix: Dictionary of Keys format
6. coo_matrix: COOrdinate format (aka IJV, triplet format)
7. dia_matrix: DIAgonal format
二、各种稀疏矩阵以及实现方法
2.1 coo_matrix
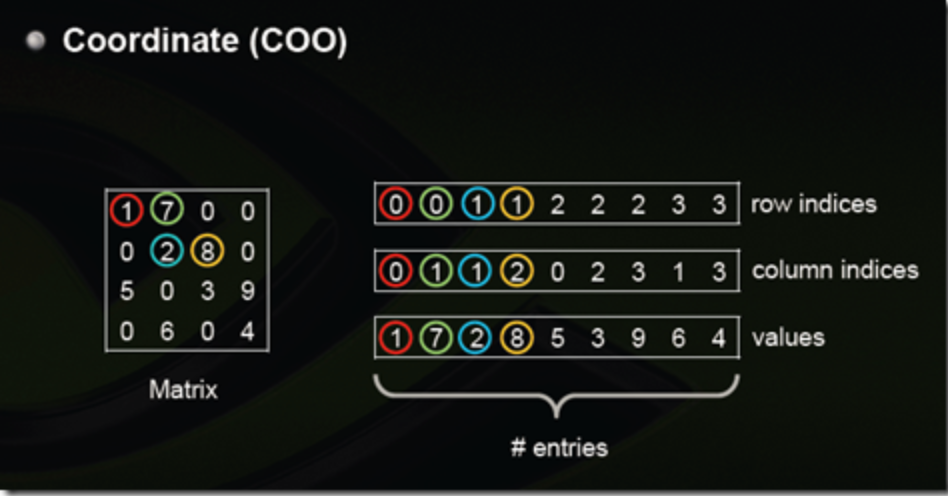
coo_matrix是最简单的存储方式。采用三个数组row、col和data保存非零元素的信息。这三个数组的长度相同,row保存元素的行,col保存元素的列,data保存元素的值。一般来说,coo_matrix主要用来创建矩阵,因为coo_matrix无法对矩阵的元素进行增删改等操作,一旦矩阵创建成功以后,会转化为其他形式的矩阵。
>>> row = [2,2,3,2]
>>> col = [3,4,2,3]
>>> c = sparse.coo_matrix((data,(row,col)),shape=(5,6))
>>> print c.toarray()
[[0 0 0 0 0 0]
[0 0 0 0 0 0]
[0 0 0 5 2 0]
[0 0 3 0 0 0]
[0 0 0 0 0 0]]
稍微需要注意的一点是,用coo_matrix创建矩阵的时候,相同的行列坐标可以出现多次。矩阵被真正创建完成以后,相应的坐标值会加起来得到最终的结果。
这是最简单的一种格式,每一个元素需要用一个三元组来表示,分别是(行号,列号,数值),对应上图右边的一列。这种方式简单,但是记录单信息多(行列),每个三元组自己可以定位,因此空间不是最优。
转换成coo矩阵:
scipy.sparse.csr_matrix.tocoo
csr_matrix.tocoo(copy=True)[source]
将矩阵转换成COOrdinate format.
如果copy=False, the data/indices may be shared between this matrix and the resultant coo_matrix.
判断是否为coo矩阵:
import scipy.sparse as sp
if not sp.isspmatrix_coo(sparse_mx):
sparse_mx = sparse_mx.tocoo()
属性
>>> # Constructing a matrix with duplicate indices
>>> row = np.array([0, 0, 1, 3, 1, 0, 0])
>>> col = np.array([0, 2, 1, 3, 1, 0, 0])
>>> data = np.array([1, 1, 1, 1, 1, 1, 1])
>>> coo = coo_matrix((data, (row, col)), shape=(4, 4))
>>> # Duplicate indices are maintained until implicitly or explicitly summed
>>> np.max(coo.data)
1
>>> coo.toarray()
array([[3, 0, 1, 0],
[0, 2, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 1]])
coo.data 代表上面的np.array([1, 1, 1, 1, 1, 1, 1])
coo.row 代表np.array([0, 0, 1, 3, 1, 0, 0])
coo.col 同里
2.2 dok_matrix与lil_matrix
dok_matrix和lil_matrix适用的场景是逐渐添加矩阵的元素。doc_matrix的策略是采用字典来记录矩阵中不为0的元素。自然,字典的key存的是记录元素的位置信息的元祖,value是记录元素的具体值。
>>> import numpy as np
>>> from scipy.sparse import dok_matrix
>>> S = dok_matrix((5, 5), dtype=np.float32)
>>> for i in range(5):
... for j in range(5):
... S[i, j] = i + j
...
>>> print S.toarray()
[[ 0. 1. 2. 3. 4.]
[ 1. 2. 3. 4. 5.]
[ 2. 3. 4. 5. 6.]
[ 3. 4. 5. 6. 7.]
[ 4. 5. 6. 7. 8.]]
lil_matrix则是使用两个列表存储非0元素。data保存每行中的非零元素,rows保存非零元素所在的列。这种格式也很适合逐个添加元素,并且能快速获取行相关的数据。
>>> from scipy.sparse import lil_matrix
>>> l = lil_matrix((6,5))
>>> l[2,3] = 1
>>> l[3,4] = 2
>>> l[3,2] = 3
>>> print l.toarray()
[[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 1. 0.]
[ 0. 0. 3. 0. 2.]
[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]]
>>> print l.data
[[] [] [1.0] [3.0, 2.0] [] []]
>>> print l.rows
[[] [] [3] [2, 4] [] []]
由上面的分析很容易可以看出,上面两种构建稀疏矩阵的方式,一般也是用来通过逐渐添加非零元素的方式来构建矩阵,然后转换成其他可以快速计算的矩阵存储方式。
2.3 Diagonal (DIA)

对角线存储法,按对角线方式存,列代表对角线,行代表行。省略全零的对角线。(从左下往右上开始:第一个对角线是零忽略,第二个对角线是5,6,第三个对角线是零忽略,第四个对角线是1,2,3,4,第五个对角线是7,8,9,第六第七个对角线忽略)。[3]
这里行对应行,所以5和6是分别在第三行第四行的,前面补上无效元素*。如果对角线中间有0,存的时候也需要补0,所以如果原始矩阵就是一个对角性很好的矩阵那压缩率会非常高,比如下图,但是如果是随机的那效率会非常糟糕。
2.4 csr_matrix与csc_matrix
csr_matrix,全名为Compressed Sparse Row,是按行对矩阵进行压缩的。CSR需要三类数据:数值,列号,以及行偏移量。CSR是一种编码的方式,其中,数值与列号的含义,与coo里是一致的。行偏移表示某一行的第一个元素在values里面的起始偏移位置。
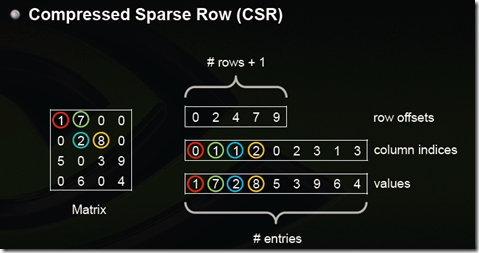
CSR是比较标准的一种,也需要三类数据来表达:数值,列号,以及行偏移。CSR不是三元组,而是整体的编码方式。数值和列号与COO一致,表示一个元素以及其列号,行偏移表示某一行的第一个元素在values里面的起始偏移位置。如上图中,第一行元素1是0偏移,第二行元素2是2偏移,第三行元素5是4偏移,第4行元素6是7偏移。在行偏移的最后补上矩阵总的元素个数,本例中是9。(说的有点绕了,其实呀,0代表0行有0个元素,2代表第一行和第二行一共有2个元素,即第二行的元素个数为2;4代表第一行,第二行的元素个数一共为4个,减去第一行,则第二行的个数为2,同理一次类推呀。。)
看看在python里怎么使用:
>>> from scipy.sparse import csr_matrix
>>> indptr = np.array([0, 2, 3, 6])
>>> indices = np.array([0, 2, 2, 0, 1, 2])
>>> data = np.array([1, 2, 3, 4, 5, 6])
>>> csr_matrix((data, indices, indptr), shape=(3, 3)).toarray()
array([[1, 0, 2],
[0, 0, 3],
[4, 5, 6]])
不难看出,csr_matrix比较适合用来做真正的矩阵运算。 至于csc_matrix,跟csr_matrix类似,只不过是基于列的方式压缩的,不再单独介绍。
例子:
1.形成1个3行4列,全都为0的矩阵
>>> import numpy as np
>>> from scipy.sparse import csr_matrix
>>> csr_matrix((3, 4), dtype=np.int8).toarray()
array([[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]], dtype=int8)
2.指定行和列的位置,然后指定对应的值
>>> row = np.array([0, 0, 1, 2, 2, 2])
>>> col = np.array([0, 2, 2, 0, 1, 2])
>>> data = np.array([1, 2, 3, 4, 5, 6])
>>> csr_matrix((data, (row, col)), shape=(3, 3)).toarray()
array([[1, 0, 2],
[0, 0, 3],
[4, 5, 6]])
3.indices代表数据对应的列的位置,indptr代表每行的元素个数累计之和(比如3代表对应第一行和第二行数据之和)
>>> indptr = np.array([0, 2, 3, 6])
>>> indices = np.array([0, 2, 2, 0, 1, 2])
>>> data = np.array([1, 2, 3, 4, 5, 6])
>>> csr_matrix((data, indices, indptr), shape=(3, 3)).toarray()
array([[1, 0, 2],
[0, 0, 3],
[4, 5, 6]])
4.构建csr压缩
>>> docs = [["hello", "world", "hello"], ["goodbye", "cruel", "world"]]
>>> indptr = [0]
>>> indices = []
>>> data = []
>>> vocabulary = {}
>>> for d in docs:
... for term in d:
... index = vocabulary.setdefault(term, len(vocabulary))
... indices.append(index)
... data.append(1)
... indptr.append(len(indices))
...
>>> csr_matrix((data, indices, indptr), dtype=int).toarray()
array([[2, 1, 0, 0],
[0, 1, 1, 1]])
一些属性
- nnz Number of stored values, including explicit zeros.
- has_sorted_indices Determine whether the matrix has sorted indices
- dtype (dtype) Data type of the matrix
- shape (2-tuple) Shape of the matrix
- ndim (int) Number of dimensions (this is always 2)
- data CSR format data array of the matrix
- indices CSR format index array of the matrix
- indptr CSR format index pointer array of the matrix
一些方法见:https://docs.scipy.org/doc/scipy-0.18.1/reference/generated/scipy.sparse.csr_matrix.html
2.5 bsr_matrix
Block Sparse Row format,顾名思义,是按分块的思想对矩阵进行压缩。
原矩阵A:
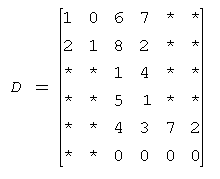
block_size为2时,分块表示的压缩矩阵E:
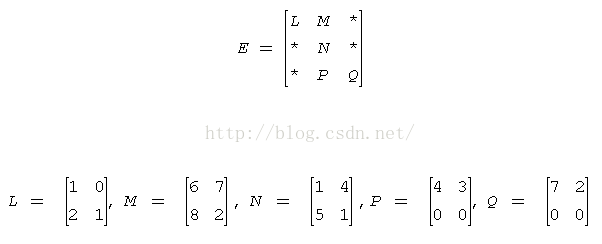
BSR的zero-based索引表示:
values = (1 02 1 6 7 8 2 1 4 5 1 4 3 0 0 7 2 0 0)
columns = (0 1 1 1 2)
pointerB= (0 2 3)
pointerE= (2 3 5)
分块压缩稀疏行格式(BSR) 通过四个数组确定:values,columns,pointerB, pointerE.
- 其中数组values:是一个实(复)数,包含原始矩阵A中的非0元,以行优先的形式保存;
- 数组columns:第i个整型元素代表块压缩矩阵E中第i列;
- 数组pointerB :第j个整型元素给出columns第j个非0块的起始位置;
- 数组pointerE:第j个整型元素给出columns数组中第j个非0块的终止位置
2.6 ELLPACK (ELL)
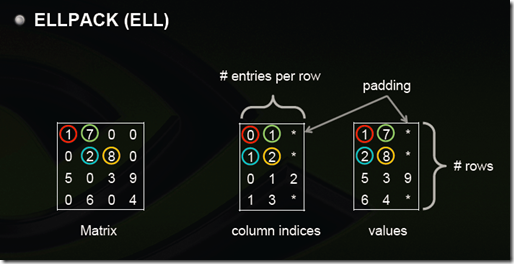
用两个和原始矩阵相同行数的矩阵来存:第一个矩阵存的是列号,第二个矩阵存的是数值,行号就不存了,用自身所在的行来表示;这两个矩阵每一行都是从头开始放,如果没有元素了就用个标志比如*结束。上图中间矩阵有误,第三行应该是 0 2 3。
注:这样如果某一行很多元素,那么后面两个矩阵就会很胖,其他行结尾*很多,浪费。可以存成数组,比如上面两个矩阵就是:
0 1 * 1 2 * 0 2 3 * 1 3 *
1 7 * 2 8 * 5 3 9 * 6 4 *
但是这样要取一行就比较不方便了
2.7. Hybrid (HYB) ELL + COO

为了解决ELL中提到的,如果某一行特别多,造成其他行的浪费,那么把这些多出来的元素(比如第三行的9,其他每一行最大都是2个元素)用COO单独存储。
三、压缩效率讨论
- DIA和ELL格式在进行稀疏矩阵-矢量乘积(sparse matrix-vector products)时效率最高,所以它们是应用迭代法(如共轭梯度法)解稀疏线性系统最快的格式;
- COO和CSR格式比起DIA和ELL来,更加灵活,易于操作;
- ELL的优点是快速,而COO优点是灵活,二者结合后的HYB格式是一种不错的稀疏矩阵表示格式;
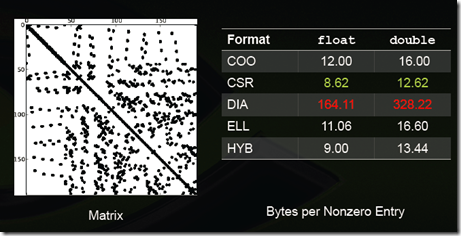
- 根据Nathan Bell的工作,CSR格式在存储稀疏矩阵时非零元素平均使用的字节数(Bytes per Nonzero Entry)最为稳定(float类型约为8.5,double类型约为12.5),而DIA格式存储数据的非零元素平均使用的字节数与矩阵类型有较大关系,适合于StructuredMesh结构的稀疏矩阵(float类型约为4.05,double类型约为8.10),对于Unstructured Mesh以及Random Matrix,DIA格式使用的字节数是CSR格式的十几倍;
- 从我使用过的一些线性代数计算库来说,COO格式常用于从文件中进行稀疏矩阵的读写,如matrix market即采用COO格式,而CSR格式常用于读入数据后进行稀疏矩阵计算。
一些特殊类型矩阵的存储效率(数值越小说明压缩率越高,即存储效率越高):
Structured Mesh

Unstructured Mesh
Random matrix

Power-Law Graph
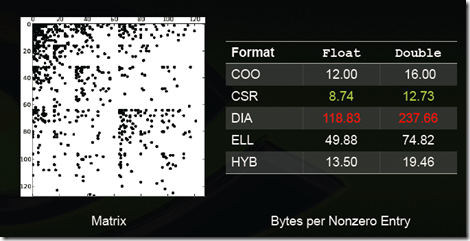
格式适用性总结:

四、稀疏矩阵操作
稀疏矩阵sparse matrix的保存和读取
from scipy import sparse
sparse.save_npz('./filename.npz', csr_matrix_variable) #保存
csr_matrix_variable = sparse.load_npz('path.npz') #读
提取csc矩阵非0的数对应的行与列
>>> from scipy.sparse import csr_matrix
>>> A = csr_matrix([[1,2,0],[0,0,3],[4,0,5]])
>>> A.nonzero()
(array([0, 0, 1, 2, 2]), array([0, 1, 2, 0, 2]))
参考资料
- https://www.cnblogs.com/xbinworld/p/4273506.html
- https://blog.csdn.net/bitcarmanlee/article/details/52668477
- https://blog.csdn.net/pipisorry/article/details/41762945
- https://docs.scipy.org/doc/scipy-0.18.1/reference/generated/scipy.sparse.csr_matrix.html
- https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csr_matrix.tocoo.html
